第2回、第3回では、音声データと、画像データに関するメディア認識技術について解説してきました。今回は、メディア認識技術に共通する課題である、機械学習の高速化について取り上げます。
まず、機械学習とは何かということから簡単に説明すると、ある程度大量のデータの中から規則性やパターンを見いだすことで、データの認識や判定などに役立てる取り組みのことを指します。例えば、皆さんが使用しているパソコンや情報システムの多くには、メールを受信したときに、ウイルスが含まれていないかどうか、スパムメールでないかどうか、判定するソフトウエアが入っていると思います。これも、過去の大量データに基づいて、ウイルスが入っていたり、スパムメールだったりする可能性が高いパターンを機械学習することで判定の仕組みを作り、そのロジックを活用しているのです。
そしてメディア処理システムには、音声、画像、テキストなどデータの種類を問わず、
- 大量のデータの中から代表的なものだけを見るために、類似したデータをまとめ上げる
- 対象データと類似したデータだけを抽出するために、大量のデータを自動識別する
など共通した処理が含まれています。こうした、データから有用なパターンを発見する処理に機械学習を役立てることができます。大規模データを扱うメディア処理システムを実現するため、高速な機械学習が求められています。
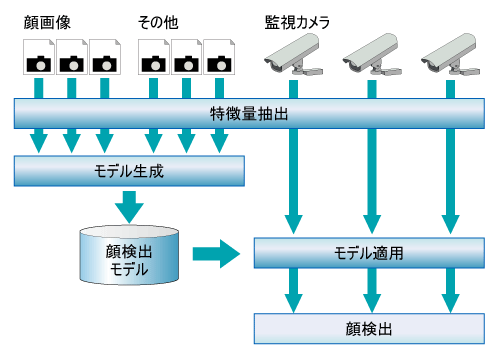
顔検出システム(図1)を例に、メディア処理における機械学習とその課題を説明しましょう。典型的なメディア処理システムは、
(2)モデル生成
(3)モデル適用
の3つのフェーズから成ります。順を追って説明します。
(1)特徴量抽出は、メディアデータを機械学習アルゴリズムが扱うことのできる形式に変換するフェーズです。画像の場合でいえば、その画像中である色を持つ領域の面積、周囲長、ある方向に引いた線の上にある黒色の総量といった数百~数千もの特徴量を抽出できます。(2)モデル生成は、機械学習のアルゴリズムを使い、多数の特徴量データから、類似性や規則性などのパターンを抽出し、モデルとして保存するフェーズです。(3)モデル適用は、機械学習で生成されたモデルを使って、未知のデータを処理するフェーズです。