利用者からの問い合わせを受け付けるコールセンター。毎日、多くの電話がかけられてくる。使い方の問い合わせから、返品や解約の申し込みなど様々だ。商品開発部門では「使い勝手について分析したい」というニーズがある一方で、マーケティング部門では「商品の解約に至る真の理由が知りたい」というニーズもある。
オペレーターは応対のログを記録して残しているが、多くの場合、通話ログには結果しか残されておらず、会話の詳細は録音音声にしか残っていない。大量の音声データから何とか有用な知見を得たい、とはいえ、多くの通話を聞きなおす時間もない――。
このケースのように、何らかの形で録音されている音声は近年増えている。例えば、国内コールセンター運営企業207社のうち88.9%に音声録音装置が導入されているという[1]。また、音声データを活用するための音声認識技術も成熟期を迎えており、コールセンターで今後導入予定のITソリューションとして期待されている[1]。しかし、コンプライアンスチェックやオペレーター教育などの分野を除き、冒頭に挙げたようなケース、すなわち二次活用の分野においては、音声ビッグデータの活用が期待ほど広がっていないのが現状である。
新しい商品名や言い回しへの対応が困難
なぜ、期待ほど広がっていないのであろうか?原因を考察してみよう。
非構造データの代表格である音声データに関しては、一般に、図1に記載したステップで分析が行われる。すなわち、録音された音声を、音声認識技術を用いてテキスト化し、テキスト化されたデータに対して、検索や分析を行うソリューションである。音声を完全にテキスト化できれば、テキストマイニングなどのツールを利用できる。
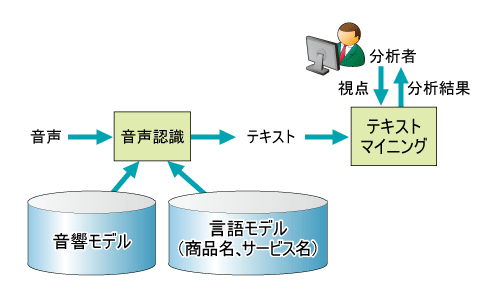
近年、音声認識技術は、業務用のミドルウェアからクラウドサービスまで様々な形態で提供されている。米アップル社のiPhoneに搭載されているSiriは、音声認識を最大限に利用したアプリケーションであり、音声入力によりデータベースへの問い合わせが可能となっている。Android携帯でも同様の機能があり、既にスマートフォンでは標準的なインターフェースの1つである。
音声認識は、基本的には、入力された音声が、データベースに蓄積されているパターンのうち、どのパターンに最も近いかを判定する「パターンマッチ」の技術である。HMM(Hidden Markov Model、隠れマルコフモデル)や、N-gram確率モデルと呼ばれるモデル(パターン)で音声を学習し、入力した音声に対して、統計的に最もスコアの高いパターンを出力するという手法が主流である。
前者のHMMは、「あ」や「か」という音が持つパターンを保持するモデルであり、「音響モデル」と呼ばれる。一方、後者のN-gram確率モデルは、単語と単語のつながりのパターンを保持するモデルであり、「言語モデル」と呼ばれる。音声認識システムの構築は、基本的には、この「音響モデル」と「言語モデル」を適切に設計する取り組みが必要となる(「学習」とも呼ばれる)。学習は、大量の音声データやテキストデータが必要となる。



















































