オープンソースの分散処理フレームワーク「Hadoop MapReduce」は、大容量データを迅速に処理したいケースで威力を発揮します。そのMapReduceをより使いやすくするためのツールが「Pig」と「Hive」です。今回は、Hiveを“体感”する方法を解説します。
前回は、大量のデータを高速に処理するための分散処理フレームワーク「Hadoop MapReduce」(以下、MapReduceと表記)を、簡単に扱えるようにするオープンソースソフトウエア(OSS)として「Pig」を紹介しました。今回登場する「Hive」は、米Facebook社で開発された、Hadoop上にデータウェアハウス(DWH)を構築するための基盤ソフトです。2008年12月に正式にHadoopプロジェクトに寄贈され、Pigと同様にHadoopを補完するサブプロジェクトの1つとして開発が進んでいます。
米Yahoo!社主催のHadoopユーザー向けイベント「Hadoop Summit 2010」によれば、Hiveを開発したFacebookでは、95%のMapReduceジョブを、Hiveプログラムで実行しているそうです。またインターネットラジオをベースにしたSNSとして有名な「Last FM」などのWebサービスを提供する企業の多くが、ログ解析やデータウエアハウス(DWH)などの用途にHiveを活用しています。
テーブルが扱えるHive

Hiveの特徴は、MapReduceの処理をリレーショナルデータベース(RDB)のテーブル操作のように実行できることです(図1)。Hiveの問い合わせ言語である「HiveQL」は、RDBの「SQL*」に似ています。Hiveで扱えるオペレータには、抽出の「SELECT」、結合の「JOIN」、グループ化の「GROUP」、そして集約の「UNION」があります。またテーブル定義では、表のようなコマンドが使えます。

HiveQLは第1回で紹介した「Pig Latin」よりもさらにSQL言語に似ており、SQLで可能な処理の多くを実行できます。このためRDBと似た操作手順で、Hadoopの特徴である汎用的なPCサーバーでの大規模データの集計や分析が可能です。実際、本記事の冒頭で事例として紹介したFacebookやLast FMは、自社でHiveを利用する理由として(1)SQLに慣れ親しんだ技術者にとって使い易い、(2)既存のRDB内のデータとの相性が良い、ということを挙げています。
HiveにはRDBに備わっている、不可分な一連の処理を保証する「トランザクション*」やテーブルを行レベルで更新するといった機能はありませんが、Hadoopならではの処理手順を新たに習得することなく手軽にDWHを構築できます。
第1~第2回のPigと今回のHiveはMapReduceの「ラッパー*」として動作するので、HDFSのファイルを共有できます。そのためPigでファイルの置換・変換処理をした後に、Hiveで集計するという使い方が可能です。
Hiveのインストール手順
RDBをお使いになった方であれば、「従来とほとんど同じ集計や分析を分散処理の環境上でできるのでは?」と思うのではないでしょうか。これからHiveを体感するための環境を整えていきましょう。
第1~第2回と同様に、Ubuntu 10.10をインストールしたテスト用マシンを1台用意し、Hadoopの実行環境を構築します(図2)。そのマシンにHiveをインストールしてHadoopを扱えるようにしたうえで、大容量のサンプルデータをHiveを使って集計処理してみます。
なお複数のマシンでHadoopクラスタを構成している場合でも、Pigと同様に全てのマシンにHiveをインストールする必要はありません。クライアントのいずれか1台にインストールするだけです。
今回利用するHadoopのバージョンは0.20.2、Hiveのバージョンは0.6.0を使用します。第1~第2回で利用した0.21.0は、Hiveを動作させるのにパッチが必要になります。0.20.2であればそのまま動作しますので、既に0.21.0を導入した方も、0.20.2をインストールしてください(後半の囲み記事)。「hadoop-0.20.2.tar.gz」と「hive-0.6.0-bin.tar.gz」を「http://hive.apache.org/」などからダウンロードしてください。また、以下の手順は「nikkei」ユーザーで作業することを前提にしていますので、自分のユーザー名に置き換えながら設定を進めましょう。
まず、Hiveのtarファイルをファイルシステムの適当な場所(ここでは/optとします)で解凍、展開します。
# sudo tar zxvf /opt/hive-0.6.0-bin.tar.gz -C /opt続いてバージョン管理をしやすくするために、解凍したHiveのディレクトリ(ここでは/opt/ hive-0.6.0-bin)にシンボリックリンクを張ります。
$ ln -s /opt/hive-0.6.0-bin /opt/hive次に、JavaやHiveのインストール先をHiveに伝える環境変数を設定します。ログイン時に自動実行される「.bashrc」と、Hiveの設定ファイルをそれぞれ編集しましょう。エディタとしてGNU nanoを使う場合は
$ sudo nano -w ~/.bashrc$ source ~/.bashrc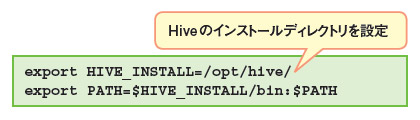
最後に、必要に応じてHiveが使うメモリー量を調節します。デフォルトでは4Gバイトを使用するので、4Gバイト未満の容量しかないテストマシンでは起動に失敗するためです。
$ sudo nano -w /opt/hive/bin/ext/util/execHiveCmd.shとして、33行目の「HADOOP_HEAPSIZE=4096」の値部分を変更します。例えば1Gバイトなら「HADOOP_HEAPSIZE=1024」に変更してください。
これでHiveを利用する準備は完了です。



















































