ビッグデータの活用で名前が挙がる企業は、国内外を問わず、Web系の企業が多い。海外であれば、米グーグル、米アマゾン、米フェイスブック。国内であれば、ヤフー、リクルート、楽天、クックパッド、あるいはグリー、ディー・エヌ・エー(DeNA)といったソーシャルゲーム会社だ。
Web系企業が多いのには、もちろん理由がある。まず、こうした業態ではクリック・ストリーム・データ(訪問者のアクセスログ)や検索ログ、購買履歴など、分析対象となるデータ取得が容易だ。また、HadoopやNoSQLデータベースなど、ビッグデータ処理に向くオープンソースソフトウエア(OSS)を高度に扱えるエンジニアを多く雇っていることも見逃せない。
そもそもWeb系企業は「ビッグデータ」という言葉がブームとなるはるか前から、ビッグデータの活用に真正面から取り組んできた。Hadoopの骨格となったMapReduceというフレームワークはグーグルが開発したものである。非構造化データを処理するためHadoopと組み合わせて使われることも多いDynamoやCassandraなどのNoSQLデータベースは、それぞれアマゾン、フェイスブックが開発したものだ。国内でも楽天がHadoopライクな分散処理フレームワーク「Fairly」や、分散キーバリュー・ストア「ROMA」を開発したように、海外と同様の動きが見られる。
リコメンドや画面個別化で楽天の好業績を支える
これは、Web系企業が事業を日々運営していくうえで、大量データへの対処は必要不可欠だからだ。HadoopやNoSQLデータベースがWeb系企業から生まれたのは、必然であったといえる。
例えば楽天の場合、主力の楽天市場に加えて、楽天トラベルや楽天ブックス、楽天銀行など、「楽天経済圏」と称する多彩なサービスを展開している。そして「楽天スーパーDB」を構築し、サービスごとに保持していた会員の購買履歴や商品閲覧履歴、属性、趣味や関心、ポイントといったデータを統合した。この統合DBを商品やサービスのリコメンデーションの高度化、各会員に表示する画面のパーソナライゼーションなどに活用してきた。
楽天市場にアクセスすると表示されるトップページはその一例だ。10以上の区画に分けられたトップページの各区画の内容は、楽天グループが抱える約7500万人の会員一人ひとりの属性や購買履歴、嗜好などに応じてパーソナライズして表示される。
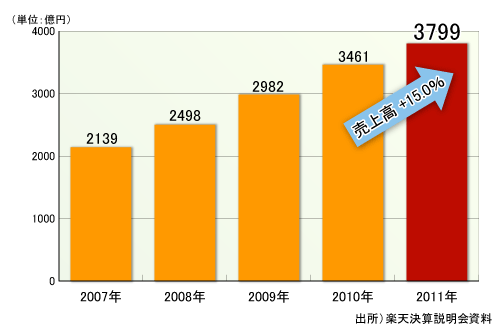
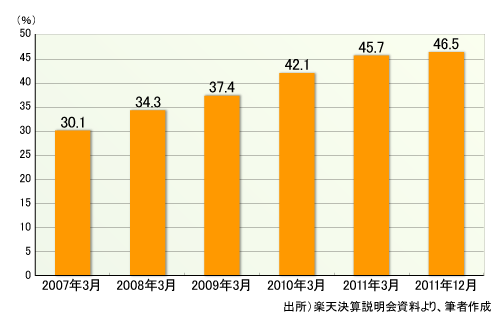
右肩上がりで成長を続ける楽天は2011年度も、過去最高の売上高、営業利益、計上利益を記録するなど好調であった(図1)。また、楽天会員の2つ以上のサービスの利用率も、2011年12月時点で46.5%に達している(図2)。業績とビッグデータ活用との直接の因果関係は明らかではないが、少なからず貢献していると考えるのが自然であろう。