Googleが使っている分散ファイルシステム「GFS」のオープンソースによる実装が、Hadoopの「HDFS」です。ファイルシステムというと、Windowsの「FAT32」や「NTFS」、Linuxの「ext3」や「ext4」などが有名ですが、HDFSはそれらとはちょっと使い勝手が違います。ここでは、実際にHDFSを使ってみます。
とはいえ多数のPCを用意するのは大変でしょうから、ここでも疑似分散モードで動かします。同じマシン上に複数のHDFSのデーモンを立ち上げる方法です。HDFSのデーモンとは前で説明したように、NameNodeやDataNodeです。擬似分散モードでも、複数のデーモンが協調して動くことで、HDFSを利用できるようになります。実際にHDFSを体験してみる前に、HDFSとはどういうファイルシステムなのか簡単に理解しておきましょう。
すでに説明したとおり、HDFSではNameNode、DataNodeの2種類*1のデーモンと、それにHDFSにアクセスするクライアントが協調して動作します。
NameNodeは、HDFSを構成するクラスターの中に1つだけ存在し、HDFSのファイルシステムを管理します。ディレクトリのツリーも把握しています。HDFSの「親玉」というべきデーモンです。
DataNodeは、HDFSを構成するクラスターに1つ以上(複数)存在し、実際にデータ・ブロックを読み書きします。HDFSの「子分」にあたるデーモンです。
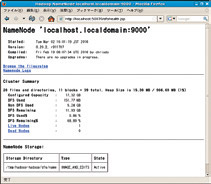
HDFSの管理画面にアクセスして、デーモンの稼働状況を確認してみましょう。http://localhost:50070/にアクセスすると、NameNodeの管理画面を見ることができます(写真1)。
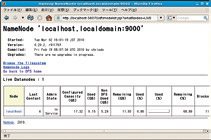
Cluster Summaryの項目を見てみましょう。HDFSのファイルシステムの現在の状態を確認できます。ここで「LiveNodes」をクリックしてみてください。すると、DataNodeとして「localhost」が稼働していて、ディスクをどれくらい消費しているかなどの情報を得ることができます(写真2)。



















































