ここに来てビッグデータの代名詞ともなったApache Hadoopですが、その生い立ちは意外に知られていない感があります。Apache Hadoopというソフトウエアが日本でこれほどメジャーになったのは2011年のこと。Apache Hadoopに早く取り組み始めたという方でも、その存在を知ったのは2008~2009年頃でしょう。
筆者はソフトウエアにも人間と同じように“年齢”があり、シニアになるほど安定し信頼性が増すと考えています。例えば、UnixやLinuxなどのオペレーティングシステムや、リレーショナルデータベース(RDB)、TPモニター、Javaのミドルウエアなどは誕生してから10年以上が経過し、企業システムで利用され続けるなかで、品質・機能とも大幅に向上しました。これらのソフトウエアは成長期を終え安定期にあるでしょう。人間で言うと30代中盤から40代前半、信頼があり経験豊富で重要なポストに就いています。
これらの製品と比較するとHadoopのソフトウエア年齢はまだまだ若い新参者であることは事実でしょう。しかし歴史をひもとくと、話は10年ほど前に遡ります。Hadoopの生い立ちを振り返り、どのような問題を解決するために開発されたか知ることが、ビッグデータ時代のシステムについて理解を深める近道になるかもしれません。
Apache Luceneから始まった
オープンソース検索エンジンライブラリで有名なApache Lucene(関連記事)をご存じでしょうか。検索という行為は、業務でもプライベートでも、パソコンからもスマートフォンからも頻繁に行われるようになりました。この記事を読まれている皆様は、1日何回サーチボックスにキーワードを入力して検索ボタンを押しているでしょうか。そしてこの検索は何に対して行っているのでしょうか。
一般に我々が行っている「検索」では、インターネットで世界中から発信されているWWW(ワールド・ワイド・ウェブ)上のコンテンツに対してキーワード検索を行っています。「一体どうやって、そんな莫大な情報から適切な解(検索結果)を返しているのか」。そう疑問に思ったことはありませんか。ここでは検索エンジン技術そのものを詳しく解説はしませんが、実はこの検索エンジンの技術はHadoop誕生に密接に関係しているのです(図1)。
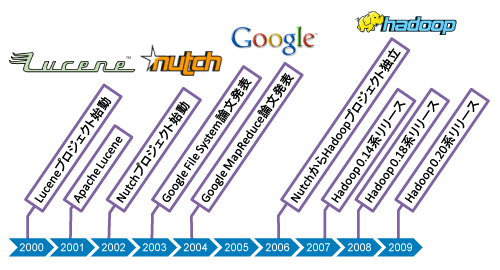
現在は米クラウデラに所属する米国在住のエンジニア、ダグ・カッティング(Doug Cutting)氏はオープンソースの全文検索エンジンライブラリであるApache LuceneをJavaで実装し、2000年に公開しました。その後2001年にApacheソフトウェア財団よりリリースされています。
全文検索ライブラリであるApache Luceneには、サブプロジェクトがあります。Luceneを補完するエンタープライズサーチプラットフォーム(サーバーアプリケーション)であるApache Solrと、Webサイトの情報を収集する(クローリング)Web検索ソフトウエアであるApache Nutchです(表)。Apache Nutchはクローラーと呼ばれたりロボットと呼ばれたりもします。
| プロジェクト名 | 概要 |
|---|---|
| 全文検索ライブラリ。ダグ・カッティング氏が開発。全文検索する為のライブラリの集合体。2011年、日本語の形態素解析器Kuromojiがアティリカ株式会社のクリスチャン・モーエン氏から寄付されている。 http://lucene.apache.org/ |
|
 |
検索プラットフォーム。全文検索ライブラリとしてのLuceneを検索プラットフォームとして形成するためのプラットフォームソフトウェア群。 http://lucene.apache.org/solr/ |
| Web検索ソフトウェア。ダグ・カッティング氏が開発。主にWebのクローラーをベースに開発が進み、後に分散ファイルシステムとMapReduce部分がHadoopプロジェクトとして分離。現在ではリンクグラフデータベース*1や文書のパース機能*2も有する。 http://nutch.apache.org/ |
*2 パース機能:構文解析機能



















































