IT業界では数年に1度、「バズワード」といわれる流行り言葉が生まれる。ここ数年は、「クラウド」一色だった感があるが、2011年後半から2012年にかけてのそれは「ビッグデータ」で決まりだろう。
ビッグデータとは何か
クラウドが登場した当初もそうだったように、「ビッグデータ」にもはっきり決まった定義は無い。一般的には、「既存の技術では管理するのが困難な大量のデータ」と定義されることが多い。
データを管理するのが困難になる要因は、頭文字がVで始まる3つのキーワード(3V:Volume/Variety/Velocity)で表される。つまり、ビッグデータと聞いて、直感的にイメージできる「ボリューム(Volume)」に加え、ソーシャルメディア上のテキストデータ、センサーデータ、さらには映像や音声といったデータの「多様性(Variety)」、スイカ(Suica)やパスモ(PASMO)など交通系ICカードの乗車履歴データに代表される「発生速度や更新頻度(Velocity)」である。ビッグデータというと、データの大きさだけに注目した言葉と捉えられがちだが、それは一側面に過ぎないことに注意されたい。
ただし上に挙げた3Vの特性もまた、データの性質についてのみ着目した定義に過ぎず、これだけでは現在のビッグデータを巡る喧騒は説明できない。このため、筆者は先の定義を狭義とし、広義として次のようにビッグデータを定義している。
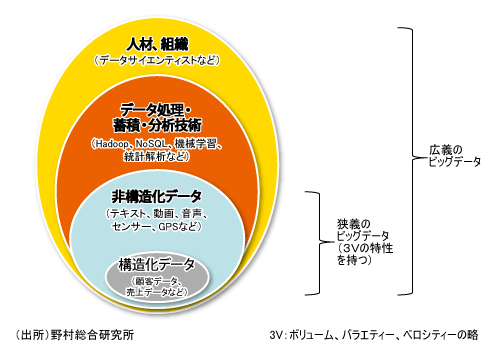
蓄積・処理・分析するための技術とは、大規模データの分散処理フレームワークである「Hadoop」や、事前に構造を定義しなくてもデータを格納でき拡張性に優れるNoSQLデータベース、さらには機械学習や統計解析などを指す。また、データを分析し、有用な意味や洞察を引き出せる人材や組織とは、現在、欧米で引く手あまたとなっている「データサイエンティスト」や、データを有効活用できる組織の在り方などを表す。
米中に比べて準備不足
これまでIT業界で流行ったキーワード同様、「ビッグデータ」もまた米国発のキーワードである。ただし、同様に米国発で流行キーワードとなったEA(エンタープライズ・アーキテクチャ)やSOA(サービス指向アーキテクチャ)、クラウドなどに比べると、ビッグデータには大きな特徴がある。米国から日本に伝搬してくるスピードが段違いに速かったことだ。
10年ほど前までは日本のITは、米国に比べて4~5年遅れと言われた。その「時差」がどんどん縮まっている。筆者の感覚では、クラウドブームの時でまだ2~3年の時差を感じたが、今回のビッグデータに関しては、ほぼ時差が無い。Twitterなどのリアルタイムなコミュニケーションツールの普及で情報の伝搬速度がどんどん上がったためだろう。
結果、言葉だけが一人歩きしやすくなったという見方もできるかもしれない。とはいえ、国内ベンダーが米国発のITトレンドを製品戦略に取り込むスピードも着実に加速しており、既にビッグデータ関連ソリューションを発表したところもある。
問題はユーザー企業の反応である。こうしたトレンドのスピードについてこられるのか。もっと言えば「ビッグデータに対するニーズが顕在化しているのか」だ。
ビッグデータの3Vのうち最初のV、すなわちデータ量に着目した場合、世界全体で見れば、「1年に生成されるデジタル情報の量は既にゼタバイト(ZB、1ZBは10億テラバイト)規模になっている」という調査結果を見かけたことがある人は多いだろう。しかし、一般的な企業にとって肝心なのは、自社が扱うべきデータはどの程度なのかということだ。
ここで興味深いデータを紹介しよう。2011年の8月~10月にかけて、野村総合研究所が日本・米国・中国の各企業の情報システム部門勤務者、あるいはIT製品の購入・選定の関与者を対象に実施したアンケート調査結果である。
分析対象としているデータ量について尋ねたところ、日本企業の場合、ビッグデータの1つの目安である「10TB以上」と回答したのは全体の約28%だった(図2)。だが米国企業の場合は、約51%と半数を超える。中国企業は約36%だ。
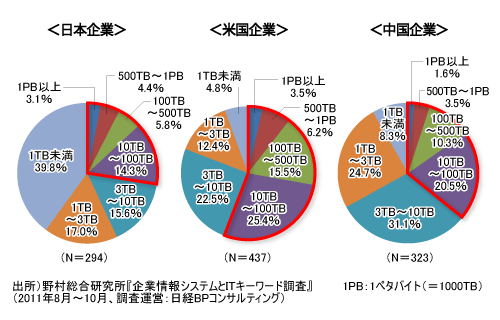
一方で、「分析対象とするデータ量は1TB未満」とした回答者が日本企業の場合は約40%も存在するのに対し、米国企業では5%にも満たない。中国企業も8.3%と米国に近い。日本の場合は大量のデータを抱える企業とそうでない企業で2極化していると言えるだろう。
この結果を見ると、少なくともデータ量の観点では、米国企業の多くが既にビッグデータに直面しているのに対し、日本企業の場合は4分の1強程度ということになる。



















































