今回から再びJava SE 7の新機能を解説していきます。今回は、Java SE 7における国際化の拡張について紹介します。
Unicode 6.0
Java SE 7における国際化の一番の目玉といえばUnicode 6.0です。
普段、Unicodeのバージョンを気にしている人はほとんどいないと思います。しかし、Unicode 6.0は少し違います。Unicode 6.0には携帯電話で使われる絵文字が含まれているのです。
Java SE 7ではUnicode 6.0をサポートしているため、この絵文字が使えるようになりました。
もちろん、Unicode 6.0に対応したフォントがあることが必要です。MacではOS X LionからUnicode 6.0に対応したフォントが含まれていますが、他のOSではなんらかのフォントが必要となります。
本記事では、和田研細丸ゴシックを使用してUnicode 6.0の絵文字を表示していきます。
では試しにやってみましょう。
EmojiSample1クラスはテーブルに絵文字を表示するサンプルです。絵文字を扱うためのテーブルモデルがEmojiTableModelクラスです。
絵文字はchar型の2次元配列に保持してあり、それをjavax.swing.JTableクラスに表示させているだけです。
public class EmojiSample1 {
// 絵文字の例
private char[][] emojis = {
{'\u00A9', '\u00AE', '\u203C', '\u2049', '\u2122',
'\u2139', '\u2194', '\u2195', '\u2196', '\u2197'},
{'\u2198', '\u2199', '\u21A9', '\u21AA', '\u231A',
'\u231B', '\u23E9', '\u23EA', '\u23EB', '\u23EC'},
{'\u23FC', '\u23F3', '\u24C2', '\u25AA', '\u25AB',
'\u25B6', '\u25C0', '\u25FB', '\u25FC', '\u25FD'},
{'\u25FE', '\u2600', '\u2601', '\u260E', '\u2611',
'\u2614', '\u2615', '\u261D', '\u263A', '\u2648'},
{'\u2649', '\u264A', '\u264B', '\u264C', '\u264D',
'\u264E', '\u264F', '\u2650', '\u2651', '\u2652'},
{'\u2653', '\u2660', '\u2663', '\u2665', '\u2666',
'\u2668', '\u267B', '\u267F', '\u2693', '\u26A0'},
};
public EmojiSample1() {
JFrame frame = new JFrame("Emoji Sample");
frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
// 絵文字を扱うためにEmojiTableModelを使用
TableModel model = new EmojiTableModel(emojis);
JTable table = new JTable(model);
// フォントの設定
table.setFont(new Font("和田研中丸ゴシック2004絵文字",
Font.PLAIN, 24));
table.setRowHeight(48);
frame.add(table);
frame.pack();
frame.setVisible(true);
}
public static void main(String[] args) {
SwingUtilities.invokeLater(new Runnable() {
public void run() {
new EmojiSample1();
}
});
}
}EmojiTableModelクラスでは、char型の文字とUnicodeのコードポイントを表示するようにしてあります。
public class EmojiTableModel extends AbstractTableModel {
private char[][] data;
private int columnCount;
private int rowCount;
public EmojiTableModel(char[][] data) {
this.data = data;
rowCount = data.length;
char[] raw = data[0];
columnCount = raw.length;
}
public int getRowCount() {
return rowCount;
}
public int getColumnCount() {
return columnCount;
}
public Object getValueAt(int row, int column) {
// 絵文字とUnicodeのコードポイントを表示する
String value
= String.format("<html><p align=\"center\">%c<br/><small>U+%04X</small></p></html>" ,
data[row][column],
(int)data[row][column]);
return value;
}
}JTableクラスで1セルに複数行の文字列を描画させるには、通常はセルレンダラを用意する必要があります。しかし、ここでは簡便化のため、HTMLを使って複数行を表示させています。
では実行させてみましょう。実行結果を図1に示しました。
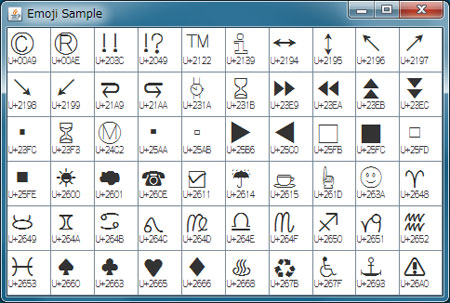
図1を見ると、星占いの星座のマークやトランプのマークなどが含まれていることがわかります。もちろん、Unicode 6.0で導入された絵文字はこれだけではありません。
しかし、これと同じようにすべての絵文字を表示できるわけではありません。というのも、多くの絵文字は、char型の16ビットでは表せないからです。
Unicodeはもともと16ビットの領域に収まっていたのですが、現在では16ビットでは足らず、21ビットまで拡張されています。
16ビットの領域、つまりコードポイントが U+0000からU+FFFFまでをBMP (Basic Multilingual Plane、基本多言語面)とよびます。また、拡張したU+10000からU+10FFFFの領域をSMP (Supplementary Multilingual Plane、追加多言語面)とよび、SMPに含まれる文字を補助文字 (supplementary character)とよびます。
JavaではJ2SE 5.0から補助文字を扱えるようになりました。Java SE 7の機能ではないのですが、簡単に補助文字の扱いについて次節で紹介します。



















































