本連載の第5回からは、「Twitter」や「フェイスブック」といったWeb上の文章を顧客の声(VOC=Voice of Customer)と見なして分析するための手法を紹介している。まず第5回では、自動投稿ツールなどによるゴミ情報と、引用文を選り分けて捨てる手法を解説した。これらがWeb情報の約20%を占めるので、ここまでで分析対象のコンテンツは8割程度に減っている。
しかし、まだWeb上のテキストを分析するうえでの4つの課題のうち、3つが残っている(図1)。第5回で紹介した分析手法は、「顧客の声はゴミまみれ」に対応するものだった。
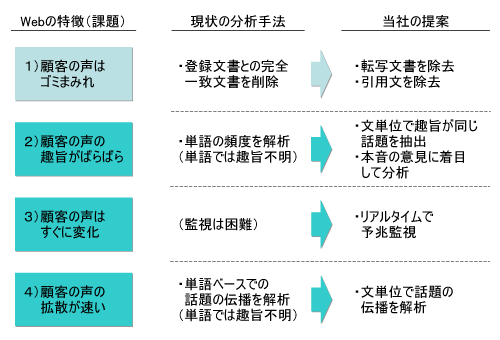
2つ目の課題は「顧客の声の主旨がばらばら」だ。意味のある話題を選り分けなければ、自社にとって関係のない話題や、アフィリエイト目的の記事、根も葉もないデマ・風評なども分析対象になってしまう。
3つ目と4つ目の「顧客の声はすぐに変化する」「顧客の声の拡散が速い」という課題についても、解決策を解説していく。
「類似話題の自動抽出機能」を活用しながら体系的に分類する
Web情報を分析するための既存のテキスト分析ツールの多くは、単語の出現頻度を分析して上昇傾向などを判断するものである。これは発言内容を把握するにはあまり役立たないことが多い。
Twitterでは「ハッシュタグ」(発言者が投稿文に付ける半角英数字の文字列)などを頼りに、特定の話題に関する発言を抽出できるケースがあるものの、それでも全体傾向をつかむのは容易でない。我々が欲しいのは、大くくりなテーマ情報だけでなく、発言内容別に整理・分類された情報である。マクロに全体傾向を把握することはもちろん、ミクロに詳細な声の内容を確認したいのである。
そこで、ある食品メーカーが行った震災関連キャンペーンに関するTwitterでの投稿を分析した具体的な事例を紹介しよう。基本的な分析作業内容は、第2回や第4回で登場した「類似話題の自動抽出機能」をベースとしている。なお、Twitterには「1ツイート(投稿)当たり140字以内」という制限があって長文が無いので、ツイート単位で分析している。
まず自動分類された結果から大まかな内容を把握する。既に類似する内容ごとに分類されている(これをクラスタと呼ぶ)ので、代表文書を見ながら要否を判断すればよい。
具体的なツイートの内容を見てみると、たわいない雑談が大半を占め、クレーム・意見・要望・称賛などの、顧客の声の分析に有用なツイートはそう多くないことに気づく。
それらを即座に分析対象から外し、分析に有用なクラスタだけをピックアップする。そして分類結果を体系化かつ詳細化していく。この作業で、デマ・風評といったゴミ情報を取り除くことも簡単にできる(図2の上部)。

まず「ポジティブ/ネガティブ」で大きく分類する。すると、ポジティブなクラスタは「復興支援活動への称賛」「CMがいい」「食べに行きたい」といったものから成り、ネガティブなクラスタは「量が少ない」「メニューへの不満」「キャンペーンへの批判」といったものから成ることが判明した。
さらに分類に含めるフレーズを取捨選択し、個々の詳細分類での分類条件を精緻に調整すると、最終的な分類結果が得られる(図2の下部)。その結果、全体像としてのネガ・ポジ比率とその内容が判明し、キャンペーンへの批判が大多数であることが分かった。
ここからさらに、個々の話題(キャンペーンへの批判や復興支援への賞賛)の中身を詳細に検討していけばよい。その作業内容は第4回におけるクレームの分析と同様である。こうした分析に要する時間は内容にもよるが、本事例規模(ツイート数は6000強)では1時間半程度である。
上記の分析作業のポイントは、実際の顧客の表現に即して分析する点である。お仕着せのネガ・ポジ分析を売りとしているツールもあるが、実務で役立つことは少ない。



















































