「障害が発生しても止まらないシステムを実現したい」「災害に備えたリアルタイムの遠隔バックアップやシステムの二重化を行いたい」「大容量データをバックアップしたい」---震災以来、これらはシステムにとっての大きな課題となっている。
これらを実現するHA(高可用性)システムは、無償で利用できるオープンソースソフトウエア(OSS)で実現できる。そのためのOSS群が「Linux-HAクラスタスタック」である。
Linux-HAクラスタスタックは、仮想化環境やクラウド環境で使うこともできる。今回を含めて5回にわたって、Linux-HAクラスタスタックおよびこれを構成するソフトウエアの概要を紹介する。
HAクラスタの仕組み
サーバーハードウエアの故障やメンテナンス、ソフトウエアの動作障害については、2台のサーバーを用意して、Linux-HAクラスタスタックのHeartbeatとPacemakerなどのクラスタ管理システムでHAクラスタにするのが有効だ(図1)。1台がアクティブ機になってサービスを提供し、もう1台はスタンバイ機になってアクティブ機がダウンしたときにはアクティブ機の機能を引き継いでくれる。引き継ぎに必要な時間は数十秒程度なので、比較的容易に99.999%程度の可能性を追求できる。
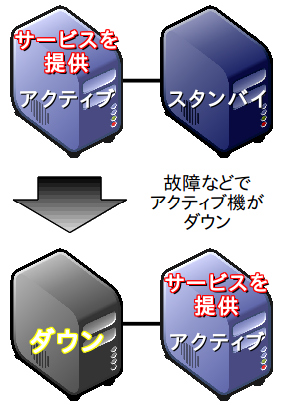
高い可用性を実現するには、単一障害点(Single Point of Failure、SPOF)を極力取り除くことが必要だ。SPOFとは、「ここが止まったらシステム全体が止まってしまう要素」のことである。サーバーハードウエア、ソフトウエア、ストレージ、ネットワーク機器など、実際には多くのSPOFが存在する。
とりわけ重要なのはストレージだ。ストレージが故障すると大切なデータを失ってしまう。RAIDは1~2台のディスクドライブの同時故障に有効だが、HAクラスタを構成した場合には、アクティブになったサーバーがストレージにアクセスできるような特別な構成が必須になる。外部増設共有ストレージ方式とレプリケーション方式がある(図2)。
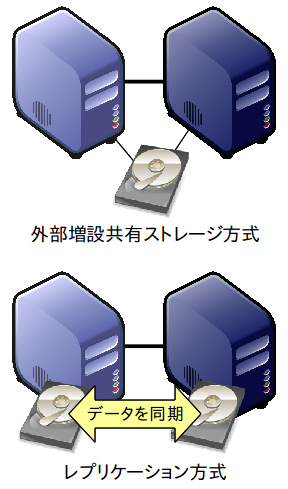
外部増設共有ストレージ方式は、ストレージ機器自体がSPOFになる。このため、コントローラや電源を二重化した信頼性が高い機器を選ぶべきだが、高価になりがちだ。さらに、2台のサーバーが同時にストレージ領域をマウントしないような万全の排他制御が必須になる(2台のサーバーが同一ディスク領域を同時にマウントすれば、ファイルシステムとデータが壊れてしまうため)。
レプリケーション方式は、2台のサーバーのそれぞれのストレージ領域にデータを同時に書き込むもので、Linux-HAクラスタスタックのDRBDを使って実現できる。データはつねに2箇所に書き込まれているため、SPOFを完全に追放できる。また、2台のサーバーが間違えて同時にデータ領域をマウントしてしまっても、ファイルシステムやデータの破壊は起こらない。さらに、どちらかのストレージが完全に壊れても、RAID 1のリビルドと同様に、他方のストレージからデータをコピーしてデータの整合性を回復できる。
ネットワークにおけるSPOFの削減には、スイッチなどの機器の二重化、ネットワーク配線の二重化、マルチパス、ボンディングなどのテクノロジーが存在する。Linux-HAクラスタスタックの紹介とは直接関係しないため、詳細は割愛する。



















































