筆者らは、オープンソースソフトウエアの分散処理ミドルウエア「Hadoop」を、基幹系のバッチ処理システムに適用するためのフレームワーク「Asakusa」を開発した。AsakusaはHadoopと同様に、オープンソースソフトウエアとして公開する。公開日は、本連載の4回目をお届けする2011年3月31日の予定である。
Asakusaを使うことでHadoopによる分散処理のメリットを享受することが可能となり、これまでRDBMSを利用していた場合と比べて、多くのケースでバッチ処理システムの性能を大幅に向上することができる。筆者らが実際に構築を支援したシステムでは、それまで4時間かかっていた処理が数分で終わるようなケースも出てきている。
盛んに報道されているように、Hadoopはすでに多くの導入実績がある。ただしその用途は、ログ分析システムやレコメンデーションエンジンなどのビジネスインテリジェンス(BI)系が中心で、米Yahooや楽天など、主にWebサービス提供事業者が利用している。Webサービス提供事業者が扱うデータ量は増加の一途をたどっており、RDBMSベースのシステムでは解析に時間がかかりすぎる。その解としてHadoopが利用されてきている。
一方のAsakusaは、これまでとは違う基幹バッチ処理にターゲットを置いている。ログ分析などBI向けに利用されてきた従来のツールでは、基幹バッチ処理システムの開発は困難である。そこでAsakusaは、従来とは異なる道具立てを用意している。例えば、非常に多くのメンバーが複数チームに分かれて行うような大規模開発のためのフレームワークを提供する。また、バッチジョブの運用監視機能やテスト環境まである。これらは、基幹バッチ処理システムの開発では欠かせないものだ。
今回の連載では、まずAsakusaが何を可能にするものかを解説し(第1回)、次にAsakusaの構成要素を示す(第2回)。そのあとAsakusaを使ったシステムの設計方法を解説し(第3~4回)、最後に実際のコード例を紹介しよう(第5回)。
Hadoopの本質は分散I/O
Asakusaの紹介に入る前に、Hadoopのパフォーマンスがなぜ高いのかをポイントを絞って解説する。まず、Hadoopが検討される背景から眺めてみよう。そもそも従来の仕組みでは、どんどん量が増えているデータを、なぜ求める時間内に処理できないのだろうか。
CPUの処理性能はデータ量の増大に比例するかのように向上している。「昨年はパフォーマンスが50%向上したと聞く。メニーコア化が進み、それだけでもパフォーマンスは数倍になっているではないか」という意見は正しい。
しかし多くの処理では、CPUやメモリーではなく、ディスクでのI/Oにボトルネックが発生する。CPUなどの処理能力の向上に比べ、ディスクI/Oの性能は、ここ数年来、わずかしか向上していない。CPUの能力を使い切る前にディスクI/Oがボトルネックになり、全体のスループットが向上しないのだ。Hadoopはこの部分に注目した仕組みである。
ディスクI/Oのボトルネックを解消するため、HadoopはディスクI/Oを分散させるという手段を提供している。要するに1カ所でデータの読み込まず、n箇所で読み込めば、パフォーマンスは単純にn倍になるだろうという発想だ(図1)。
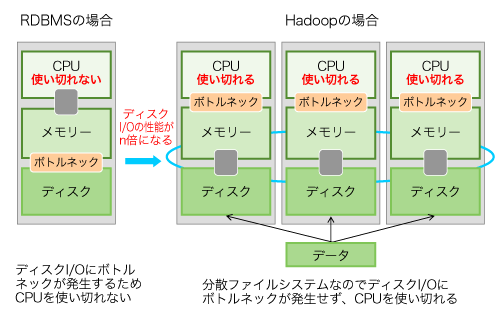
これには次のような反対意見が出るだろう。「ちょっと待ってくれ。データを分散したらデータを更新できないじゃないか。n箇所にあるデータを一斉に更新するのは、ほとんど不可能だ。それを狙った多くの仕組みは事実上、失敗している」。これは指摘の通りである。
そこでHadoopは、あっさりとデータの更新を諦めている。入力したデータを整理・変換して、別のデータを出力するという処理モデルに限定している。もっとも、それでは使い勝手が向上しない部分もあるので、徐々にではあるが、更新処理が可能な仕組みも導入されてきている。それでもHadoopは更新が苦手という事実は変わらない。うまく活用するには、そのデメリットを理解しておく必要がある。
またHadoopというと、まず「MapReduce」という分散処理アルゴリズムがクローズアップされることが多い。「Hadoop=MapReduce」という印象は強く、確かにその理解も一面では正しい。しかしHadoopの本質は、MapReduceのアルゴリズム自体ではなく、あくまで分散I/Oだと考えた方がよい。
つまりHadoopを使ってシステムの性能を高めるには、いかにディスクI/Oを分散させるかという観点が欠かせない。ディスクI/Oを分散させるには、事前に処理の並列性を担保する必要がある。Asakusaは基幹バッチ処理を高速化するために、設計段階から処理の並列性を確保し、そのままシームレスに開発につなげる仕組みである。Asakusaでアプリケーションを開発する際は、この設計から実装までをシームレスにつなげるところが焦点になる。本稿では、分散I/Oと表裏一体となる並列性の確保の考え方が、バロック音楽の通奏低音のように流れることに留意してほしい。




















































