これまで2回にわたってWebアプリケーションにおける入力値検証とセキュリティ対策の関係を説明してきた。入力値検証はセキュリティ上の根本的対策ではないが,保険的な対策として効果が期待でき,特に制御コードや不正な文字エンコーディングによる攻撃対策には有効であることを説明した。
今回は,Webアプリケーション開発によく使われる4種類の言語(Perl,PHP,Java,ASP.NET)に関して,入力時処理の具体例を示す。ここで取り上げる「入力時処理」とは以下の内容を含んでいる。
- 文字エンコーディングの検証
- 文字エンコーディングの変換
- 入力値検証
Perlによる実装の方針
Perl言語はバージョン5.8から内部文字エンコーディングとしてUTF-8をサポートし,文字単位での日本語処理が可能だ。文字エンコーディング処理にはEncodeモジュールを使用する。入力値検証には正規表現を用いるのが便利だ。
■文字エンコーディングの変換と検証
PerlによるUTF-8での処理の基本は,入力時にEncodeモジュールのdecode,出力時に同じくencodeを適用することが基本となる。リスト1に,標準入力から一行読んで標準出力に一行書き込むPerlスクリプトを示す(Windowsのコマンドプロンプトでの実行を想定)。

decodeおよびencodeの第一引数’cp932’が文字エンコーディング指定である。cp932という文字エンコーディングは,Windowsのベンダー依存文字を考慮したShift_JISを意味する。ベンダー依存文字をエラーにしたければ,’shiftjis’を指定するとよい。この場合は,「①」や「髙」(はしご高)がエラーとなる。
decode関数は,デフォルトでは不正な文字エンコーディングに対して,特別なコードポイントU+FFFDを返す。このため,変換と同時に文字エンコーディングの検証も実施できる。リスト2に,CGIの形でそのサンプルを示した。リスト2は,クエリー文字列pで受け取った文字列を表示するだけのものだが,正規表現により不正な文字エンコーディングをチェックしている。
このCGIでは,第9回に示した原則に基づき,HTTPリクエスト・レスポンスの文字エンコーディングとしてUTF-8を指定している。Perlは内部でUTF-8を使用しているが,この場合でも,内部形式との相互変換のためdecodeおよびencodeは必要だ。

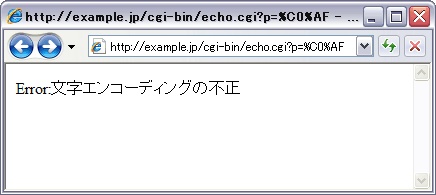
リスト2に対して,前回紹介した「冗長なUTF-8」として,%C0%AFを指定した場合の表示例を図1に示す。このように,プログラムの先頭で不正な文字エンコーディングをチェックすることにより,プログラムの安全性を高めることが可能だ。