文字コードに関する問題は大別すると文字集合の問題と文字エンコーディングの問題に分類できる。前回は文字集合の取り扱いに起因するぜい弱性について説明したので、今回は文字エンコーディングに起因するぜい弱性について説明しよう。
文字エンコーディングに依存する問題をさらに分類すると2種類ある。(1)文字エンコーディングとして不正なデータを用いると攻撃が成立してしまう点と,(2)文字エンコーディングの処理が不十分なためにぜい弱性が生じることがある点だ。
不正な文字エンコーディング(1)――冗長なUTF-8符号化問題
まず,(1)の不正な文字エンコーディングの代表として,冗長なUTF-8符号化問題から説明しよう。前々回に解説したUTF-8のビット・パターン(表1に再掲)を見ると,コード・ポイントの範囲ごとにビット・パターンが割り当てられているが,ビット・パターン上は,より多くのバイト数を使っても同じコード・ポイントを表現できる。

具体例で説明しよう。スラッシュ「/」U+002Fは,0x7F以下であるので1バイトで表現でき,UTF-8でも0x2Fと表現される。しかし,2バイト以上の形式でもビット・パターンとして表現できる。具体的には表2のようになる。

表のオレンジ色で示した部分は,UTF-8の冗長表現などと呼ばれる。UTF-8の規格上は,最短の形式だけが正規で,冗長表現は不正と定義されているが,処理系によってはこのチェックが実施されておらず,不正な形式が許容される場合がある。
冗長形式が許容されている場合,一つの文字に対して複数のビット・パターンが存在することになり,混乱の原因になる。セキュリティ対策として特殊文字をチェックする場合,冗長形式のデータがあると,正規形に対するチェックをすり抜けてしまう。過去に,Microsoft IISのぜい弱性(MS00-057)やApache Tomcatのぜい弱性(CVE-2008-2938)の原因となったこともあるため,注意が必要である。詳しくは,「入力値の検証」の項で説明する。
不正な文字エンコーディング(2)――半端な先行バイトによるXSS
不正な文字エンコーディングによる代表的なセキュリティ問題の2例目として,「半端な先行バイト」によるクロスサイト・スクリプティングを紹介しよう。以下のようなperl言語によるCGIがあったとする。リストのように住所と氏名を登録するだけの簡単な機能で,入力欄には初期値が与えられるようになっている。

これを実行した様子が図1である。
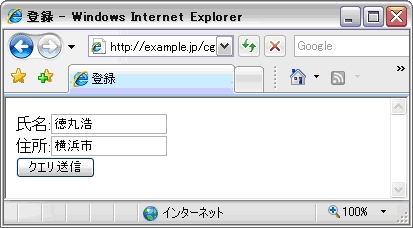
リストの4行目,5行目を見ると,escapeHTML関数を使ってHTML入力をエスケープしている。このためクロスサイト・スクリプティング(XSS)の心配はなさそうに見えるが,このCGIを以下のようなURLで起動してみる。
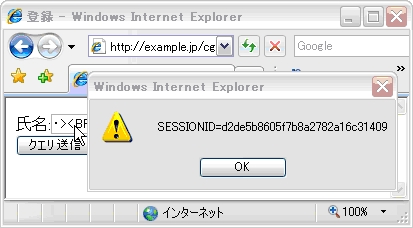
この状態で,氏名欄にマウス・カーソルを合わせるとダイアログがポップアップしてCookieの内容が表示される(図2)。つまり,クロスサイト・スクリプティングのぜい弱性が存在することになる。
ぜい弱性が発生する理由を説明しよう。上記の状態で,HTMLソースの一部を以下に示す。
氏名欄のvalue属性の引用符が閉じられていない。これは,「name=%81」で指定された値0x81がShift_JISの先行バイトであるため,後続のダブルクオート「”」(0x22)がShift_JISの後続バイトとみなされ,合わせて一文字と扱われているためである。つまり,上記の青字の部分全体がvalue属性とみなされたため,onmouseover以下が新たな属性として追加されている。JavaScriptのスクリプトを外部から注入できたことになる。
なお,0x22はShift_JISの後続バイトとしては範囲外なので,0x81 0x22という並びはShift_JISとしては不正な値だが,たいていのブラウザでこの現象は発生する。IE 7,Firefox,Opera,Safariの最新版で再現を確認した。Google Chromeでは再現しない。
不正な文字エンコーディングへの対策は単純である。入力値を取得した直後に文字エンコーディングの妥当性を検査し,不正な値であればエラーとする。具体的な検査方法については「入力値の妥当性検証」の項で説明する。



















































