|
GHC 6.10のベクトル化機能 2008年9月21日にGHC6.10.1 betaが公開されました(参考リンク)。このバージョンから,データ並列Haskellの利用に必要なライブラリが正式に提供されることになりました。加えて,並列配列を使ったプログラムに対する基本的なベクトル化機能が提供されるようになりました。つまり,第10回で説明したデータ並列Haskellを利用するための機能が,一通り組み込まれたことになります。そこで,いくつか補足で説明しておきましょう。 GHC6.10.1では,mtlなどと同じextralibsという扱いで,dph-*という名前のパッケージが加わっています。 $ ghc-pkg list dph-*
C:/ghc/ghc-6.10.0.20080921\package.conf:
(dph-base-0.3), (dph-par-0.3), (dph-prim-interface-0.3),
(dph-prim-par-0.3), (dph-prim-seq-0.3), (dph-seq-0.3)手元のGHCにdph-*が含まれない場合には,ghc-(version)-src-extralibs.tar.bz2という名前のアーカイブの中身を加えてもう一度GHCをビルドし直すか,第2回のコラムで説明したData.ByteStringのインストール方法を参考にインストールしてください。dph-*はghc-(version)-src-extralibs.tar.bz2に含まれるほか,バージョン管理システムのdarcsを使ってhttp://darcs.haskell.org/ghc-6.10/libraries/dph/またはhttp://darcs.haskell.org/packages/dph/からも取得できます。 ただし,GHCをビルドせずにdph-*をインストールする場合には,いくつか注意点があります。まず,dph-parとdph-seqパッケージはmakeコマンドを使って作成しなければなりません。 $ make dph-par dph-seq rm -rf dph-par rm -rf dph-par.tmp mkdir dph-par.tmp cp dph/Setup.hs dph-par.tmp/ cpp -DUSE_dph_par < dph/dph.cabal | grep -v "^#" > dph-par.tmp/dph.cabal mv dph-par.tmp dph-par rm -rf dph-seq rm -rf dph-seq.tmp mkdir dph-seq.tmp cp dph/Setup.hs dph-seq.tmp/ cpp -DUSE_dph_seq < dph/dph.cabal | grep -v "^#" > dph-seq.tmp/dph.cabal mv dph-seq.tmp dph-seq 次に,dph-*は階層構造になっているため,依存関係をきちんと考えてインストールしなければなりません。ghc-pkgのfieldコマンドを使い,それぞれのパッケージの依存関係をみてみましょう。 $ ghc-pkg field dph-par depends
depends: array-0.2.0.0 base-4.0.0.0 dph-base-0.3 dph-prim-par-0.3
ghc-prim-0.1.0.0 random-1.0.0.1
$ ghc-pkg field dph-prim-par depends
depends: array-0.2.0.0 base-4.0.0.0 dph-base-0.3
dph-prim-interface-0.3 dph-prim-seq-0.3 ghc-prim-0.1.0.0
random-1.0.0.1
$ ghc-pkg field dph-prim-interface depends
depends: base-4.0.0.0 dph-base-0.3 random-1.0.0.1
$ ghc-pkg field dph-seq depends
depends: array-0.2.0.0 base-4.0.0.0 dph-base-0.3 dph-prim-seq-0.3
ghc-prim-0.1.0.0 random-1.0.0.1
$ ghc-pkg field dph-prim-seq depends
depends: array-0.2.0.0 base-4.0.0.0 dph-base-0.3
dph-prim-interface-0.3 ghc-prim-0.1.0.0 random-1.0.0.1これらの情報から,dph-base,dph-prim-interface,dph-prim-parまたはdph-prim-seq,そしてdph-parまたはdph-seqの順番でインストールする必要があることがわかります。 ところで,dph-*パッケージとは何でしょうか? これは第10回で説明したndpパッケージの後継に当たるものです。 データ並列Haskellのバックエンドでは,単に並列配列を使ったプログラムを並列化するだけでなく,配列を使ったプログラムの実行を高速化するためのいくつもの野心的な仕組みを提供することで,プログラムの実行の高速化を図っています(参考リンク1,参考リンク2,参考リンク3)。こうした機能が期待通りに動作するかどうかを確かめるには,バックエンドの配列操作,ベクトル化によって生成された配列に対する操作,それぞれの逐次実行と並列実行の下での動作,の三つについて調べる必要があります。 しかし,ndpパッケージは一枚岩の構造になっていたため,こうした機能追加・テストのサイクルを行うには不向きでした。そこで,インタフェースとバックエンドを分割し再構成したのが,dph-*パッケージによって構成されるDPH(Data Parallel Haskell)ライブラリです。 ユーザーとして利用する場合には,「dph-seqが逐次版ライブラリ,dph-parが並列版ライブラリで,どちらも同じAPIとなっている」ということを理解しておけば十分でしょう。ライブラリの切り替えは,オプション一つでできます。 それでは,GHC6.10.1のベクトル化機能を利用する方法について説明しましょう。処理系にDPHライブラリが含まれている状態であれば,DPHライブラリのモジュールを利用するようコードを書き換えることで,並列配列を使ったプログラムをベクトル化できます。 {-# LANGUAGE PArr #-}
{-# OPTIONS_GHC -fvectorise #-}
module QSortVect (qsort) where
import Data.Array.Parallel
import Data.Array.Parallel.Prelude
import Data.Array.Parallel.Prelude.Double
import qualified Data.Array.Parallel.Prelude.Int as I
import qualified Prelude
qsort:: [: Double :] -> [: Double :]
qsort xs | lengthP xs I.<= 1 = xs
| otherwise =
let m = xs !: (lengthP xs `I.div ` 2)
ls = [:s| s <- xs, s < m:]
ms = [:s| s <- xs, s == m:]
hs = [:s| s <- xs, s > m:]
-- sorted = mapP qsort [:ls, hs:]
sorted = [:qsort xs' | xs' <- [:ls, hs:]:]
in (sorted !: 0) +:+ ms +:+ (sorted !: 1)GHC.PArrモジュールの代わりに,DPHライブラリで公開されているData.Array.Parallelモジュールを使用しています。GHC.*はあくまでライブラリなどの実装の内部で使用される機能を提供するためのモジュールです。並列配列を使用したプログラムを記述する場合には,なるべくData.Array.Parallelを利用する方がよいでしょう。 ほかに第10回の例と定義が多少異なる部分があるのは,現在のDPHライブラリやベクトル化機能はまだ完全ではなく,実装上の制限があるためです。 今のところ,並列配列を使って書かれたプログラムに対してベクトル化を行うには,Preludeモジュールの代わりにData.Array.Parallel.Preludeを使用する必要があります。しかし,このモジュールはまだPreludeで提供されているすべてのAPIを網羅しているわけではありません。例えば,型クラスを提供していません(参考リンク)。このため,「Double型を利用する場合にはData.Array.Parallel.Prelude.Double」「Int型を利用する場合にはData.Array.Parallel.Prelude.Int」と,使用する型ごとにモジュールを別途インポートしてその型に対する関数を使用する必要があります。結果として,qsortは特定の型の並列配列を整列する関数として記述する必要があります。 また,GHC6.10.1のベクトル化機能は,どんなプログラムでも正しく扱えるほどには賢くありません(参考リンク)。単純にベクトル化を行うための-fvectoriseオプションをコマンドラインなどで外部から与えると,ベクトル化できない部分もベクトル化しようとして,コンパイルに失敗します。そこで,OPTIONS_GHC指示文を利用し,-fvectoriseオプションをQSortVect.hsだけに与えるようにします。 $ ghc -Odph -fvectorise -fdph-par QsortVect.hs VectTest.hs -package random -threaded
compilation IS NOT required
*** Vectorisation error ***
Tycon not vectorised: GHC.Show.:TShow
現時点では,qsortのパターン照合を使った定義をベクトル化するのに失敗します。このため,パターン照合ではなくガード節を使うようにプログラムを書き換えています。 $ ghc -c -Odph -fdph-par QSortVect.hs
*** Vectorisation error ***
Can't vectorise expression
case ds_dzh of wild_X8 {
__DEFAULT ->
let {
m_auK :: GHC.Types.Double
[]
m_auK =
GHC.PArr.!:
@ GHC.Types.Double
ds_dzf
(Data.Array.Parallel.Prelude.Base.Int.div
(GHC.PArr.lengthP @ GHC.Types.Double ds_dzf) (GHC.Types.I#
2)) } in
~ 略 ~では,実際にベクトル化機能を試してみましょう。ランダムな値を作成し,それをqsortを使ってソートします。 import GHC.PArr (toP)
import System.Random
import QSortVect
main = do
g <- getStdGen
print $ qsort $ toP $ take 150000 $ randoms grandomパッケージのSystem.Randomモジュールが提供しているgetStdGenは,大域にある乱数生成機を取得する関数です。同じくSystem.Randomモジュールにあるrandomsを使って乱数のリストを作成します(参考リンク1,参考リンク2)。 Prelude System.Random> :i getStdGen
getStdGen :: IO StdGen -- Defined in System.Random
Prelude System.Random> :i randoms
class Random a where
...
randoms :: (RandomGen g) => g -> [a]
...
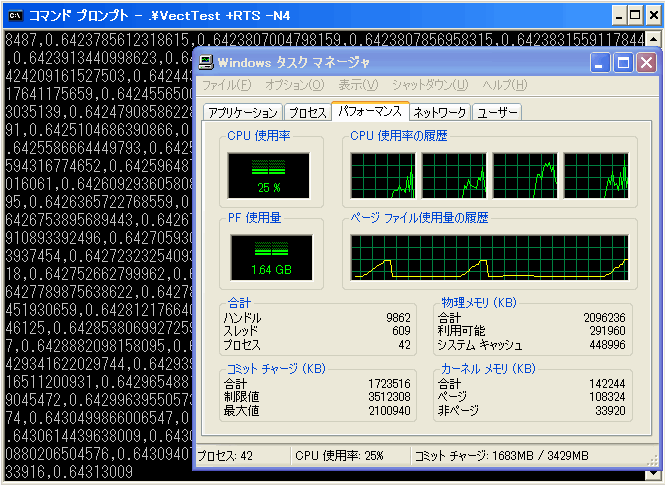
-- Defined in System.RandomtoPはリストを並列配列に変換する関数です。逆の役割を持ったfromPもあります。 Prelude GHC.PArr> :t toP toP :: [a] -> [:a:] Prelude GHC.PArr> :t fromP fromP :: [:a:] -> [a] 現時点ではtoPはData.Array.Parallelでは公開されていないため,GHC.PArrからインポートして使っています。 なお,第10回で説明したsetGang関数は不要です。-N<x>オプションで指定したプロセサの数を内部で取得するように,すでにDPHライブラリの内部実装が書き直されているためです。 以下のコマンドでプログラムをコンパイルします。 $ ghc -Odph -fdph-par VectTest.hs --make -threaded [1 of 2] Compiling QSortVect ( QSortVect.hs, QSortVect.o ) [2 of 2] Compiling Main ( VectTest.hs, VectTest.o ) Linking VectTest.exe ... 第10回の例とはいくつかオプションが変っているのがわかりますね。 -Odphは,データ並列Haskellを使ったコードをコンパイルするために用意されている専用の最適化レベルです。-O2の最適化に加え,必要だと思われるいくつかの最適化フラグをパッケージ化しています。データ並列Haskellを使う場合には,この最適化を選択するのがよいでしょう。 -fdph-parオプションは,ベクトル化の方法に影響を与えるものです。-fdph-parでは,dph-parパッケージなどの並列版のライブラリをバックエンドとして,並列配列を使用したコードのベクトル化を行います。一方,dph-seqパッケージなどで用意されている逐次版のライブラリをバックエンドとして使いたい場合には,-fdph-seqを使用します。dph-parまたはdph-seqの実装内部でベクトル化を行いたい場合に指定する-fdph-thisというオプションもあります(参考リンク)。 現時点の-fdph-*オプションは,逐次版,並列版,内部実装という単純な使い分けにのみ対応しています。分散処理やNUMAなど多様なアーキテクチャに対応したdph-*パッケージが増えることで,-fdph-*オプションの種類は増えていくでしょう。状況によっては,現在割り当てられているオプションの名称が変更される可能性があります。データ並列Haskellを使う場合には,こうした点に注意してください。 では,実行してみましょう。 $ ./VectTest +RTS -N4 [:7.211114281591158e-6,1.0765739719087453e-5,1.6909209083981747e-5,2.11991136943 ~ 略 ~ 7,0.999937282293089,0.9999452963238455,0.9999541161814598,0.9999620494199828,0.9 999696646118466,0.9999718616018006,0.9999907602323197:] Windowsのタスク マネージャを使えば,実際にこのプログラムが並列に動作していることを確認できます。
|
|
著者紹介 shelarcy 今回の説明では,POSIXスレッドAPIを使った例やマルチスレッド環境下での外部リソースの管理の話題を省きました。前者を省略したのは,WindowsとPOSIXの両方のスレッドAPIを使って正しく動く例を作ろうとすると,本筋のコード以外に多くのコードを書く必要が出てくるからです。Haskellプログラム自体も単純なものではないのに,FFIを使って呼ばれるCの関数の定義も複雑になると,読者の注意をいたずらに本題から遠ざけることになります。このため,Windows APIの例に絞ってCのコードを単純に保つことを選びました。おそらくPOSIXスレッドを利用しても同じように動作する例が作れるはずなので,興味のある方は挑戦してみてください。 後者を省略したのは,FFI,スレッド,リソース管理の三つそれぞれの組み合わせについて考える必要があるためです。これらのうち二つの組み合わせだけでも,第13回,前回の第23回,そして今回と,1回分の話題になります。三つすべてを考慮しなければならない場合について,きちんと書こうとすればそれ相応の分量が必要でしょう。 なので,リソースの管理については別の機会に改めて説明したいと思います。Foreign.Concurrentモジュールのドキュメントでも言及されていますが,こうした話題は「Destructors, Finalizers, and Synchronization」という論文およびそのプレゼン資料にまとまった形で書かれています。興味のある方は参考にしてください。 |



















































