仕様通りに動かない――。
誰もが一度は経験したことがあるだろう。中電技術コンサルタントの中祖泉氏は,サーバー/ストレージの入れ替えに伴うソフトウエアの移行作業の中でこの問題に直面した。
作業自体はシンプルなはずだった。旧サーバー上で稼働中の「Documentum」を新サーバー上に移せばよい。まずはOS,DBMS,Documentumを順番にインストールし実データを旧環境からコピーしてみた。ところが,なぜかDocumentumがデータを認識できない。Tarを使いDocumentum本体とデータを一括して移行すればよいとベンダーからアドバイスを受け,試みたがそれもダメ。最後は,Documentumが持つDump/Load機能を使ってようやくデータ移行に成功した。
「社内にノウハウを蓄積するために,最近はなるべくベンダーに頼らず自分で作業するようにしている。加えて,今回はたまたまベンダーの動きもあまり良くなかった」(中祖氏)。問題に直面したとき,一つのやり方にとらわれず,試行錯誤を繰り返す。第3の力は「試す力」。工夫する力である。
解決できる場を設ける
ここで言う「試す力」は,いったん表面化してしまった問題を収束させる力のことである。問題に対して複数の解決策を用意し,次から次へと解決の矢を放てる仕組みを作りたい。
朝日新聞社の基幹システム「ネルソン」を刷新する巨大プロジェクト。10個以上あるサブシステムのコーディネートを請け負った東芝ソリューションの土方紀和氏(ソリューション第二事業部 新聞ソリューション部 新聞ソリューション第三担当 主任)は,結合テスト工程を前に頭を抱えていた。
「テストが2万項目に上る。それに要する時間を積み上げていくと5カ月になる」(土方氏)。計画を3カ月もオーバーする計算だった。
土方氏が用意したのは,対策を打ちつつその遂行状況をチェックし,必要に応じて調整できる“場”だった。それまで分かれて開発してきたサブシステムのメンバーを1カ所に集め,朝と夕方に状況を報告してもらい,予定を随時調整する。関係するメンバーの総数は100人にも上った。
土方氏は,膨らみがちなテスト期間の圧縮に向け,この場でいくつもの手を打った。重要度によりテストの項目を削減。次に,似たようなテストやシナリオ化できる複数のテストを一つに統合。さらに,データベースのリソースに応じて複数のテストを多重化した(図5)。これらが功を奏し,当初計画の2カ月で終えることに成功した。
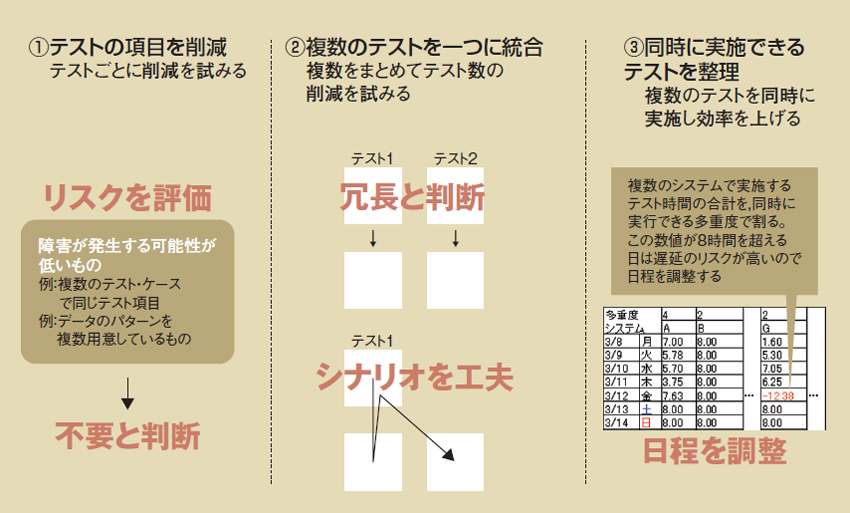 |
| 図5●4~5カ月かかるはずだったテスト期間を2カ月に圧縮した朝日新聞社と東芝ソリューションの工夫 (1)テストの項目の削減,(2)複数のテストの統合,(3)同時に実施できるテストの整理,を実施した [画像のクリックで拡大表示] |
反復開発で精度を上げていく
プロジェクトの早い段階で問題が表面化するケースもある。日本コムシスの藤本晴彦氏(ITビジネス事業本部 ソリューション部 社内IT部門 担当課長)が直面したのは,要件定義ができないという問題だった。
「これまで事務部門や営業部門のシステムを主に作ってきた。工事現場の業務を改善するシステムを開発しようとした途端,彼らの業務をよく知らないことに気づいた」(藤本氏)。
日本コムシスでは,これまでウォータフォール型の開発を基本にしてきた。今回のケースはそれでは要件定義が進まない。反復開発を試みることにした。ただし,XPやRUPなどの汎用的な方法論を意識していたわけではない。
「まずはモックアップを作ってエンドユーザーに見てもらおうと思った。こちらでアイデアを持って行き,フィードバックをもらう形で開発を進めた」(藤本氏)。結果的に,反復開発のイテレーション(繰り返し)にのっとったものになっていた。
図6が,実際に開発したシステム「ガッテン君」の画面である。「表示サイズ,表示履歴数,表示列数の変更機能」「更新間隔変更機能」「日付,撮影者,キーワードによる検索機能」などの機能がイテレーションの成果として加わったものである。
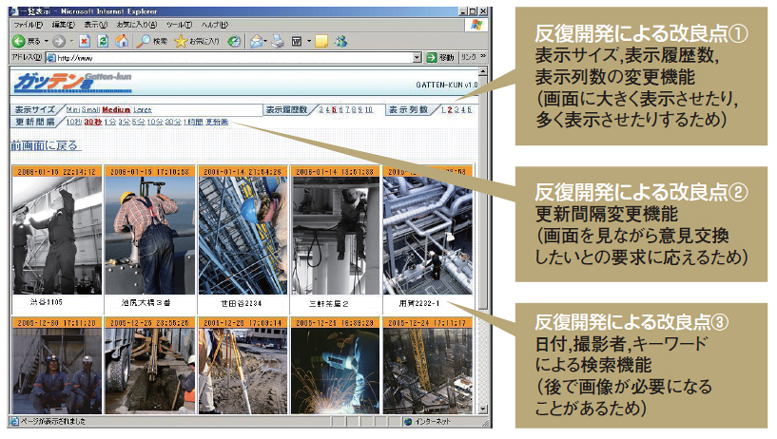 |
| 図6●日本コムシスは“業務が分からない”という壁を反復開発で乗り越えた 工事現場の業務効率化を支援するシステム「ガッテン君」の開発を反復型に方針転換し,エンドユーザーの使い勝手を高めていった。画面/ロジック作成とユーザー・レビューを繰り返した。開発言語も,Javaから修正が容易な簡易言語PHPに変更した。写真は実際と異なる [画像のクリックで拡大表示] |
できることは何でもやる
開発だけでなく,システム運用でも試す力は重要である。その有無は障害時に顕著に表れる。日本旅行の山本康二郎氏は「できることは何でもやろう」と,復旧までの時間を短くするための監視の仕組み作りを試行してきた。
以前は度重なるシステム障害に悩まされていた。小規模システムからスタートしたWebサイト「旅ぷらざ」は,アクセス数が増えるに伴いダウンする回数が増えた。しかも,障害個所を特定するのに時間がかかった。
そこで,システム監視を急ピッチで充実させた。ping,http,エラー・ログの常時監視。CPU使用率,ネットワーク負荷,ディスク容量,プロセス死活のログを1日1回バッチ処理により取得。さらに,障害個所を特定しやすいよう監視方法を工夫した。
旅ぷらざでは,JServのコンテナ・モジュールの中に八つのアプリケーション・グループを設定し,ラウンドロビンで振り分けている。障害が起きると,従来は八つのアプリケーション・グループに一つずつURLを手動で入力して,どれがダウンしているか確認しなければならなかった。
今はアプリケーション・グループ単位で死活を自動監視するようにしてある。アラートが上がった時点でダウンしている個所が分かる。「だいたいの障害は5~10分で切り分けられるようになった」(山本氏)。
4~5カ月かかるはずだったテスト期間を2カ月に圧縮した朝日新聞社と東芝ソリューションの工夫 (1)テストの項目の削減,(2)複数のテストの統合,(3)同時に実施できるテストの整理,を実施した



















































