サーバー全体の多重化
99.999%以上(年間平均停止時間5分以下)の可用性を目指すときは,サーバー全体の多重化を検討する。ハードウエアに加えて,ソフトウエアの障害に対応するときも,サーバー全体の多重化が不可欠である(図1)。
 |
| 図1●主なサーバー全体の多重化技術とその効果 [画像のクリックで拡大表示] |
このうち進歩が目立つのは,多重化サーバーだ。基本的に2台分の部品が同期して動作する仕組みになっており,どの部品が故障してもサーバーは稼働を続ける。ハード障害ならサービス停止時間はゼロか数秒とほとんど無視できるくらい短い。多重化サーバーでは,全く同じ処理を複数の系統で実行している。障害時は部品を切り離すだけだからだ。
OSから上のソフトウエアには変更を加える必要がないため,オープン化に対応しやすいのも利点である。
多重化サーバーは仕組み上ハードウエア障害にのみ対応する。ただし,システム管理ソフトと組み合わせることで,再起動すれば直るレベルのソフトウエア障害にも対応できる。その上で,ソフトウエア障害へ本格的に対応したい場合は,多重化サーバーをベースにHAクラスタを組むという構成にすることも可能だ。
多重化サーバーに二つの流れ
多重化サーバーには,当初は多重化を意識していなかったPCの仕組みを発展させたものと,最初から多重化を意識して作っていたメインフレームの技術を取り入れたものがある。
PCを発展させたタイプの多重化サーバーは,2台のPCサーバーが同期して動作し,障害時に片方を切り離すようなイメージである。OSを含めたソフトウエアに標準製品が利用できる上,コストも150万~200万円からと中規模PCサーバー並みである。
NECと米Stratus Technologiesは協業によって,独立して構成された2台分のハードウエアをクロック・レベルで同期させる仕組みの多重化サーバーを提供している。
図2(1)は,NECのExpress5800/ftサーバのシステム構成である。二つのCPU/IOモジュールとRAID1構成のディスク・ユニットから成る。例えば,CPU/IOモジュール#1に障害が発生すると,それが切り離されて,#0だけで稼働が続く。運用担当者は稼働中に#1をモジュールごと交換できる。モジュール交換後の再同期も自動である。「Express5800/ftサーバを複数用いてHAクラスタを組む構成も利用可能」(NEC)という。
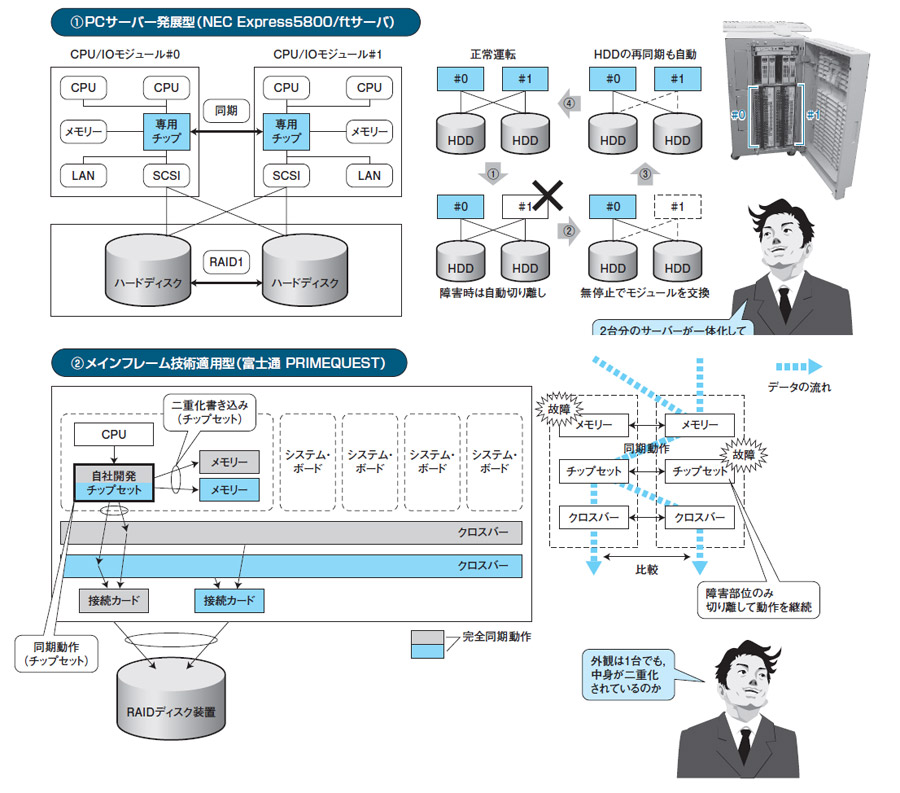 |
| 図2●二重化したサーバーの仕組み [画像のクリックで拡大表示] |
富士通は,これと似た仕組みをソフトウエアで実現した「PRIMERGY高信頼FTモデル」を用意している。標準のPRIMERGYサーバー2台をセットにして,米Marathon Technologies製のミドルウエアを使う。同期は,I/Oのタイミングなどチェックポイントという単位で行う。
基幹サーバーは1台の中で多重化
基幹業務を対象にしたハイエンド・サーバーは,メインフレームの技術を採用して多重化を進めていることが多い。メインフレームはハードウエアが故障する前提で設計され,各種多重化技術が発展してきた。それを最近の基幹業務向けサーバーに適用している。
例として富士通PRIMEQUESTの仕組みを図2(2)に示した。メモリー,チップセット,クロスバーといったデータの転送を支える部品がすべて二重化され,それぞれが同期により同じ処理をしている。障害があれば,そこを回避するようなデータの流れに切り替わり,稼働を継続する。CPUはシステム・ボードという単位で多重化できる。
この方式の利点は,柔軟性である。PRIMEQUESTでは,「2系統備えたハードウエアを2倍のリソースとして性能向上に利用することも可能」(富士通)という。動作モードを変えて,二重化する範囲を選べるようにもなっている。
三重化では演算ミスを検出可能
可用性をさらに上げていくときには,三重化されたサーバーを検討する。三重化なら同じ機能の部品が二つ壊れても稼働を続けられる。
さらに三重化には多数決方式でエラーを訂正できるという利点がある。二重化は,2系統ある部品のうち一つが機能しない障害には対処できるが,各系統が異なる演算結果を出す障害のときは処理をやり直すしかない。
HP Integrity NonStopサーバではプロセッサ・モジュールを三重化できる(図3)。このとき,同じ演算を3系統で処理して,2系統の結果が一致すれば,それを正しいと見なす。「三つとも異なる結果になるのは天文学的に少ない確率になる」(日本HP)。同サーバーはOSにも独自の工夫が盛り込まれており,三重化の場合,99.99999%以上(年間平均停止時間3秒以下)の可用性を実現できるとしている。
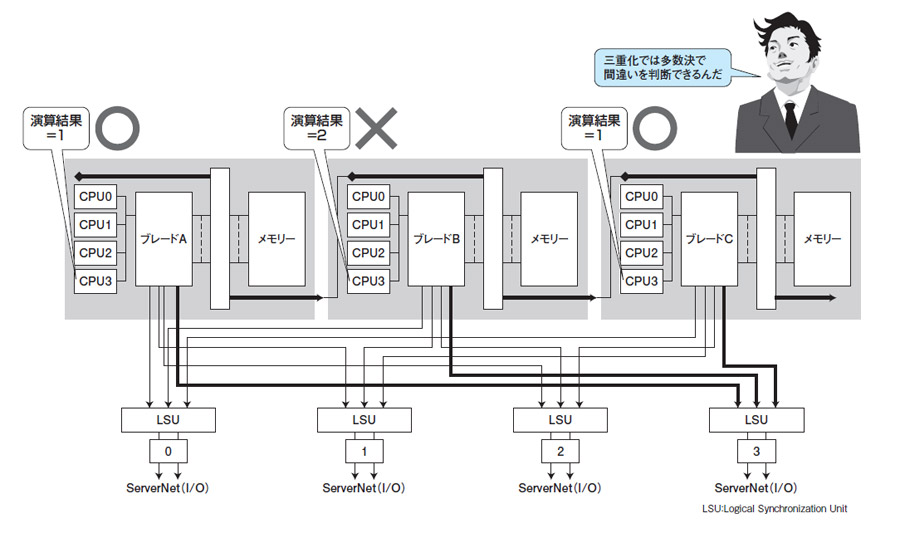 |
| 図3●三重化したサーバーの仕組み(HP Integrity NonStopサーバ) [画像のクリックで拡大表示] |
ただし,三重化はかなりのコストがかかるのが難点である。そこで二重化のまま各系統が異なる結果を出すエラーに対処しようという動きもある。コンピュータのエラーには,データ自体のエラーと,データがある場所を示すアドレス指定などコントロール部分のエラーがある。富士通のPRIMEQUESTは「この両者についてエラーを検出することで二重化のまま信頼性を高めている」(富士通)。
ソフトウエア障害はクラスタで
ソフトウエアの障害に対応するときは,HAクラスタやコールド・スタンバイといったサーバー全体の多重化技術を使う。多重化サーバーの進歩は目覚ましいものの,システム利用者はアプリケーションまでの可用性を求めていることを忘れてはならない。
HAクラスタは現状でもアプリケーションを含めたシステム全体の可用性を高める最も効果的な技術である。アプリケーションの構成までを基本的に同一にした複数のサーバーにクラスタ・ソフトを導入して構築する。通常はその中の一つのマシンを本番系として使用し,障害時は予備系のシステムに切り替える仕組みだ。
クラスタの課題は予備システムへの切り替えに数分以上の時間がかかることだが,着実に改善している。
例えば日立製作所は,最短で十数秒から30秒にする技術を開発した。「OSの障害をほぼ瞬時に予備システム側に通知する仕組みと,予備システムで切り替え先となるソフトウエアを起動寸前の状態にする技術を連携して切り替え時間を短縮した」(同社)という。日立のデータベース・ソフト「HiRDB」などを使うと実現できる。



















































