世界中のさまざまな文字を符号化しているUnicodeには、さまざまな特徴があります。
その特徴の1つに結合文字があります。
たとえば、「が」は「か」を表すU+304bと濁点を表すU+3099を用いて、U+304b U+3099と表すことができるのです。
これ以外にも半濁点や、ドイツ語のウムラウトなども同じように結合文字で表すことができます。
「が」を表すU+304cと、「か」+濁点のU+304b U+3099を表示しても、外見上の違いはありません。問題は結合文字ともともとの文字を同じものとして扱えるかどうかということです。
このような結合文字はコードとしては同じではありませんが、文字の扱いとしては同じものとして扱うことができます。これを等価(Equivalance)といいます。特に結合文字などの合成列の場合、同一視することが可能です。このような文字を正規等価(Canonical Equivalace)といいます。
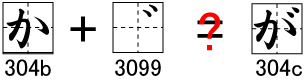 |
| 図1 正規等価 |
|---|
次の例を考えてみましょう。いわゆる半角カナです。
全角のカナの「ア」と半角カナの「ア」は同じ文字と考えられるでしょうか。
全角と半角では見た目はかなり違います。見た目が異なるので、正規等価とは呼ぶことができません。しかし、指し示している文字は同じです。
このような場合、互換等価(Compatibility Equvalance)と呼びます。
ここで示したように、Unicodeでは正規等価と互換等価という2種類の文字の等価性を扱います。
このため、実際に文字列を比較する場合、比較できるように文字列を正規化する必要があります。
文字列の正規化には次にしめす4種類の形式があります
- 正規分解 Normalize Function Decomposite (NFD)
- 互換分解 Normalize Function Compativle Decomposite (NFKD)
- 正規合成 Normalize Function Composite (NFC)
- 互換合成 Normalize Function Compativle Composite (NFKC)
正規分解は正規等価の文字を分解していくことです。たとえば、文字列中に「が」があれば「か」+濁点に分解します。
そして、分解した文字の順序の一意性を保証するために、並び替えを行ないます。2つの部分に分解できるものであれば順序の並び替えは必要ありません。しかし、複数の部分に分解できる文字もあるため、このような並び替えを行ないます。
互換分解は正規分解と共に互換等価な文字を置き換えていきます。たとえば、文字列中に「ア」があれば、「ア」に置き換えます。
正規合成は正規分解した文字列を再び合成することです。また、互換合成は互換分解をした文字列を正規合成することになります。
Javaにおける文字列の正規化
Javaで文字列の正規化を行なうのが、Java SE 6で導入されたjava.text.Normalizerクラスです。
Normalizerクラスはたった2つのメソッドしか定義されていません。しかも両方ともstaticなメソッドなのです。
さっそく使い方をサンプルで見ていきましょう。
| サンプルのソース | NormalizerSample1.java |
|---|
Normalizerクラスには正規化を行なうnormalizeメソッドと、正規化されているかどうかをチェックするisNormalizedメソッドが定義されています。
両方のメソッドとも第1引数の型はCharSequenceインタフェース、第2引数が正規化の形式を列挙型にしたNormalize.Formです。
サンプルではnormalizeメソッドを使用しています。
private void normalize(String text) {
// オリジナルの文字列
System.out.print(text + ": ");
printHex(text);
// 正規分解
String normalizedText = Normalizer.normalize(text, Normalizer.Form.NFD);
printHex(normalizedText, Normalizer.Form.NFD);
// 互換分解
normalizedText = Normalizer.normalize(text, Normalizer.Form.NFKD);
printHex(normalizedText, Normalizer.Form.NFKD);
// 正規合成
normalizedText = Normalizer.normalize(text, Normalizer.Form.NFC);
printHex(normalizedText, Normalizer.Form.NFC);
// 互換合成
normalizedText = Normalizer.normalize(text, Normalizer.Form.NFKC);
printHex(normalizedText, Normalizer.Form.NFKD);
System.out.printf("%n");
}
StringクラスはCharSequenceインタフェースをインプリメントしているので、そのままnormalizeメソッドの第1引数にすることができます。赤字で示した部分が正規化の形式です。
normalizeメソッドの戻り値の型はStringクラスになります。
printHexメソッドは16進数で文字列を表示するメソッドです。いちおうソースを示しておきます。
private void printHex(String text, Normalizer.Form form) {
System.out.printf("%4s: ", form);
printHex(text);
}
private void printHex(String text) {
for (char c: text.toCharArray()) {
System.out.printf("%x ", (int)c);
}
System.out.printf("%n");
}
それでは、実行してみましょう。まず、正規等価のもじ、「が」と「か」+濁点を正規化してみました。
が: 304c NFD: 304b 3099 NFKD: 304b 3099 NFC: 304c NFKD: 304c か?: 304b 3099 NFD: 304b 3099 NFKD: 304b 3099 NFC: 304c NFKD: 304c
「か」の後が?になっているのは、濁点は結合文字用であって対応するフォントがないためです注。
「が」も「か」+濁点も正規分解、互換分解でU+304b U+3099となっていることが分かります。また、正規合成、互換合成はU+304cになります。
では互換等価の「ア」と「ア」はどうなるでしょう。
ア: 30a2 NFD: 30a2 NFKD: 30a2 NFC: 30a2 NFKD: 30a2 ア: ff71 NFD: ff71 NFKD: 30a2 NFC: ff71 NFKD: 30a2
「ア」は正規化しても変化はありません。一方の「ア」は正規分解、正規合成ではU+ff71のままです。
したがって、「ア」と「ア」を比較するためには互換分解もしくは互換合成が必要なことが、この結果からも確認できます。
文字列を比較する場合でも、必要に応じて正規化することを心がけるようにしましょう。
注:「゛」と結合文字用の濁点は異なるコードが割り当てられています。「゛」はU+309b、結合文字用の濁点がU+3099となります。
参考
Unicode Standard Annex #15: Unicode Normalization Forms
|
著者紹介 櫻庭祐一 横河電機 ネットワーク開発センタ所属。Java in the Box 主筆 今月の櫻庭今年もあっという間に時間はすぎ、早くも年末となってしまいました。 年末といえばもちろんクリスマス。今年は23日、24日と連休なので、どこも混雑するでしょうね。 とはいえ櫻庭にとって関心があるのは、なんといってもクリスマスケーキ。 去年はPierre Herméの定番ケーキであるイスパハンをモチーフにしたBûche Ispahanを食べてみました。バラの香りがおいしさを誘うケーキなのです。 今年もすでに予約を完了しているので、いまから食べるのが楽しみです。何を予約したかは内緒(笑)。 最近ではドイツのシュトーレンやイタリアのパネトーネも売られていますね。しかし、これはまだほとんど知られていないのではないでしょうか。 デンマークでクリスマスなどのお祝いの日に食べられれているカイングラです。 クロワッサンのようにバターを多く使った生地にフルーツやチョコレートが添えられたパンをデニッシュといいますが、これはデンマークのパンということです。 このデニッシュの特大版がカイングラ。サクサクの生地にカスタードとレーズンが加えられていてとってもおいしいのです。そのうち、日本でもはやるかもしれませんね。
なお、今月もサン・マイクロシステムズ奥津正義氏および神谷結花氏に多大なるご協力をいただきました。この場をかりてお礼させていただきます。 |






















































