 |
システムを運用する上で避けて通れないのがデータのバックアップである。ストレージ・システムの信頼性を向上するRAIDや分散ストレージなどの技術は,年々機能や性能を上げ,ディスク・ドライブ自体の障害に対する耐性は高まっている。しかし,システム全体がクラッシュした場合,もしくはファイル・システム,データ構造,DBインデックスなどに不整合が生じた場合は,過去に整合が取られていた状態から復旧しなければならない。バックアップの必要性はいまだに失われていない。ただ,バックアップの運用の仕方によっては,大きな被害を被ることがあることを知っておきたい。
システム管理者が錯覚を起こす
ストレージのレプリケーション機能を使う,DBMSのログ・シッピング機能を使うなどバックアップにもバリエーションが増えてきたが,今なお主流なのはバックアップ・ソフトを使ったデータのコピーである。バックアップ・ソフトはディスク上のデータ構造をアーカイブ(すなわちシーケンシャル・データ)に変換し,別の記録媒体に待避させる。バックアップするデータとその記録先,時間などを設定しておけば,自動的にバッチ処理をしてくれる。
バックアップ・ソフトを利用すると,運用担当者は直接バックアップの実行を行う必要がない。そうすると,日々のバックアップ状況の確認をしなくなっていく。また,バックアップ完了イベントをメールで運用担当者に送るケースが多いが,毎日毎日機械的なメール・レポートを受け続けると,いずれ,そのメールは運用担当者の“脳内フィルタリング”に引っかかり,いつしかメール・ホルダーに格納されたまま,運用担当者の目に届かなくなっていく(図)。このようにバックアップ作業をツールによって完全に自動化していると,運用担当者は知らず知らすのうちにバックアップ・ツールを信頼し,バックアップは毎日正常に取られているかのような錯覚を起こす。
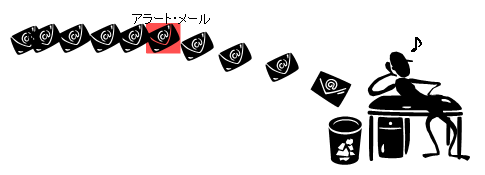 |
| 図●アラート・メールに気づかなくなる |
しかし,バックアップの失敗は意外に多い。テープ・デバイスやバックアップ側ディスク・ストレージ・システムの故障,メディアの劣化,ファイル・システムの不整合,バックアップ・プログラムのバグや問題,メモリーやディスク入出力などシステム・リソースの不足,アプリケーションからの割り込みなどによってバックアップが失敗していたり,途中でサスペンドされていたりすることはよく発生しているのである。
ディスクのセクター障害やドライブ,メディア障害などの恒常的な理由によってバックアップが中断した場合,再度バックアップが実行されても同じ場所で異常停止してしまう。つまり,いつまで経っても完全なバックアップが取られないままに放置されてしまうのだ。さらに,こうした障害でバックアップが不完全な状態にあるときに限って,システム運用者が多忙を極め,ついつい放置されたまま時が過ぎ,システムがクラッシュした時に初めてバックアップが完全に取られていないという事実が判明するのである。
「完了確認」イベントが必須
現在でも,バックアップ作業はシステム管理上,非常に重要な業務である。しかし,最もおろそかに運用される業務でもある。ここで話題にしているのは,バックアップ・ソフトの無意味さを主張しているのではない。煩雑なバックアップ業務をツールを使って効率化すれば,業務負担を軽減し,コスト削減にもなり得る。
バックアップの安定した運用を継続し,敏速な復旧対応の実現を目的としてバックアップ・ツールを導入することは有益であるが,もっと重要なことはシステム運用フローに「バックアップ完了確認」というイベントを含ませることである。自動バックアップ・ツールだけを信じてはいけない。必ず目視で運用担当者がバックアップ状態を確認することと,その担当者のアサインが必要だ。
システムが安定している限り,バックアップ完了確認は無駄な業務と思われがちだ。不思議なことに,このような単純な作業を順守していると,ストレージの障害は発生しないものである。しかし,最も単純な作業であるが故に軽視し,確認を怠ると,途端にストレージなどはクラッシュするものなのだ。クラッシュしてしまうと,自動化ツールも監視ソフトも無力である。唯一運用担当者の責任感によって対応するしか術が無い。
|



















































