Webシステムのパフォーマンスを管理するには,「設計→実装→検証→対処→設計に戻る」というサイクルを回すと説明した。今回と次回ではこのサイクルの中でも特に重要な,「設計」と「検証」の実践法を説明する。具体的には,設計時にネットワーク帯域やサーバー機のスペック,台数などを見積もる「キャパシティ・プランニング」と,検証時にパフォーマンスを実測して確かめる「負荷テスト」のポイントを示す。
キャパシティ・プランニングの実践
「1秒当たり100件のリクエストを処理する」というスループット要件があるとしよう。さて,このWebシステムのネットワーク構成やサーバー構成をどう決めればいいのだろうか?
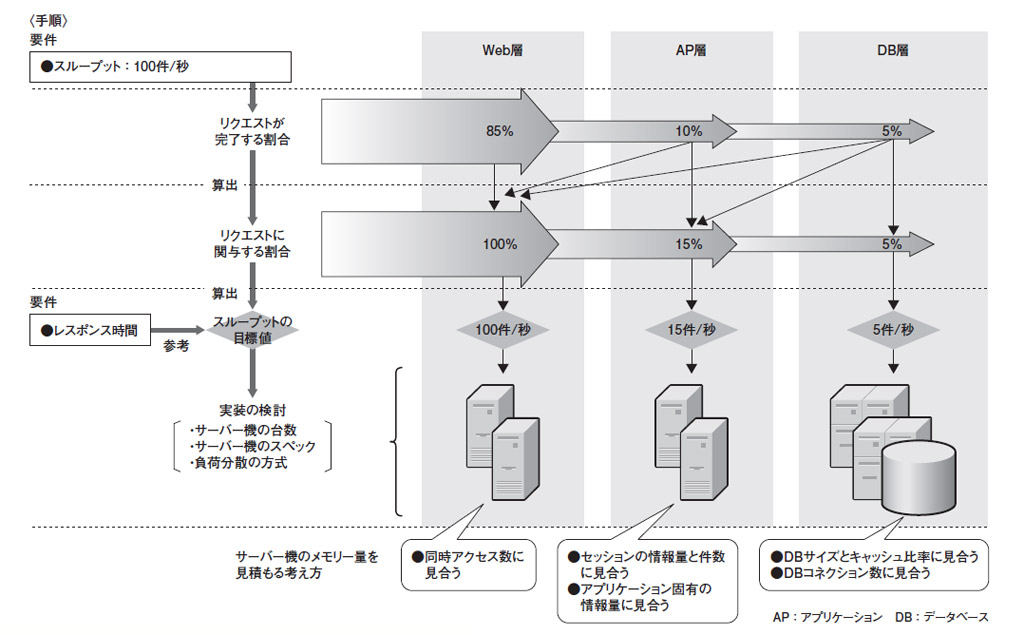
まずは,アプリケーションの特性を見極めて,「Web層」「AP層」「DB層」のどこでリクエストが完了するかの割合を把握する。DBアクセスを伴うリクエストはAP層を経てDB層で完了するが,静的なHTMLページを返すだけならWeb層でリクエストが完了する。
ここでは全リクエストのうち,5%はDB層で,10%はAP層で,そして残りの85%はWeb層でリクエストが完了すると試算したと考えよう(図1)。この割合が分かれば,各層がリクエストに関与する割合は単純計算で導き出せる。Web層はシステムの入り口になるので,関与するリクエストは100%。AP層はDB層とAP層を合わせた15%。DB層は5%となる。
 |
| 図1●キャパシティ・プランニングの手順とポイント システムに対する要件を基に各層でどの程度の処理が発生するのかを予測し,各層のスループットの目標値を計算する。目標値を達成できるように,サーバー機のスペックや台数,負荷分散の方式などを検討する [画像のクリックで拡大表示] |
次に,リクエストに関与する割合から,各層でのスループットの目標値を計算する。Webシステムのスループット要件は「1秒当たり100件」なので,Web層はその100%分で100件/秒,AP層は15%分で15件/秒,DB層は5%分で5件/秒のスループットを満たす必要がある。このように考え,各層のスループットの目標値を決める。
用途ごとに重点リソースが異なる
層ごとのスループットの目標値が定まったら,ネットワークやサーバー機などの構成を検討する。具体的には,ネットワーク帯域,サーバー機のスペックと台数,サーバー機の負荷分散方式――などが検討事項となる。以下では,サーバー機の選定を例に説明する。
Webシステムのどの層で利用するサーバー機かによって,選定時に重視すべきリソース(CPU,メモリー,ディスク入出力など)は異なる。一般に,WebサーバーはCPUとネットワーク入出力を多用するので,それらのリソースを重視する。APサーバーはアプリケーション・プログラムを動作させるので,CPUとメモリーを多く使う。DBサーバーの場合は,CPU,メモリー,ディスク入出力を多く必要とするので,それらを十分に備えたサーバー機を選定する。
必要なリソース量を見積もる方法は3種類ある。(1)類似事例から推測する方法,(2)標準的なベンチマーク手法に基づいた結果から推定する方法,(3)スペシャリストの経験に依存する方法――である。
(1)類似事例から推測する方法では,過去に構築したよく似たシステムや同規模システムでの機材や構成を参考にする。過去の事例に基づくと,サーバー機のスペックが様変わりしているなど簡単には類推できない場合もあるが,まったく比較材料のない状態から見積もるよりは容易で,精度も上がる。
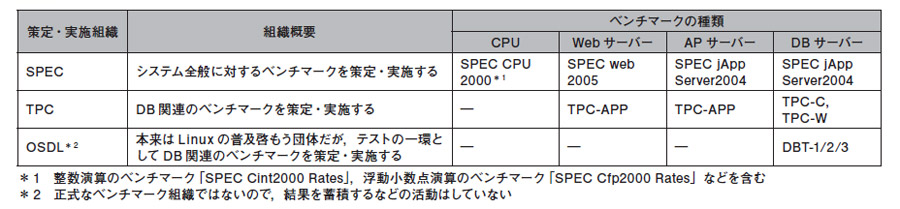
(2)標準的なベンチマーク手法に基づいた結果から推定する方法は,精度の高い見積もりを実施できる。ベンチマーク用に開発されたアプリケーションを実際のサーバー機で稼働させ,どのくらいのスペックの場合にどのくらいのパフォーマンスだったのかをデータとして蓄積,そのデータを基に見積もる。機材や費用の都合で自前で実施できない場合は,見積もり精度は落ちるが,信頼できる組織が実施・公表しているベンチマーク結果を参照するとよい。
(3)スペシャリストの経験に依存する方法とは,いわゆる「KKD(勘,経験,度胸)」による見積もりである。さまざまなシステム構築を経験してきたスペシャリストの中には,かなりの精度でサーバー機のスペックを見積もれるスキルの持ち主がいる。見積もり根拠を示すことは難しくなるが,こうしたスペシャリストのスキルに頼るのも一つの方法であろう。
ベンチマーク結果を基に同等性能の機器を探す
キャパシティ・プランニングの具体例として,(2)の標準的なベンチマーク手法による結果から推定する方法を示したい。ここでは実機を使って測定するのではなく,公開されている情報に基づく方法を説明する。
前提条件として,Web層とAP層は分けない,DB層はシングル・サーバー構成,いずれもIA(Intel Architecture)32のサーバー機を採用,とする。そして,スループットの目標値は前述したものと異なるが,Web層が100件/秒,AP層が80件/秒,DB層が10件/秒とする。
Web層+AP層を動作させるサーバー機の場合,標準的なAPサーバーのベンチマーク「SPEC jAppServer2004」が参考になる。前提条件としてWeb層とAP層を1台に同居させることなどから,jAppServer2004の値が,AP層のスループットの目標値(80件/秒)を5倍以上,上回るサーバー機を探す。
公開されているjAppServer2004のベンチマーク結果を探したところ,「HP Integrity rx4640(Itanium2 1.6GHz)」(SPEC jAppServer2004の値が471.28件/秒)が見つかったので,このサーバー機を基準に,同等の処理能力を有する機器を探す。具体的にはサーバー機の整数演算能力を示すベンチマーク「SPEC Cint2000 Rates」の値を使う。rx4640のSPEC Cint2000 Ratesの値は72.5件なので,例えば同37.9件の「Dell PowerEdge 830(Pentium D 3.4GHz)」の場合は,2台(72.5÷37.9≒1.9)用意すれば,1台のrx4640と同等の性能になると考えられる。
DBサーバーも同様に選定できる。スループットの目標値は10件/秒なので,rx4640の10分の1程度のスペックで十分である。公開しているSPEC Cint2000 Ratesの値を調べたところ,CPUに「Pentium 4 2.5GHz程度」を搭載したサーバー機(SPEC Cint2000 Ratesの値が10件程度)1台が候補となった。
このように,公開されたベンチマーク結果を活用することで,手元に事例やデータを持たなくても,見積もり精度は高められる。ただし,見積もり過程で推定している部分があるので,検証は不可欠だ。ベンチマークとして参考になるデータには,表1で示したもののほかに,「オープンソース情報データベース」などがある。本誌に掲載されているコラム「検証ラボ」のデータも,参考にできる場合がある。
| 表1●Webシステムのパフォーマンス評価に使える標準的なベンチマーク手法 [画像のクリックで拡大表示] |
 |
2種類に大別できる負荷分散方式
サーバー機の台数が2台以上であれば,リクエストを振り分ける方式を検討しなければならない。大別すると「DNSラウンドロビン」を利用する方法と,「ロード・バランサ」を利用する方法がある。
DNSラウンドロビンは,DNSを使ってリクエストを分散させる方法である。DNS上で一つのホスト名と複数のWebサーバーのIPアドレスを関連付けると,ホスト名の解決を求められるたびにDNSがIPアドレスを順番に切り替えて返す仕組みを利用する。この方法は,DNSだけで実装できる手軽さが魅力だが,サーバー間の負荷が偏りやすい弱点がある。負荷が偏る主な理由は,クライアントにIPアドレスがキャッシュされるのでリクエストのたびに負荷を振り分けられないことと,Webサーバーの負荷の実態とは関係なくリクエストを振り分けてしまうことだ。
一方のロード・バランサとは,複数のWebサーバーにリクエストを振り分ける仕組みを備えている専用の装置またはソフトである。ロード・バランサには,複数台のWebサーバーで共有する「仮想IPアドレス」を割り当てる。クライアントは,この仮想IPアドレスに向けてリクエストを送信する。ロード・バランサは,リクエストとして受け取ったパケットを解析(図2の(1))し,その振り分け先を決める。振り分け先は,ロード・バランサに搭載された振り分け先制御機能(同(2))と分散方式(同(3))に従い決定する。(2)で振り分け先を絞り込み,候補が複数ある場合に(3)で1台に特定する。振り分け先のサーバー機が決まったら,パケットの送信先IPアドレスやポート番号をそれに合わせて書き換え(同(4)),転送する。レスポンスは逆の経路をとり,ロード・バランサ上でパケットを書き戻してクライアントに返信する。
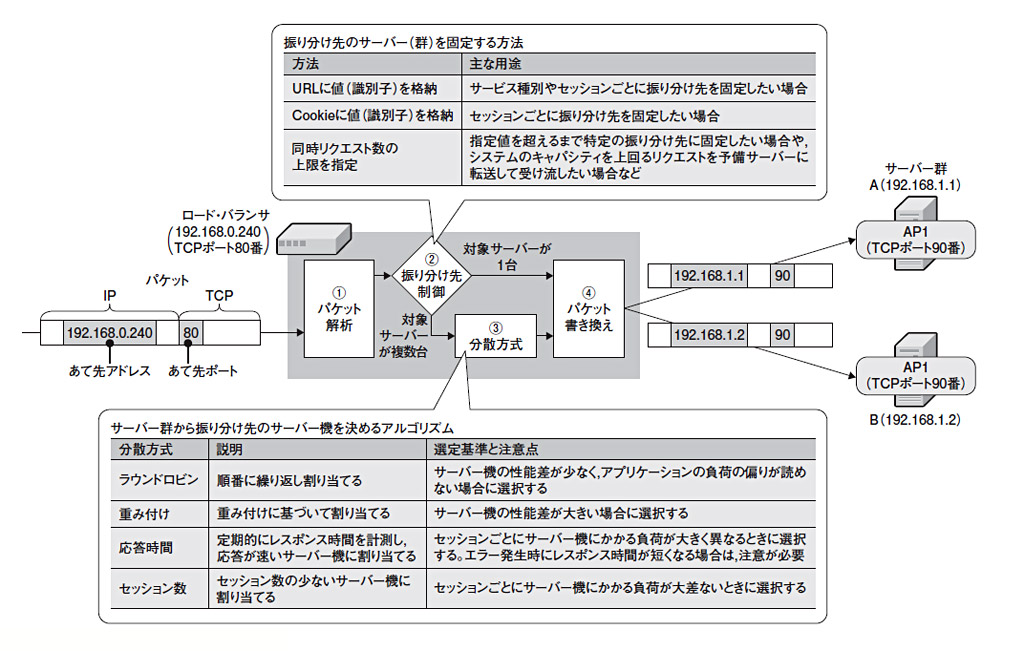 |
| 図2●ロード・バランサの仕組み ロード・バランサは,(1)パケットを解析し,(2)振り分け先のサーバー(群)を判定し,(3)サーバー機の負荷が均等になるように振り分け,(3)振り分け先に届くようにパケットを書き換える――という四つの機能で成り立つ(製品によっては(2)と(3)を区別しない) [画像のクリックで拡大表示] |
ロード・バランサの設定上で注意すべき点は,振り分け先制御機能の使い方と,分散方式の選定である。これらをうまく設定することで,Webサーバー間の負荷の偏りを減らしたり,同時リクエスト数の上限を超える過剰なアクセスを予備サーバーに逃がして「混雑中です」というメッセージを返したりと,きめ細かな制御ができる。
|



















































