上流工程から繰り返し検証
実装後はパフォーマンスの変化を計測し,利用者の要件を満たしているかどうかを検証する。検証はソフトウエア構成とハードウエア構成に対して実施する。
ソフトウエア構成の検証とは,ソフトウエアの設計や実装がパフォーマンスに悪影響を及ぼしていないかどうかをチェックすることだ。このチェックは,システム開発工程の早いタイミング(上流工程)から繰り返し実施するようにしたい。
例えば,筆者が参加したある開発プロジェクトでは,総合テストの段階になってようやく,特定のプログラムのレスポンス時間が異常に遅いことに気づいた。調査すると,メモリー経由で渡すはずのデータが,ディスク経由で渡されていた。プロジェクトの初期段階で「データはメモリー渡し」と規定していたが,そのプログラムの開発を担当したチームがルール違反していたのだ。結局,メモリー渡しになるようにプログラムを修正することで,システムは無事にリリースできた。こうした問題は本来なら,詳細設計書やソースコードのレビューで見つけておくべきだ。
一方,ハードウエア構成を検証するには,開発段階なら本番と同等の環境で負荷テスト,運用段階なら実環境で性能監視を実施して,レスポンス時間やスループットを実測する。負荷テストは,システムがほぼ組み上がった総合テストの段階で実施する。一般的には負荷テスト・ツールを使い複数のリクエストを同時に送信し,要件を満たしているかどうかを調べる。
ボトルネックに対処する
負荷テストや性能監視の結果,要件を満たしていないことが分かったら,ボトルネックを洗い出して対処することで,パフォーマンスを改善する。図1は,Webシステムに潜むボトルネックの具体例である。
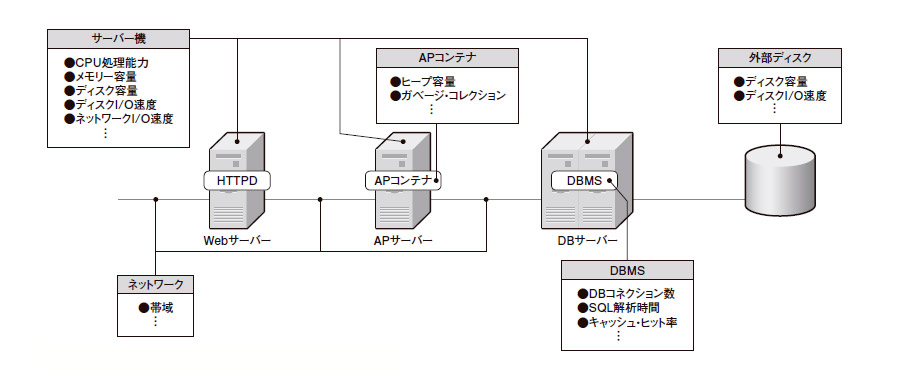 |
| 図1●Webシステムに潜むボトルネックの例 ボトルネックになりやすい個所は多岐にわたる。原因が一つである保証もない。パフォーマンス上の問題が発生した場合は,各種のログや実測データに基づき,原因個所を切り分け,全体のバランスを見ながら改善する必要がある [画像のクリックで拡大表示] |
まず,検証結果から,パフォーマンス劣化の原因となっている物理的な場所を推定する。Webシステムの場合は,大まかにいえば,ネットワーク(LAN/WAN/インターネットなど)か,サーバー(Web/AP/DBサーバーなど)のどちらかに原因があるはずだ。
サーバーに原因があると推定される場合は,OSやミドルウエア(HTTPD/APコンテナ/DBMS),アプリケーションのログなどを突き合わせ,さらにボトルネックを絞り込む。ボトルネックを特定できたら,ミドルウエアやOSのパラメータをチューニングする。場合によっては,ハードウエアの構成を変更したり,アプリケーションのロジック(アルゴリズムやSQL文など)を見直したりもする。
パフォーマンスのチューニングは,各パラメータや構成がパフォーマンスにどんなインパクトを与えるのかを熟知していないと適切に実施できない。例えば,メモリー上にキャッシュするデータ量を増やせば,そのデータに対する検索などのパフォーマンスは向上するだろうが,メモリーの空き容量が減る分だけ,ほかのアプリケーションの動作に影響が出たり,同時リクエスト数の上限が減ったりするかもしれない。こうしたシステム全体への影響度を考慮しながら,調整することが肝心だ。あるボトルネックを解消したら,別の個所が新たなボトルネックになることもある。
|



















































