パフォーマンスの指標
Webシステムに利用者からのアクセスが殺到すると,パフォーマンス上のトラブルが生じることがある。トラブルは,リクエストが受け付けられない,応答速度が低下するなどの現象として表れる。
こうした事態に陥ると,少なからぬ利用者が何度もリクエストを試みる。ただでさえ混雑しているWebシステムに何度もリクエストが送信されると,混雑状況はさらに悪化する。やがて,Webシステムの処理はサービスが停止して見えるほど遅くなり,ひどいときには実際にWebシステムそのものがダウンしてしまう。
Webシステムのサービスが停止して見えたり,実際に停止したりすることもあるために,パフォーマンスの問題は可用性の問題と混同しがちだが,技術的にはまったく別の問題であることに注意したい。システムの利用者や発注者から要件を聞き取るときには,両者を混同しないように整理すべきである。
必ず聞き取りたい二つのこと
利用者や発注者は,「できるだけ早く」「不満を感じない程度のスピードで」「リクエストが殺到しても大丈夫なように」――など,あいまいな言葉でパフォーマンスに関する要件を示す。技術者は,できるだけ具体的に要件を聞き出し,合意形成すべきである。
パフォーマンス上の要件を具体的に聞き出した例としては,次のようなものが挙げられる。「リクエストを送信してレスポンスが表示されるまでの時間は平均3秒以内,遅延時でも10秒以内」「1秒当たりのリクエスト数は100件以内」「90%以上の利用者がパフォーマンスに不満を持たない」――などである。
必ず聞き取るようにしたい指標が二つある。それは「レスポンス時間」と「スループット」だ。
レスポンス時間とは,Webクライアントがリクエストを送信してから,サーバーでそのリクエストを処理し,結果をレスポンスとしてWebクライアントで受け取るまでの時間である。利用者がストップウォッチを片手に自分で計測することもできるので,最も身近なパフォーマンスの指標と言えるだろう。
もう一方のスループットとは,単位時間当たりにサーバーで処理できるリクエスト数である。スループットはサーバー側でないと測定できず,利用者には分かりにくい指標なので,「同時リクエスト数の上限」で代用することも検討したい。リクエスト数の上限は,利用者の“要件”というより,システム上の制約に対する利用者の“許容範囲”を示す。
レスポンス時間,スループット,同時リクエスト数の上限という各指標には,相関関係がある。例えば,スループットの低いシステムは,同時リクエスト数が増えると,レスポンス時間が急激に低下する。なぜなら,同時リクエスト数が増えるにつれて,サーバー上での処理が間に合わなくなり,待ち時間が生じるからだ。こうした待ち時間は,「待ち行列」と呼ばれる理論で説明できる。
上流から下流まで改善続ける
聞き取ったパフォーマンスの指標は,開発段階で設計や実装に反映させるだけでなく,運用段階でも維持すべきだ。そのために開発から運用に至るライフサイクル全体で,設計→実装→検証→対処というサイクルを回すことが求められる(図1)。
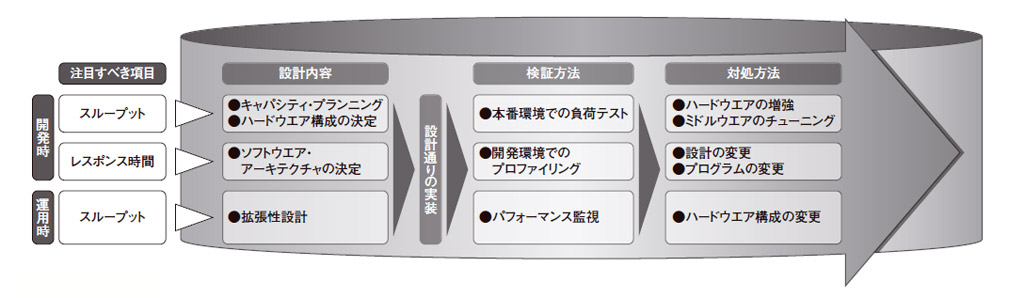 |
| 図1●パフォーマンス改善の取り組み パフォーマンスを一朝一夕に改善することは難しい。「設計→実装→検証→対処→設計に戻る」のサイクルを回して,徐々にパフォーマンスを向上させるのが現実的だ。開発時だけでなく,運用時にも,同様のサイクルを回すことが必要である [画像のクリックで拡大表示] |
パフォーマンスの設計
設計段階で考慮すべき重要なポイントは3点ある。
1点目は,ミドルウエアの設定やアプリケーションの構造などを要件に適合させること。最も慎重に考慮すべきなのは,サーバー機のリソース(CPUやメモリー,ディスクなど)をどう配分するかということだ。例えばアプリケーションからデータにアクセスする速度は,データがメモリーにあれば高速だが,ディスクにあると(メモリーに比べて)低速となる。そこで,基本的にはメモリー・アクセスを中心に設計し,やむを得ない部分だけはディスク・アクセスになるように構成する。メモリーという有限のリソースをうまく使うことが,技術者の腕の見せ所となるわけだ。
2点目は,必要十分なキャパシティのサーバー機やネットワーク回線を用意すること。「キャパシティ・プラニング」と呼ぶ作業をする。この作業では,どれくらいのキャパシティのサーバー機を何台用意するか,各サーバー機にリクエスト(=負荷)を分散する方法をどうするか――などを検討する。
3点目は,キャパシティを後から増減させる可能性を考慮しておくこと。システムの利用者数や使われ方は徐々に変わるので,稼働後にキャパシティを増やさなければならないことは多い。設計段階で拡張計画を立案し,パフォーマンスの計測法や,キャパシティの増強条件・方法などを明確にしておくべきである。
設計に基づき実装
パフォーマンスの設計を固めたら,それに従い実装する。実装作業の容易さは,設計時の拡張計画に大きく左右されるので,設計段階から実装には十分に配慮しておきたい。設計と実装は不可分の関係である。
サーバー機のキャパシティを拡張する場合で見てみよう。拡張方式の基本的な考え方には,サーバー機の単体処理性能を上げる「スケールアップ」と,台数を増やす「スケールアウト」の2種類がある(図2上の「物理マシンの場合」)。
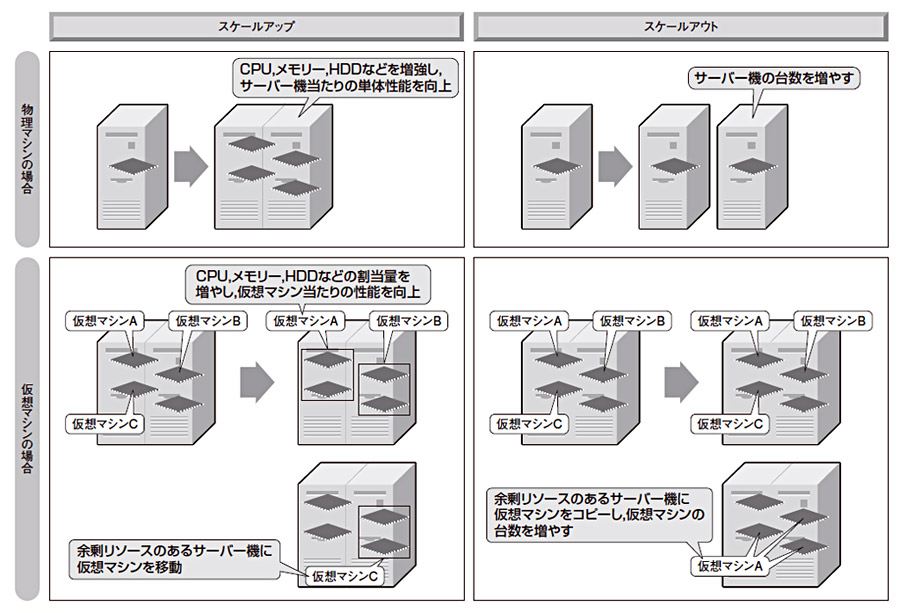 |
| 図2●キャパシティを拡張する際の,ハードウエア構成の変更方法は大きく2種類 サーバー機の単体性能を向上させる「スケールアップ」と,台数を追加する「スケールアウト」の2種類がある。それぞれ,物理マシンの性能や台数を変える方式と,サーバー仮想化技術を利用して仮想マシンの性能や台数を変える方式がある [画像のクリックで拡大表示] |
スケールアップの利点は,サーバー機のキャパシティが増えるだけなので,ソフトウエア構成に影響がないことだ。欠点としては,1台のサーバー機に搭載できるリソースに限りがあり,リソースの上限に達したら上位のサーバー機に置き換えなければならないという手間が挙げられる。それに,上位のサーバー機ほど価格が割高なので,構築費は高くなりがちだ。
これに対してスケールアウトは,そこそこの性能のサーバー機を並べるだけなので,サーバー機の費用は割安である。ただし,負荷分散が必要になるし,サーバー機の台数が増えるので運用管理コストは増加しがちという欠点がある。そのほかスケールアウトで注意しておきたいのは,ソフトウエアの設計上の配慮が必要なことだ。例えばWeb/APサーバーの場合,各サーバーでセッション情報を共有できるようにするか,特定クライアントからのリクエストを負荷分散装置で判別して振り分け先のWeb/APサーバーを固定するなど,構成を工夫する必要がある。
最近では,サーバー仮想化技術を適用して仮想マシンを構成することで,物理マシンでスケールアップやスケールアウトする場合よりも,柔軟性を高められるようになっている(図2下の「仮想マシンの場合」)。
仮想マシンとは,サーバー機のエミュレータ機能を持つソフトやOSで作り出した疑似サーバーだ。仮想マシンには,物理マシンと同様のOSやミドルウエア,アプリケーションをインストールして動作させる。仮想マシンのスケールアップではリソースを柔軟に増減できるし,物理マシン間の移動も容易になる。仮想マシンのスケールアウトでは,仮想マシンが複数必要になっても1台の物理サーバーにまとめることで,物理マシンのスケールアウトより運用管理コストの削減が見込める。
|



















































