並び順で実質的にノイズ減らす
検索語と一致した検索結果を順不同で並べただけでは,検索結果の件数が多い場合,利用者が求める情報にたどり着くまでに時間がかかる。そこで,利用者が求めているであろう情報をより上位に,ノイズの可能性が高い情報をより下位に,並べ替えて表示する仕組みが重要になる。この仕組みにより実質的にノイズが減り,利用者は情報を効率よく探し出せる。この仕組みを「ランキング」と呼ぶ。
ランキングは,何らかの評価軸に基づいて検索結果に点数をつけ,点数の高い順に並べ替えることで実現する。どの製品もランキングの仕組みを備えているが,評価軸や加点方式は製品ごとに異なる。製品によっては,点数の代わりにデータの作成日や作成者名などで並べ替えられる場合もある。
評価軸は単純化すると,「検索語を含むデータが,どこからどれだけ参照(リンク)されているか」(ここでは便宜上「リンク解析方式」と呼ぶ)と,「検索語が何回,どのくらいの密度で登場するか」(同「密度解析方式」と呼ぶ)に分けられる。
リンク解析方式は,Google検索アプライアンスなどに採用されている。米Googleが同社のインターネット検索サービスに実装したことで脚光を集めた方法で,主にHTMLデータのランキングに使う。被リンク数やリンク元の点数などを加味して点数付けするが,検索対象はWebシステムに限られる。
一方の密度解析方式は,検索対象のデータ形式に依存しないメリットがある。サイバーソリューションズの「CyberFinder」の場合,検索語が登場した回数,近さ,場所,データ・サイズなどを考慮してランキングする。
[選ぶ] 絞り込み検索は要チェック,検索範囲の制御にも注意
製品を選定する場合,言語解析やランキングの方式も重要なポイントになるが,まずは検索したいファイル形式やシステム・タイプをサポートしているかどうかをチェックしたい。多くの製品は数十から数百種類のファイル形式やシステム・タイプをサポートしているが,例えばNotes/Dominoをサポートしている製品でも,その中に格納された添付ファイルの中身まで検索できるかどうかで製品差がある。
目的の形式をサポートしていれば,(1)利用者が対話的に検索漏れやノイズを減らせるか,(2)検索範囲を制御できるか,(3)アクセス制御できるか――というポイントで選びたい。
対話機能で検索効率に差
検索漏れやノイズは言語解析によって減るが,製品によっては,利用者が対話的に検索漏れやノイズを減らせる機能を搭載する。
具体的には,検索結果を一定の条件でフィルタリングする「絞り込み検索」や,検索結果に類似・関連するものへと検索対象を広げる「類似検索」などが可能な製品である。絞り込み検索はノイズの除去,類似検索は検索漏れの防止に効果がある。検索エンジンの用途によっては,こうした機能で利用者の検索効率に大きな違いが生じる。
この機能に注目して製品を選んだのは,商品価格情報の提供サイトを運営するカカクコムである。同社の安田幹広氏(取締役 CTO)は,「利用者が興味のある製品情報に素早くたどり着けるように,検索結果を効率よく絞り込めることを重視」して,英Autonomyの「K2」を選択した。
絞り込み検索や類似検索は,製品差の大きい機能である。ビジネス サーチ テクノロジの「WiSE」の場合,検索結果に頻出するキーワードを自動的に解析し,絞り込み検索の候補として表示する(図1左上)。ConceptBaseは,検索結果の分布を表形式で視覚化する(図1右上)。表の軸は利用者が選択できる。Autonomyの「IDOLサーバ」は,類似情報の分布を二次元グラフや三次元グラフで表現できる(図1右下)。
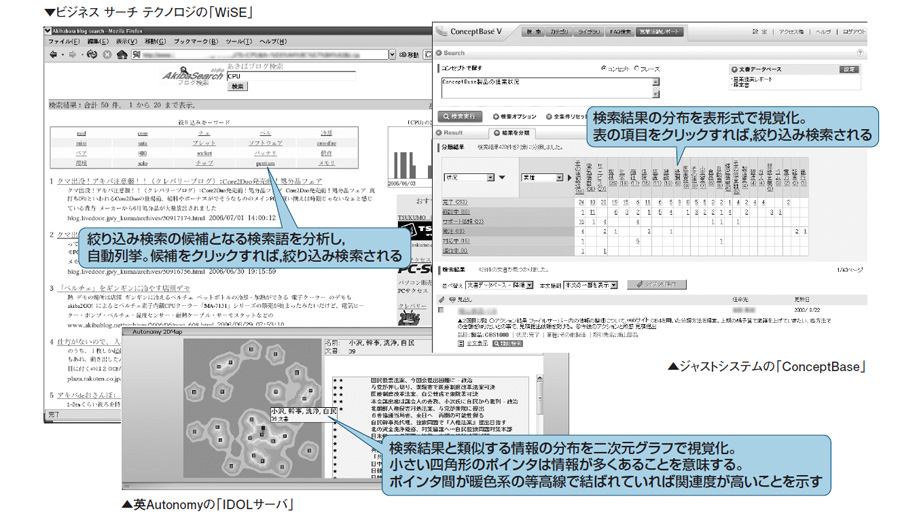 |
| 図1●絞り込み検索や類似検索の支援機能 検索してから情報をどう絞り込むかや,類似・関連情報をどう探し出すかといった機能は,製品ごとに大きく異なる [画像のクリックで拡大表示] |



















































