自社で必要となるデータにはどんなものがあり、どのような品質を目指すべきか、品質を維持・向上するためにどんな活動が必要か。データ優良企業になるためには、こうした品質マネジメントのプロセスやルールを、併せて整備しなければならない(図1)。
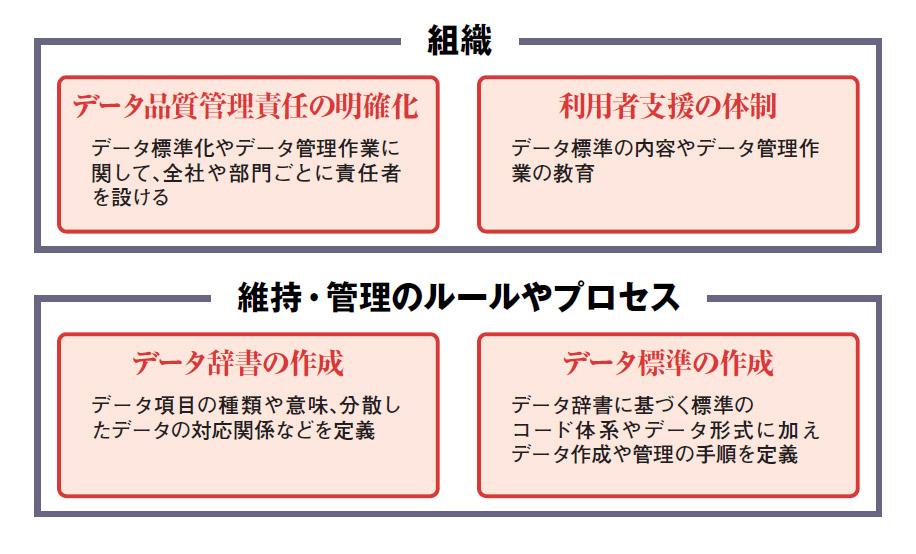 |
| 図1●IT基盤の構築以外に、データ品質マネジメントで実施すべき事柄 [画像のクリックで拡大表示] |
プロセスやルールを整備する上で重要なのが、データの意味や定義の参照元となる「データ辞書」の作成である。データの標準フォーマットを決めるためには、データの意味を全社で共通化しておく必要があるからだ。
データ辞書の作成作業では、各システムのデータ項目の名称や意味を洗い出し、その対応関係を明確にする。同じ「在庫」という項目でも、返品を含むのかそうでないのか、データ集計の単位は店舗単位なのか地域単位なのか。この違いを調べ、一つひとつ対応関係を作っていく。
06年から07年春にかけて、独SAPのERP(統合基幹業務)パッケージ「R/3」を使った基幹系システムを相次ぎ稼働させたオリンパス。同社は「データ辞書」を作成している最中だ。
オリンパスは、米国や欧州などを結ぶグローバルなSCMシステムの構築に着手した。そんな中で「現在の在庫の定義は国や地域でバラバラ。定義を合わせなければ、プロジェクトは進まない」(IT改革推進部 IT戦略統括グループリーダーの伊藤秀幸次長)という状況に直面したのである。
こうした事態の解決を支援する、データ辞書のテンプレートを提供するITベンダーも多い。日本IBMは金融や製造といった業種・業態ごとに汎用的なマスターデータの「モデル」を用意。金融であれば、氏名・住所・口座番号に加え、家族構成や勤務先とグループ会社など、マーケティングやリスク管理に必要な項目も定義している。
データ辞書を作成したら、目指すべき標準コード体系やデータ形式を決めていく。そこで重要なのは、そもそも現状のデータ品質はどうなっているのかを明らかにすることだ。
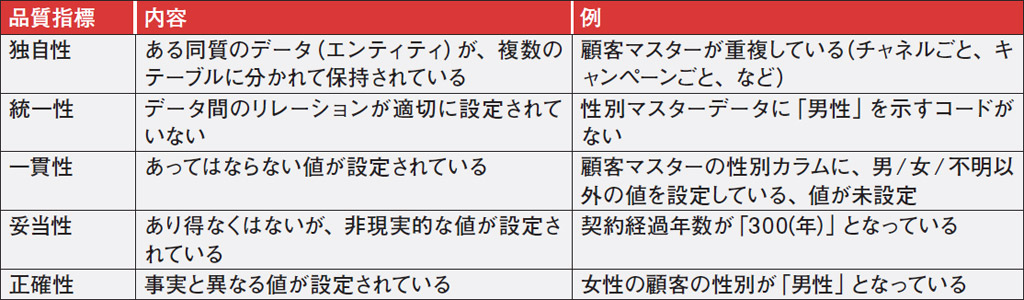
データ品質の現状調査で見るべき項目には、重複度合いを示した「独自性」、あってはならない値の存在程度を示した「一貫性」などがある(表1)。データ・ウエアハウスやETLツール関連のベンダーは、データ品質を調査するサービスを提供していることが多い。こうしたサービスを利用するのも1つの手段である。
| 表1●データ品質アセスメントで調査すべき内容の例 日本テラデータのアセスメント・サービスをまとめた。各ケースの発生件数や発生の割合を測定する [画像のクリックで拡大表示] |
 |
全社一丸で取り組め
IT基盤を整え、プロセスやルールも定めた。その上で必要なのが、運用のための組織体制である。パート2で紹介したキヤノンやP&G以外にも、キリン・グループやJALなど、データ品質マネジメントに注力する企業は全社一丸で取り組んでいる。
組織体制で重要なのが、データ品質マネジメントの責任者を明確にすることだ。担当する仕事はデータの標準化やデータの管理作業など。担当部署はもちろん、全社レベルの責任者を設けるのが理想である。
米インテルは、全社のマスターデータのデータモデルの作成、用語の定義の統一などに責任を持つ「データ・アーキテクト」を置き、マスターの統合を10年がかりで進めている。データ・アーキテクトを務めるジョリーン・ジョナス氏は、プロジェクト途中に実施したIT部門の再編で「情報品質マネジメント」と呼ぶ部署の設置を指揮。全世界の拠点で、データ品質マネジメントの重要性を説いて回った。
データ優良企業への道は一筋縄ではいかない。内部統制への対応や新サービスの開発と違って、データ品質マネジメントは本腰を入れて取り組みにくいのだ。
製品マスターデータの統合を進めているINAXの坪井取締役は「データの品質が多少低くて不都合を感じていたとしても、何とか業務は進んでいく。現場の協力を含めて対処の優先順位を上げにくい」と語る。これは多くの企業に共通する事実だろう。
しかし、強い意志を持ってデータ品質マネジメントに取り組んでいる企業も存在する。データの品質問題は先送りするほど、支払うべき代償が膨れ上がる。データを制する者は、システムを制す。このことを、企業は再認識すべきだろう。



















































