データの品質は、データを適正な形で保持・運用できるかどうかで決まる。(1)データが間違っていたり、重複している。(2)定義や意味、使い方が社内でバラバラ。(3)ルールが不完全で想定外のデータが発生する。このような状況が起きている場合、データの品質が劣化していることになる(図1)。
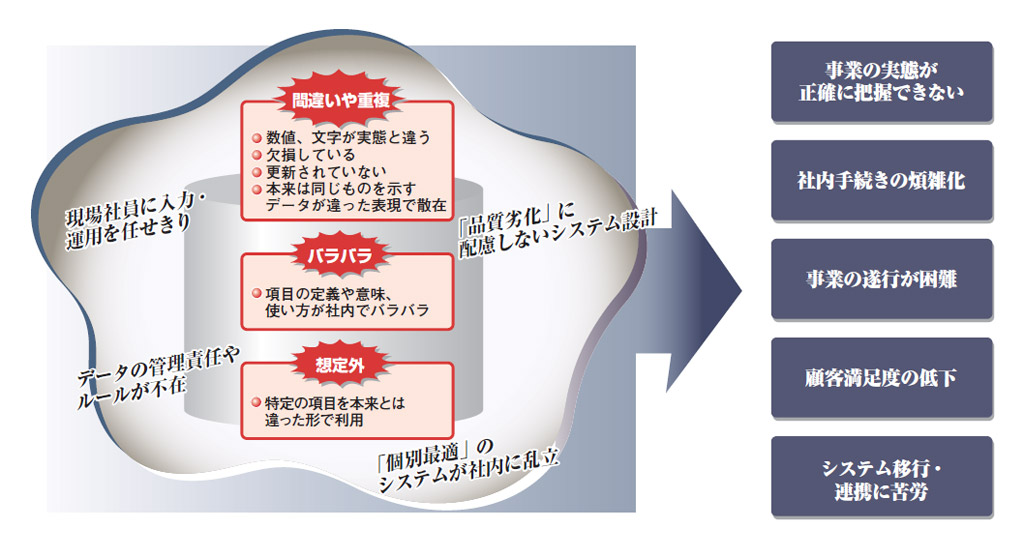 |
| 図1●データ品質劣化の原因 [画像のクリックで拡大表示] |
Case1 間違いや重複
キーボードの単純な打ち間違いや見間違い、聞き取りのミスで「日経」を「日程」と取り違えて登録する。変換ミスで「渡邊」を「渡辺」と登録する。「5丁目6番1号 第一マンション205号室」ではなく「5-6-1-205」と住所を入力していたため、顧客データベースで別人として管理してしまう。更新すべき住所データを放置する。
単純なデータの間違い・重複だが、積み重なればデータ品質は確実に劣化する。ケタ数の入力ミスは、受発注にかかわるシステムであれば、企業の利益に重大な影響を及ぼし得る。
ネット取引の増加につれ顕在化してきたのが、不正行為を目的とした意図的な「多重登録」によるデータ品質の劣化である。この問題に直面している企業がヤフーだ。
同社は年間で8000億円以上の品が取引される「Yahoo!オークション」を提供している。ここで過去数年にわたって問題となっているのが、出品者の不正行為である。
対策の一環としてヤフーは、オークションへの出品に必要な暗証番号を出品者の住所に送付する。この時、住所の記述で「-」の代わりに「★」を使ったりアルファベット表記を併用したりして、登録上は別の出品者に見せかけ、不正者リストとの照合から逃れようとするケースが後を絶たない。問題の解決のため、同社は人間によるチェックに加え、テキスト・マイニングの手法を応用した名寄せツールなどを活用している。
Case2 定義や意味がバラバラ
システムの統合や連携に伴って、これまでは何の不都合もなかったデータで、品質問題が顕在化することがある。
「顧客住所」は所在地なのか配送先なのか。「部品」はネジやボルトか、それとも完成品として組み立てる一歩手前の構成要素か。データの項目名が同じだったとしても、システムごとに定義や意味がバラバラであれば、1つのデータベースで管理することはできない。
多くの企業はこれまで、販売、生産、在庫といった各業務の効率化に当たって「個別最適」のシステム化を志向してきた。データの持ち方は各部門の業務に最適化したもので、必ずしも他の業務のことを考慮していない。同じ業務でも、部門が違えば全然違った形でデータを管理していることも珍しくないのだ。
CRM(顧客情報管理)やSCM(サプライチェーン管理)などのシステム構築では、複数の組織やシステムをまたがってデータを交換する必要がある。アクセンチュアの後藤洋介パートナーは「構築の過程で、データの意味や定義の違いのすりあわせ作業に必ず突き当たる。データ品質の問題を乗り越えずに、これからの戦略的なシステム構築は不可能だ」と断言する。
Case3 想定外
受注管理用データベースの「年代」という項目に入っている「99」というデータの意味は何だろうか。DOA(データ中心アプローチ)に基づいたシステム・コンサルティングを手掛けるデータ総研の堀越雅朗取締役は、システム再構築やデータ・ウエアハウス構築の現場で「しばしば不思議なデータに突き当たる」と話す。
普通に考えれば、99という年代はあり得ない。顧客企業の利用部門に確認すると、クレームなどのため緊急対応すべき件には99を入力して識別するのだという。無関係の項目を流用していたわけだ。
いわば想定外の使い方である。このような「ローカルルール」は至る所に存在する。新システムへのデータ移行時に排除してしまうと、業務に支障が出る。想定外のデータの意味をすくい取れなければ、データ・ウエアハウスを構築しても、現場の状態を正確に把握できなくなるからだ。かといってそのまま利用を続けようとしても、新システムでは異常値であるとして入力を拒否されてしまう。
堀越取締役は「本来存在してはいけない誤データだが、利用の現場で必然的に生まれてきたもの。どう扱うべきか、悩ましい問題だ」と語る。



















































