前回,ネステッドループ・ジョインの二つの処理手続きを説明しました。今回は,その二つの処理手続きのディスク・アクセス回数を見てみましょう。ディスク・アクセスはブロックの読み取り回数で考える必要があります。
ここでは話を分かりやすくするため,[顧客]テーブル(表1)の30レコードは10ブロック(1ブロックに3レコード)。このテーブルにはインデックスが付いていますので,それが5ブロック。全部で15ブロックだとします。[販売]テーブル(表2)の1000レコードは,250ブロック(1ブロックに4レコード)に格納されているとします。
![表1●[顧客]テーブルのカラム値](hyo01.jpg) |
| 表1●[顧客]テーブルのカラム値 性別は,0=男性,1=女性 |
![表2●[販売]テーブルのカラム値](hyo02.jpg) |
| 表2●[販売]テーブルのカラム値 |
260回と4250回
まず,[顧客]テーブルを先に読み取る処理手続き(図1)のディスク・アクセス回数を計算します(図2)。図1(1)に当たるところは,[顧客]テーブルの全ブロックを1回だけ読み取りますので,ディスク・アクセスは10回です。図1(2)では[販売]テーブルが1回だけ読み取り対象になりましたので,全ブロックを1回読むことになり,図1(2)のディスク・アクセスは250回です。その結果,[顧客]テーブルを先に読み取る処理手続きの場合,合計のディスク・アクセスは260(10+250で計算)回になります。
 |
| 図1●ネステッドループ・ジョインの処理概要(その1) [画像のクリックで拡大表示] |
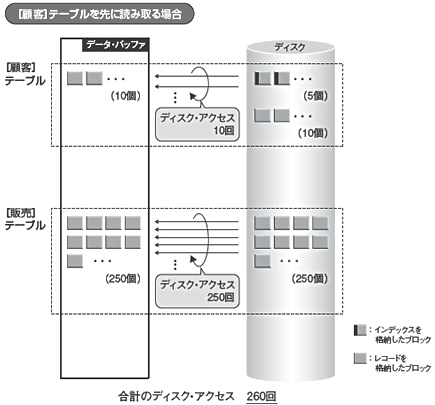 |
| 図2●ディスク・アクセス回数を試算(【顧客】テーブルを先に読み取る場合) |
次に,[販売]テーブルを先に読み取る処理手続き(図3)のディスク・アクセス回数を計算します(図4)。図3(1)に当たるところは,[販売]テーブルの全ブロックを1回だけ読み取りますので,ディスク・アクセスは250回です。図3(2)では[顧客]テーブルを繰り返し読み取っています。繰り返し回数は,[販売]テーブルのレコード数と同じですので1000回。ただし,その検索はインデックス検索で,(ユニークなカラムなので)条件に該当するレコードが見つかれば検索を終了します。基本的にインデックス検索のディスク・アクセス回数は4回(インデックスのブロック3個とレコードのブロック1個)ですので,図3(2)のディスク・アクセスは4000回(4×1000で計算)となります。その結果,[販売]テーブルを先に読み取る処理手続きの場合,合計のディスク・アクセスは4250(250+4000で計算)回です。
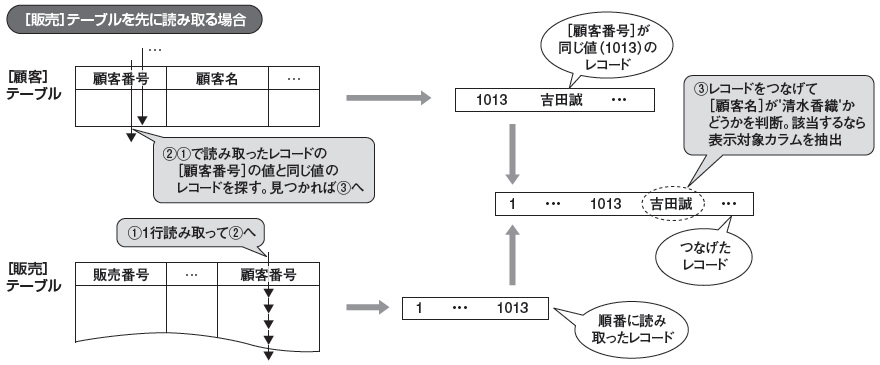 |
| 図3●ネステッドループ・ジョインの処理概要(その2) [画像のクリックで拡大表示] |
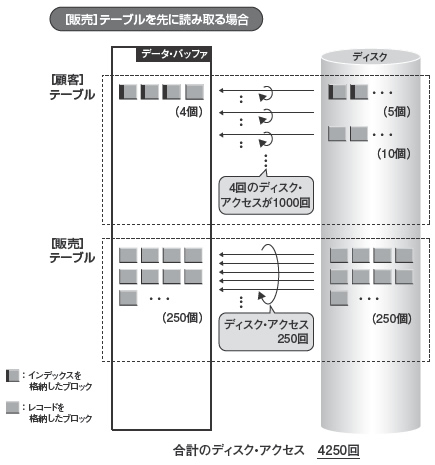 |
| 図4●ディスク・アクセス回数を試算(【販売】テーブルを先に読み取る場合) |
結合対象のレコード数に注目
二つのテーブルのどちらを先に読み取るかで,ディスク・アクセス回数には大差が付きました。[顧客]テーブルが先だと260回で,[販売]テーブルが先だと4250回。16倍もの差です。ディスク・アクセス回数は少ないほど処理時間は短いので,実行プラン(最適と判断された処理手続き)としてはおそらく,[顧客]テーブルを先に読み取る処理手続きが選ばれるでしょう。
ディスク・アクセス回数の増減を大きく左右するのは,結合対象のレコード数です。[販売]テーブルを先に読み取る手続きでは,[販売]テーブルの全レコードを結合しました。それに対して[顧客]テーブルを先に読み取る手続きでは,検索条件に該当するレコードのみ結合対象になりました。この違いが,大差の要因です。つまり,[顧客]テーブルに検索条件のカラム([顧客名])がありますので,先に[顧客]テーブルを読み取ることでレコードが絞り込まれた,というわけです。
特集のまとめをしたいと思います。SQL文の処理手続きの良しあしは,主にディスク・アクセス回数で判断されます(少ない方が良い)。なぜなら,ディスク・アクセス処理はほかの処理に比べて遅く,全体の処理時間を大きく左右するからです。ディスク・アクセス回数を少なくする最も基本的な技術はインデックスで,主に使われるのはBツリー・インデックスです。Bツリー・インデックスは常に効果が得られるわけではなく,カラム値の種類が少ない場合や,レコード数の少ない場合はほとんど効果がありません。二つのテーブルを検索するとき,ジョインが行われます。
|



















































