今回は,ネステッドループ・ジョインの詳細な処理手続きを説明し,最適と思われる手続きを解説します。対象テーブルは[顧客]テーブル(表1)と[販売]テーブル(表2)の二つ。[顧客]テーブルは30レコード,[販売]テーブルは1000レコードです。インデックスは,[顧客]テーブルの[顧客番号]カラムにのみ付いているものとします。これはユニーク(同じ値が一つの意)なインデックスです。
![表1●[顧客]テーブルのカラム値](hyo01.jpg) |
| 表1●[顧客]テーブルのカラム値 |
![表2●[販売]テーブルのカラム値](hyo02.jpg) |
| 表2●[販売]テーブルのカラム値 |
SQL文は前回と同じで,[顧客]テーブルと[販売]テーブルの二つのテーブルを検索対象にしています。
SELECT 販売日,顧客名,商品コード,数量FROM 顧客,販売WHERE 顧客.顧客番号 = 販売.顧客番号AND 顧客.顧客名 = '清水香織'
意味:[顧客]テーブルの[顧客番号]と,[販売]テーブルの[顧客番号]が同じ値であるという条件で[顧客]テーブルと[販売]テーブルを結合し,[顧客名]の値が「清水香織」である,[販売日][顧客名][商品コード][数量]を抽出
「顧客.顧客番号 = 販売.顧客番号」の部分がジョインの条件になります。この条件に基づいて作られた一つのテーブルに対し,「顧客名 = '清水香織'」の検索条件に合うレコードを抽出する,というSQL文になります。
以下では,ネステッドループ・ジョインで処理されるという前提で,このSQL文の最適な処理手続きを考えます。
ネステッドループ・ジョインの処理手続き
ネステッドループ・ジョインは,先に一方のテーブル(これを「駆動表」と呼びます)からレコードを取り出し,そのレコードと結合するレコードを,もう一方のテーブルから抽出する,という方法です。
この処理方法のポイントは,先に読み取るテーブルのレコードはそれぞれ1回しか読み取りませんが,もう一方のテーブルは何回も同じレコードを検索する可能性があるという点です。それゆえ,処理手続きにおいて注目したいのは,二つのテーブルのうちどちらを先に読み取るか(別の言い方をすれば,どちらを「駆動表」にするか)という点です。このことが,ディスク・アクセス回数を大きく左右します。
[顧客]テーブルを先に読み取る処理手続きと,[販売]テーブルを先に読み取る処理手続きが考えられます。順番に見ていきましょう。
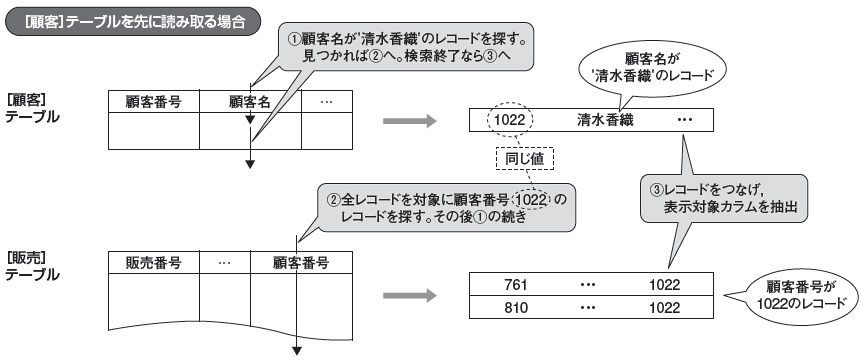
図1は,[顧客]テーブルを先に読み取る処理手続きを示しています。最初は,[顧客]テーブルから検索条件([顧客名] = '清水香織')に合致するレコードを探します(図1(1))。見つかれば,もう一方の[販売]テーブルを検索します。その検索は(1)で見つかったレコードの結合対象を探すことになりますので,ジョインの条件である[顧客番号]のカラム値(図1では「1022」)を基に検索します。条件に合致するレコードは一つとは限りませんので,全レコードを読み取ることになります(同(2))。
 |
| 図1●ネステッドループ・ジョインの処理概要(その1) [画像のクリックで拡大表示] |
その後,(1)に戻って先ほどの続きから検索し,合致するレコードが見つかれば(2)の処理を再び実行します(図1では検索条件に該当するレコードが一つなので,(2)の処理は1回のみになります)。(1)の検索が終了すれば,(1)と(2)で取り出したレコードをつなげ,表示対象のカラム([販売日][顧客名][商品コード][数量])を抽出します(同(3))。
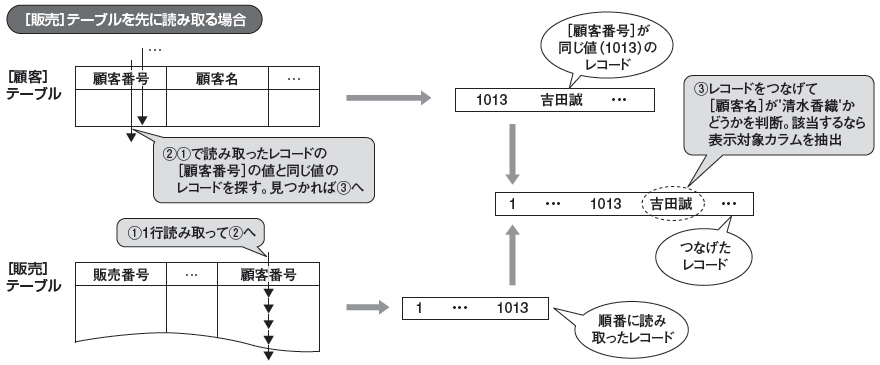
図2は,[販売]テーブルを先に読み取る処理手続きを示しています。[販売]テーブルにはインデックスが付いていませんので,先頭レコードから順番に読み取り(図2(1)),そのレコードと結合するレコード,つまり,[顧客番号]が同じ値のレコードを[顧客]テーブルから探します(同(2))。[顧客]テーブルの[顧客番号]カラムはユニーク(同じ値が一つしかない)なので,(2)は対象レコードが見つかれば検索を終了します。(1)と(2)で取り出したレコードをつなげて検索条件([顧客名] = '清水香織')に合致するかどうかを判断し,条件に合うなら表示対象のカラム([販売日][顧客名][商品コード][数量])を抽出します(同(3))。
 |
| 図2●ネステッドループ・ジョインの処理概要(その2) [画像のクリックで拡大表示] |
この一連の処理を,[販売]テーブルの全レコードに対して順番に繰り返し実行します。
|



















































