Google Gearsではキャッシュすることをキャプチャ(Capture)といい,キャプチャする場所のことをストア(Store)と呼びます。前回まではデスクトップなどのローカルに作成したサンプルでも動きましたが,今回からはインターネット上(あるいはLAN内でHTTP経由で接続できる場所)にサンプルを設置する必要があります。Google GearsそのものはJavaScriptとHTMLでしかありません。PHPなどのサーバー・サイド環境を必要としませんので,プロバイダの無料ホームページ・エリアも利用できます。
キャッシュの仕組みを知ろう
Google Gearsで作成したアプリケーションはオフラインでも動作する--これがGoogle Gearsの一番の売りです。どういう理屈でオフライン動作をさせるかということなんですが,簡単に言ってしまえばインターネットに繋がっている間に,必要であればGoogle Gearsの機能を使って,明示的にローカルにキャッシュを作り,以後オフラインならばローカルキャッシュを見ます,という動作原理になっています。ここでお断りをしておくことにしましょう。本稿では以後「インターネット」と記述しますが,Google Gearsはインターネットに限らず,ネットワーク上でHTTPプロトコルあるいはHTTPSプロトコルを使用して通信できる"Google Gearsコンテンツ"に対して,オフラインでの動作をサポートします。毎回「インターネットもしくはHTTPで通信できるネットワーク上の…」と書くのも読みづらくなるだけですから,以後「インターネット」と簡単に省略させていただくことにします。
Google Gearsではキャッシュを貯め込んでおく場所をストア(Store)と言います。ストアには2種類が存在します。
・リソース・ストア
・マネージド・リソース・ストア
リソース・ストアはブラウザのキャッシュとよく似ています。マネージド・リソース・ストアは,単純キャッシュであるリソース・ストアに対して管理機能を使用できるように拡張されたものです。
まずは簡単なリソース・ストアから見てみます。ブラウザでアクセスした場所のソースコードや画像ファイルを記憶しておくというだけのことならば,ブラウザにもキャッシュ機能があります。ブラウザのキャッシュに取り込まれていれば,特にGoogle Gearsの機能を使用することなく,オフラインでも一度見たコンテンツは表示できるわけです。まずブラウザのキャッシュとGoogle Gearsのストアでは何が違うのかを知る必要がありそうです。
[Google Gearsの特徴]
1.キャッシュしたURLへのアクセスはネットワークよりキャッシュが優先される
2.何をキャッシュするかを指定できる
3.キャッシュのコピー,リネーム,削除が任意にできる
4.指定されたファイルをブラウザで開いていなくてもキャッシュできる
(1)についてはブラウザのキャッシュ機能と全く同等です。IEにもFirefoxにも,メニュー項目に「オフライン作業」という項目があります(図1)。
図1●ブラウザのメニューにある「オフライン作業」。チェックを入れればネットワーク接続しない
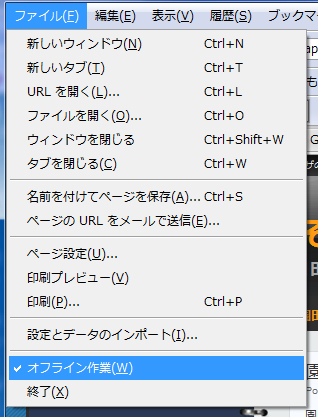
「オフライン作業」にチェックを入れないで,適当にいくつかのサイトを見て回り,その後に「オフライン作業」にチェックを入れて,再度今見て回ったサイトを閲覧するようにアドレスを入力してみてください。すると,ブラウザが記録しているキャッシュからページが表示されます。通信の発生なしにコンテンツがオフラインで読めているわけです。勿論キャッシュで閲覧している以上,例えばニュースサイトでニュースが更新されていても,キャッシュした段階のニュースしか表示されません。オフラインでキャッシュを利用する限り,最新のコンテンツ内容は出ません。
http://xxxxxxx.com/xxxx.html のようなアドレスがユーザーによって指定された場合,ブラウザはまず指定されたURLがキャッシュされているかどうかを確認します。キャッシュがあればインターネット経由で現在のそのコンテンツの更新日時やサイズを取得して,同一であればキャッシュから,サイトのほうが新しければサイトから再取得してページを表示します。Internet Explorer 7の場合,キャッシュと最新のものとの比較方法は[ツール]-[インターネットオプション]-[全般タブ]-[閲覧の履歴 項目]-[設定]で行えます(図2)。
図2●IE7のキャッシュ動作の設定画面。設定によってキャッシュの使い方が異なる
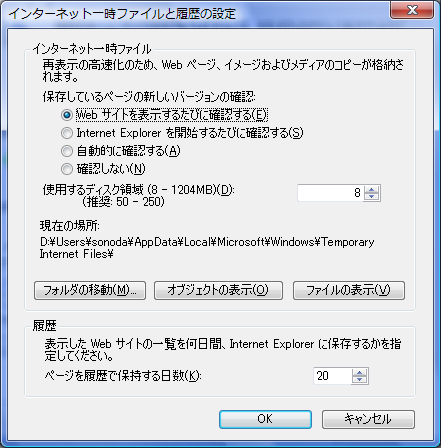
「Webサイトを表示するたびに確認する」を選択すれば,オンライン状態ならば事実上キャッシュは無効化されます。「確認しない」に設定するとオンラインよりもキャッシュが優先されますので,キャッシュが残っているページではキャッシュを取った段階のページが表示され,最新状態がどうなっていようと無視されます。「Internet Explorerを開始するたびに確認する」と「自動的に確認する」,特に「自動的に…」のほうは,ブラウザ内部で何をやっているのかはわかりません。
Firefoxはもっとずっとシンプルです(図3)。キャッシュのサイズ指定と,キャッシュとして取り込んでいるものを削除するボタンしかありません。Firefoxがどうやってキャッシュとサイトの現行最新ドキュメントを比較するのかなどは,この設定画面からは全く読み取れません。
図3●Firefoxのキャッシュ設定。サイズの指定とキャッシュを削除する「今すぐ消去」だけ
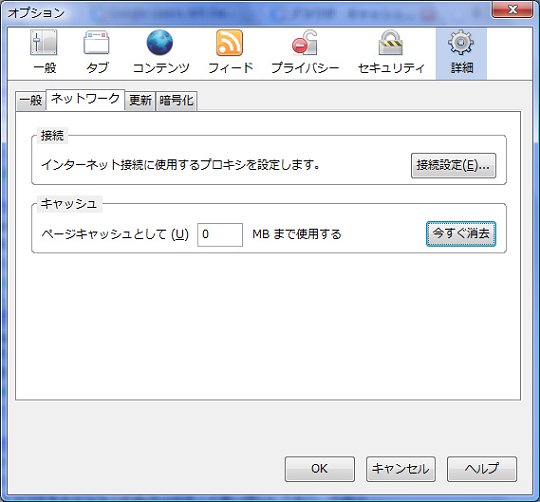
どちらのブラウザも,こうやって冷静に見てみると,キャッシュがどう作用しているのかはあいまいなままであるというわけです。いつまでキャッシュが保持されるのか,指定されたサイズを超えるほどキャッシュが貯まったら何から削除されていくのかなども明確ではありませんね。
Google Gearsのキャッシュは,ブラウザのキャッシュ機能とは全く独立して存在しています。保存場所もブラウザとは異なります。また容量の制限などは一切ありません。プログラムで意図的に削除するまでは,キャッシュが自動で削除されるということもありません。キャッシュをプログラマが完全にコントロールできるというわけです。
つまりこういうことです。Google Gearsが求めているのは,オフラインでもコンテンツが確実に動くということです。オフラインで作業することは,ブラウザのキャッシュ方式に依存してもある程度は可能なんだけれども,ブラウザはどれだけ貯め込んでくれるのかもわからない。いつキャッシュが消えてしまうかもわからない。これでは安定したオフラインでのアプリケーション動作は望めない。だったら自前でキャッシュがコントロールできるようにしてしまえ!というわけです。
ただ闇雲になんでもかんでもキャッシュすればいいというものでもありません。またWebアプリケーションですから,絶対にキャッシュでは困ってしまうという局面も少なからずあるわけです。そこで(2)の「何をキャッシュするのかはプログラムで指定できる」という機能が必要になります。明確に「これとこれはキャッシュしろ」と指定ができます。指定できるということは指定しなければ何もキャッシュされないということでもあり,キャッシュしたくないものを意図的に外すということもできるわけです。
なおGoogle Gearsでキャッシュできるのは,キャッシュするようにプログラムで指示したGoogle Gearsアプリが置かれているのと同一ドメインのファイルに限定されます。例えば自分のホームページ・エリアに設置したHTMLのGoogle Gearsから,他ドメイン,例えばhttp://itpro.nikkeibp.co.jp/のコンテンツをキャッシュするように指示するといったことはできません。
(3)のキャッシュしたファイルのコピーやリネームは付帯的な機能です。削除についてはキャッシュを意図的に消したいケースがあるはずなので付帯的とばかりは言えません。
(2)と若干かぶるのですが(4)もかなり特徴的です。通常ブラウザがページをキャッシュするためには,そのドキュメントをブラウザ画面上で見ている必要があります。例えば個人のブログを見ていて,今日のブログは読んだけど,先月の5日のブログは見ていないとすれば,その古いブログはキャッシュされません。したがってオフラインで読むということはできません。細かい話をすると,ブラウザには高速化のために先読みキャッシュという機能があって,リンク先をこっそり先に見てキャッシュしておくということもするらしいですが,どういうルーチンで先読みをするのか,これまたはっきりしません。意図するものを必ず先読みしてくれているとはいえないわけです。
Google Gearsは,キャッシュを生成する際に明示的にURLを指定します。これとこれとこれを取り込めという指定が効きます。その取り込み時にはブラウザ上では指定されたページを一つずつ開いて表示するという動作はなく,プログラムが仕込まれたページが出ているだけです。画面として見たわけではないが,そのドキュメントは確実にキャッシュされているというわけです。
Google Gearsではブラウザ側にキャッシュがなくても,ストアが存在し続けるうちはネットワーク経由で最新コンテンツを取得しにいきません。常にキャッシュからの読み出しになります。今ネットワーク経由で見ているのか,はたまたキャッシュから見ているのかというあいまいさは存在せず,“ストアがあるならストアから読む”です。明確に指針がある分だけ作業はしやすいでしょう。ストアにない場合のみサイト接続になります。
ブラウザのGoogle Gearsアプリに対する表示優先度は次のようになります。
ブラウザのキャッシュ > ストアのキャッシュ > サイトのコンテンツ
左のものがなければ右のもの右のものと探していくわけです。
ストアそのものは実はディレクトリ(フォルダ)という考え方ができます。実際,Google Gearsではディレクトリとして作成されたストアの中に,指定されたURLのファイルを直接貯め込んでいきます。
Windows Vista - Internet Explorer
C:\ユーザー\ユーザー名\AppData\LocalLow\Google\Google Gears for Internet Explorer
Windows Vista - Firefox
C:\ユーザー\ユーザー名\AppData\Local\Mozilla\Firefox\Profiles\uelib44s.default\Google Gears for Firefox
Windows XP - Internet Explorer
C:\Documents and Settings\ユーザー名\Local Settings\Application Data\Google\Google Gears for Internet Explorer
Windows XP - Firefox
C:\Documents and Settings\ユーザー名\Local Settings\Application
上記ディレクトリの中に,さらに「ドメイン名」(例:code.google.com)のディレクトリができて「http_80」(プロトコルとポート番号)というディレクトリ,その下に「ストア名」(プログラムで任意指定可能)のディレクトリが作られます。キャッシュされたファイルはここに保存されます。



















































