ルーターの基本的な処理は,あるインタフェース・ポートから受信したパケットのあて先アドレスを調べて,対応するインタフェース・ポートへ送り出すことです。しかし,実際のルーターは,単にパケットを転送するだけではなく,その間にさまざまの処理を実行しています。
例えば,第4回で解説したトラフィック制御に関連して,QoS(quarity of service)の処理方法を判断するためにデータ・フローを識別したりパケットを転送するかどうかを決めるといった処理,さらにはトラフィックの統計情報を収集するといった処理が,一般的に行われています。具体的に見てみると,実際にパケットを転送処理する際には,パケットのヘッダー部を詳細に解析して,あて先のポートを決めたりパケットを転送してよいかどうか(フィルタリング)を判断したりします。さらに,転送処理の優先度の判定や,統計情報を収集する場合の条件判定と実際の統計情報の採取も同時に行う必要があります(図1)。
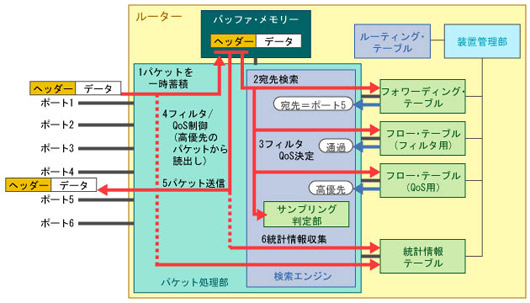 |
| 図1●ルーターの構成と処理の流れ パケットを転送処理する間に,フィルタ/QoS(quality of service)や統計情報の収集も同時に処理しなければならない。 |
こうした一連の処理は,パケットをあて先ポートへ転送するまでの間に実行する必要があります。パケットの転送性能を向上させるには,この処理の時間をできるだけ短くしなければなりません。今回は,上記の処理を短時間で実行するための取り組み,つまりルーティング処理の性能を向上させる取り組みについて紹介します。
ルーターのパケット交換処理を高速化する鍵は?
パケットの転送にかかる処理時間を短くする取り組みを見る前に,まず,ルーターの基本的な処理の流れを押さえておきましょう。
ルーターの基本的な処理の流れは以下のようになります。(1)受信したパケットを装置内部のバッファ・メモリーに一時的に蓄積し,(2)パケットのあて先を決定し(あて先検索),(3)パケットの種類(フロー)に応じてフィルタリングの実行可否の判定や品質保証レベル(QoS)を決定し,(4)(3)の判定に従ってフィルタリングを実行したりQoS制御を行い,(5)あて先に対応するポートからパケットを出力し,(6)パケットの受信数・送信数の統計情報を収集する――といった流れです。ルーターのパケット転送性能を向上させるためには,(1)と(5)のパケット本体のメモリーへの書込みと読出しの処理を短時間で実行するのは当然ですが,(2)~(4)と(6)の処理も同様の時間内で処理する必要があります。
今回はこの中から,(2)のあて先検索,(3)のフロー検出処理,(6)の統計収集処理――のそれぞれに関して,高速化の手法について説明していきます。
大容量テーブルからあて先を高速に検索
それでは,「あて先検索」から見ていきましょう。
ルーターの仕事であるパケットの転送処理には「ルーティング・テーブル」というデータベースを利用します。ルーティング・テーブルとは,パケットのあて先IPアドレスとそのIPアドレスを持つ端末へパケットを最短経路で届けるための出力ポートの対応表のことで,他のルーターと「ルーティング・プロトコル」というプロトコルでやりとりした経路情報や,そのルーターにあらかじめ設定した経路情報を基に作成します。現在おもに使われている「IPv4」の場合,IPアドレスは32ビット長のデータで表します。このため,単純に計算すると,約40億台の端末を識別できることになります。
しかし,端末1台1台のアドレスに対する出力ポートをデータベースとして管理するのは現実的ではありません。なぜなら,データベースが巨大になって,経路の検索に膨大な時間がかかってしまうからです。
このため,IPネットワークではIPアドレスの上位数ビットをネットワーク識別子となる「ネットワーク・アドレス」と定義し,ルーターはルーティング・テーブルをこのネットワーク・アドレスごとに管理します。つまり,各端末のIPアドレスの上位ビットはその端末が属するネットワーク・アドレスになるので,ルーターは,ネットワーク・アドレスと出力ポートの組み合わせ(これを「経路」と呼びます)をルーティング・テーブルで管理するのです。例えば,32ビット長のIPアドレスのうち,上位の16ビットや24ビット単位に経路を階層的に管理するといった格好になります。
このようにIPアドレスを階層的に管理することで,端末数が増加してもルーティング・テーブルの規模があまり大きくならず,ルーターの処理負荷が高くならないようになっています。しかし,インターネットに接続するネットワークが増え続けており,プロバイダのネットワーク内で使われるハイエンド・ルーターが管理しなければならない経路の数は,IPv4の場合で20万経路を超えました。また,今後は50万~100万経路まで増加することを考慮する必要があります。
専用の検索エンジンが経路を見つける
ハイエンド・ルーターでは,検索処理の高速化のため,専用のハードウエア(以下「検索エンジン」と呼びます)を用意する構成が一般的です。ただし,検索エンジンは直接ルーティング・テーブルを検索するわけではありません。ルーティング・テーブルから,この検索エンジンが参照するフォワーディング・テーブルを作成し,テーブル・メモリー内に設定します。このフォワーディング・テーブルの構成が,高速な経路検索には重要となります。この辺りは後で解説します。
検索エンジンはパケットがルーターに到着してメモリーに格納されるたびに,パケット・ヘッダー内のあて先IPアドレスを検索キーにしてフォワーディング・テーブルを検索します。10Gビット/秒のイーサネット・インタフェースでは,最小サイズのパケットが到着する間隔は,最短で67ナノ秒(ns)です。10Gビット/秒のインタフェースを備えるルーターの検索エンジンは,最低でもこの67nsの間に検索処理を終えなければなりません。時間内に処理が完了しないと,次のパケットが到着してしまうからです。
複数のインタフェース/回線を一つの検索エンジンで処理する場合は,上記の必要検索処理時間は回線数で割った値になります。例えば8回線分のパケットを処理する場合,検索処理時間は67ns÷8=8.4ns以内にしなければなりません。
ハイエンド・ルーターでは先に見たように20万以上の経路を管理しています。この大規模なテーブルから該当する経路を,こうした短時間で処理するためには,フォワーディング・テーブルの構成に工夫が必要になります。このような大規模なテーブルを検索するためのいくつかの検索方式と,それぞれの検索時間を考えてみましょう。3種類の検索方式で処理時間を比較
フォワーディング・テーブルの検索方式には,大きく(a)リニア・サーチ方式,(b)ツリー検索方式,(c)全エントリ同時検索方式――の3種類があります。
まず(a)のリニア・サーチ方式について解説しましょう。これは,フォワーディング・テーブルの各エントリを一つずつテーブル・メモリーから読み出して,あて先IPアドレスと比較する方式です(図2)。一致するエントリに出会うまで,テーブル・メモリーを読み出し続けます。エントリが一致するまでに読み出さなければならないエントリ数の平均値は,全エントリ数の2分の1になります。20万の経路を管理するルーターのケースなら,平均10万回となる計算です。
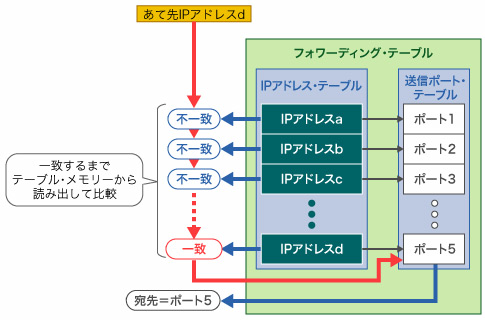 |
| 図2●リニア・サーチ方式によるあて先検索処理 テーブル・メモリーからIPアドレスを読み出し,それをあて先IPアドレスと比較する。一致したらその対応する送信ポート・テーブルを読み出す。検索にかかる時間は,1回の読み出し時間×エントリ数÷2となり,処理を高速化できない。 |
現在テーブル・メモリーのメモリー素子として一般的に使われているのはSSRAMと呼ばれるものです。このSSRAMの動作周波数は266MHz程度です。つまり,読み出し時間の間隔は,1(秒)÷266M(Hz)=3.8(ns)となります。これは,1回の読み出しに3.8nsかかるということです。
受信したパケット一つの経路を探すのに平均で10万エントリを読み出すとすると,検索時間の平均は,3.8ns×10万回で380マイクロ秒(μs)となります。
10Gビット/秒の回線で最もサイズの小さいパケットが流れてくると,ルーターはそのパケットを67nsで処理しなければなりませんでした。380μsはその63nsに比べて約5600倍となってしまいます。つまり(a)の方式は,10Gビット/秒のインタフェースを備えるようなハイエンド・ルーターには不向きな方式であることがわかります。
|
|
|
|



















































