 |
複数のディスクを論理的に一つにまとめる実装技術の一つがRAID(Redundant Arrays of Inexpensive Disks)である。信頼性の向上を目的に多用されるのは,ディスクをミラーリング(二重化)する「RAID1」と,パリティと呼ぶエラー訂正情報を保管する「RAID5」である。
RAID構成を採ると「データが失われることはない」と過信しがちだが,基本的に同時に2台以上のディスクが壊れるとデータを保護できない。さらに,1台のディスクの故障であっても,「実際には復元できないケースがある」(ラック SNS事業本部 JSOC部 グループリーダ 花岡顕助氏)。ミラー領域やパリティ領域はほとんどアクセスされないので,「いざアクセスしようとしたときに壊れていた」という事態になることがあるからだ。
パリティを失うと復元できない
ディスク3台(A,B,C)でRAID5を構成した場合を例に説明する(図)。データを書き込む場合,RAIDコントローラはデータを二つ(ブロック1,2)に分割し,ディスクAにブロック1を,ディスクBにブロック2を書き込む。残りのディスクCには,分割した二つのブロックを入力とするXOR(排他的論理和)演算の出力をパリティ[1,2]として書き込む。XORとは入力値が一致していれば「偽」,異なれば「真」を出力する論理演算である。
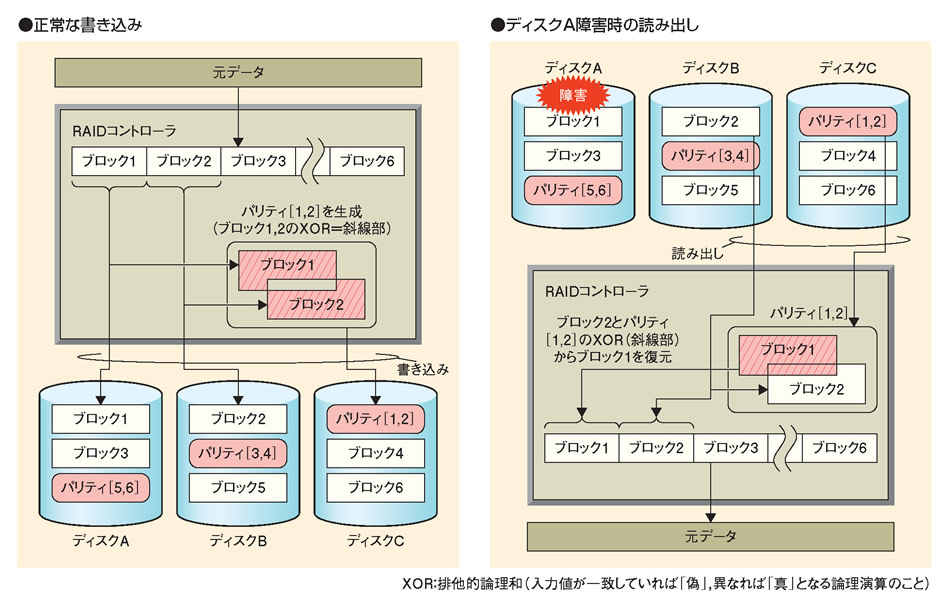 |
| 図●RAID5の仕組み RAID5は,2台~5台のディスクにデータを分散配置し,1台のディスクにエラー訂正用の「パリティ」を格納する。1台のディスクで障害が発生した場合は,データを復元できる [画像のクリックで拡大表示] |
ディスクAに障害が発生するとブロック1が失われるが,ブロック2とパリティ[1,2]を入力とするXOR演算を実行すると,その出力はブロック1のデータになる。こうしてブロック1を復元できるが,1台のディスクが壊れているときに,さらにディスクが故障するとデータを保護できない。
ただ,最近ではパリティを2台のディスクに格納することで信頼性を高めた「RAID6」に対応する製品が増えてきた。RAID6なら,2台のディスクが壊れてもデータを保護できる。
不良ブロックが生じる
先に,ミラー領域やパリティ領域は「いざアクセスしようとしたときに壊れていた」という事態になることがある,と述べた。これは,単体のディスクに備わっているデータ保護機能が,ミラー領域やパリティ領域では有効に機能しにくいのが主な理由だ。
ディスクは,磁性体を塗布または蒸着させた金属製の円盤を高速回転させながら,磁気ヘッドを近づけてデータを読み書きする。円盤と磁気ヘッドの距離は,わずか数nm(ナノメートル)。ちょっとした振動でも接触し,円盤を損傷してしまう。そこでディスクには,読み書きする際に損傷領域を見つけ,その領域を「不良ブロック」としてアクセス不可に設定する機能がある(ディスクに機能がない場合はOSが代行する)。このとき,不良ブロックのデータが読み出せる場合は,損傷が悪化してデータを消失する前に,データを自動的に予備領域に移行する。
だが,パリティ領域やミラー領域に書き込み後に不良ブロックが生じた場合,この代替処理が実施されない。なぜなら,いったん書き込んだパリティ領域やミラー領域は,ディスクが故障するか,データ領域で更新が発生しない限り,読み書きすることはないからだ。代替処理を実行しないままで不良ブロックの状態が悪化すると,データは消失してしまう。この状態でディスクが故障すると,パリティ(やミラーのデータ)が読み出せずにデータが復旧できなくなる。
このような事態を防ぐために,RAIDの装置やソフトには,「整合性検査」と呼ぶ機能が搭載されている。この機能は,ディスクの全領域に対して読み出しをかけ,パリティ領域やミラー領域に損傷がないかをチェックするものだ。異常を検出したときには,自動的に修復する。RAIDを使う際は,定期的な整合性検査が不可欠だ。



















































