データ・ウエアハウスやデータ・マートは,すでにブームの時期を脱し,本格的な普及期に突入した。しかし,普及が進むにつれ,データの品質不良や “保守地獄”といった深刻な理由で,せっかくのデータ・ウエアハウスやデータ・マートが重荷になっている企業も少なくない。問題を未然に防ぐ七つの勘所を紹介する。
椿 高明
本記事は日経コンピュータの連載をほぼそのまま再掲したものです。初出から数年が経過しており現在とは状況が異なりますが、この記事で焦点を当てたITマネジメントの本質は今でも変わりません。 |
最近,データ・ウエアハウスやデータ・マート(目的別に作る中小規模の情報系データベース・システム)を構築した企業の間で,二つの問題が緊急課題として浮上している。いずれも,開発・保守コストを急激に増大させている深刻な問題だ。
一つは,開発プロジェクトのオーバーラン(納期遅れ・予算超過)である。データの品質対策に,予想を超える作業工数がかかっている。生成したデータ・ウエアハウスの中でデータ間の帳尻がなかなか合わず,開発期間が大幅に延びてしまうのだ。オーバーランしたプロジェクトについて稼働後に開発工数の内訳を調べてみると,「全体の6割から8割がデータの品質対策に費やされていた」という事例が非常に多い。
もう一つは,データ・マートが増えすぎたために引き起こされる保守コストの激増である。あるサービス企業では,エンドユーザーの旺盛なデータ分析ニーズにこたえて30数個のデータ・マートを作った。しかし,必要なデータを抽出するために,その場しのぎで基幹系システムや他のデータ・マートとインタフェースを張り巡らせた結果,ついにだれも全体を理解できない状態にまで複雑化してしまった。
こうなると運用・保守作業はアリ地獄だ。修正や障害の連鎖波及も止められない。データ・ウエアハウスやデータ・マートに積極投資した米国の企業は,「インタフェース・プログラムの維持コストに情報システム予算の実に50%近くを費やしている」と米国のコンサルティング会社Information Impact International社は報告している(図1)。
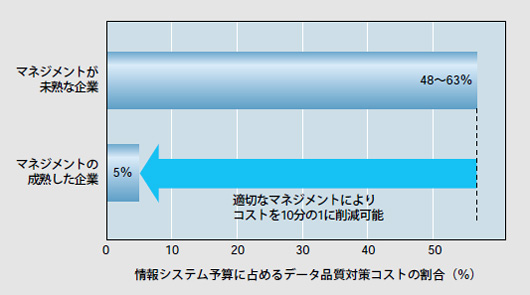 |
| 図1●情報システム予算に占めるデータ品質対策コスト(インタフェース・プログラムの保守コストなど)。データ出所:米Information Impact International社 |
保守コストは10分の1にできる
だが,情報システム部門の費用の約50%にまで膨らんだインタフェース・プログラムの維持コストは,適切な対策を講じることで,およそ10分の1にまで圧縮できる。そのためには,データの品質やデータ・マートの乱開発に関する問題などをクリアしなければならない。
筆者の経験から言うと,これら二つの問題を回避している先進企業は国内にも確かに存在する。そして,そこには風説に惑わされない明快な開発指針が息づいている。こうした先進企業に対する分析を基に,データ・ウエアハウス/データ・マート構築の「勘所」を7点に整理してみた。
勘所(1)
集計軸のズレを徹底分析せよ
開発プロジェクトの初期段階で重要なのは,「集計軸を徹底分析し,明確に定義すること」。多様なシステムからデータを収集する場合の鉄則である。にもかかわらず,意外に強調される機会が少ない。集計軸のできの良しあしは,後になってプロジェクトの明暗を分ける。
例えば売上高の分析なら,営業組織コード,顧客コード,商品コード,年月などの集計軸を定義するだろう。だが,これらのコードの定義内容が,業務,事業,地域などによって微妙に異なる,という問題が多発している。コード体系が同一でも,運用上の意味合いが異なるケースも少なくない。
あるユーザー企業は,販売・物流分析のためにデータ・マートの開発に着手した。だが大詰めの段階になって,出荷金額と売上高のそれぞれの合計値がどうしても食い違うという問題が露呈した。膨大な工数を割いて原因を調べたところ,次のようなことが判明した。
物流システムと販売システムで営業組織の定義が微妙に異なっていた,特定の顧客について年月の解釈が食い違っていた,特定の商品に付与されていた商品分類コードの解釈がシステム間で微妙に異なっていた,などである。このプロジェクトは結局,データ・ウエアハウスの構築をすべて最初からやり直すことになった。
こうした事態を避けるためには,データの抽出元となるすべてのシステムについて,あらかじめ現状のコード体系を棚卸ししておくことが不可欠だ。社内組織関係のコ-ド,取引先関係のコード,物品サービスに類するコード,時間や勘定に関するコード,それらを分類するコードなどが,自社には一体何種類あるのか。さらに,どのように運用されているのか。集中的な棚卸し調査によって,明確にすべきである。集中的な調査が難しい場合でも,部分的に実施した調査の結果を1カ所に集めて管理する仕組みづくりは必須(ひっす)だ。
勘所(2)
データの粒度で妥協するな
既存システムから抽出すべきデータを決定する段階では,「ソース・データの粒度で妥協しないこと」が重要である。安易に粒度の大きなデータを選んでしまうと,データ・ウエアハウス/データ・マートの寿命を短くしかねない。
例えば「売上高」のデータは,既存システムの中のあちこちに,さまざまな粒度のものが散在する。典型的なあやまちは,「とりあえず,現在の分析ニーズは満たされる」という理由から,ある程度要約された(粒度の大きい/件数の少ない)売上高データに対してインタフェース・プログラムを作ってしまうことだ。ソース・データの件数が非常に多い場合は,この傾向がいっそう強くなる。
しかしながら,要約されたデータは当面の分析ニーズに対応できても,将来の潜在的なニーズにはこたえられない危険性が極めて高い。より詳細な分析ニーズや別の切り口の分析ニーズが顕在化したときに対応できなくなる。
ソース・データの粒度で妥協することは,「最後の手段」と位置付けるべきである。実際,データ・ウエアハウス/データ・マートで成果を上げている企業は,最後の最後までソース・データの粒度の細かさにこだわっている。彼らは,拡張性を犠牲にするリスクの大きさをよく理解しているからだ。
拡張性の乏しいインタフェースを作ると,いずれまた同じソース・データに対して類似のインタフェースを追加する,という悪循環に陥ることになる。こうなると,保守対象が増えてしまうし,整合性の管理も難しくなる。
データ・ウエアハウス/データ・マートは,ユーザー要件の高度化とともに成長すべきもの。「見えないニーズもニーズのうち」と心得ることがなにより大切である。



















































