|
皆さんは,企業のシステムが提供している情報(データ)をどれくらい信用していますか。
例えば,社内の製品担当者に問い合わせをしたい場合,社内システムを使って,製品から担当者を割り出し,担当者名から電話番号を検索,その電話番号に電話をかけてみるでしょう。この場合,社内システムから得られる情報はおおむね信用できるでしょう。製品担当者の変更が更新されていないといったこともあるかもしれませんが,そのような場合は社内であれば引き継ぎ担当者を教えてもらうことで状況を理解できるので,まずは情報を信じて電話をかけてみるのではないでしょうか。
では,社外のお客様へ連絡するときはどうでしょうか。この場合は少し慎重になるでしょう。社内情報を検索するとき以上に各種システムから信用できる必要な情報を慎重に収集し,行動に移すはずです。私の友人のA君もそうでした。
使えないデータたち
A君はある電気製品の販売を担当する営業マンです。以前に取引があったお客様に,新しい商品のPRをしようとして,そのお客様との最近の取引履歴を調べました。A君の会社では,お客様との折衝情報を全社的にシステムで一元管理しています。そこからお客様の最近の動向・関心事項・ニーズなどを推測し,営業活動につなげるわけです。
A君もそのシステムから入手した情報から,新商品の強みをお客様に理解していただき,商談できそうであることを確信しました。善は急げ,お客様に連絡をとりましょう。まずは季節のご挨拶から始めましょう。完ぺきです。
しかし……いざ電話をかけてみると,お客様から「こっちも忙しいのだから,何度も同じような電話をしてくるな」と怒られてしまいました。久々に連絡を取ったのに,なぜこのように言われてしまったのでしょうか。挨拶が失礼にあたったとは思えません。
不信に思ったA君は,もう一度,お客様情報を社内システムで検索しました。やはり,前回の折衝履歴は5カ月前になっています。そのときもお客様との関係は良好と記載されています。怒られる要素は見つかりませんでした。
落ち込んだA君は,隣の課のB君に相談してみました。すると,B君の話によれば,なんとB君の上司が同じ会社を先週訪問したというではないですか。嫌な予感がしたA君は,B君の上司の名前で社内システムを再検索してみました。案の定,昨日A君が電話したお客様と先週打ち合わせを行い,提案が断られた議事録が載っていたのです。A君は急いでB君の上司に事情を話し,B君の上司が次回お客様に連絡したときにお詫びすることで,なんとか解決したそうです。
A君の行動におかしいところはありません。また顧客管理システムも特に不備があったという報告はなされていません。データも信頼できるものであったようです。では,どこに問題があったのでしょうか?
実はA君が検索したお客様名とB君の上司が登録していたお客様名が異なっていたのです。どちらかが間違った情報を入力していたというわけではありません。A君はお客様名を「株式会社エービーシー」(仮称)で検索しましたが,B君の上司は「(株)エービーシー」で登録していました。人間が見れば,それが同じものとわかりますが,システムでは全く異なるお客様として扱われてしまったため,A君はB君の上司の登録内容を見落としてしまったのです。
さらによく調べてみると,他にも「エービーシー」「エー・ビー・シー」「エービーシー 丸の内支店」「ABC社」「A・B・C」という形での情報登録もありました。このシステムでは,お客様の入力制御・入力規則が決められていなかったため,登録者により入力表現がまちまちになっていました。どの情報もデータとしては不正ではないため,システム上は問題なく登録されていました。個々のデータとしては問題のないデータなのですが,総合的な判断をする場合に利用しようとすると「使えないデータ」だったわけです。
以上のような「使えないデータ」は,データの蓄積対象範囲が大きくなればより顕著となり,また関連するシステムが多ければ多いほど問題の発生リスクが高くなります。またそのデータを企業戦略に役立てるための分析などに用いようとした場合,ビジネスに与えるインパクトは大きくなります。
一般の企業では,「顧客コードで管理しているから大丈夫」「データを何度か検索すれば整理できる」といった声も聞かれます。本当にそうでしょうか。皆さんの記憶に新しいところで「金融機関のペイオフ対応」に関して考えてみましょう。
2005年に解禁した銀行のペイオフ対応では,金融庁は金融機関の破綻に備え,金融機関ごとに口座を持っているお客様の資産を特定するために,同一金融機関で同一顧客の口座情報をまとめて,資産状況を報告することを義務化しました。当初各金融機関からは,十分な準備ができているとの報告がありましたが,その後のニュースで対応が不十分との指摘を受けたことが報じられていました。なぜ対応が不十分と言われたのでしょうか?
口座を作る際,口座番号・氏名・住所・電話番号は一つの情報(レコード)として登録され,口座番号をキーとして口座の管理が行われるのが一般的です。ペイオフ対応では,どの口座とどの口座が同一顧客であるかという口座番号の対応表を作れば良いことになります。各金融機関は当初,氏名・住所・電話番号をキーにグループ化して集計をとれば大丈夫だと判断しました。
しかし,この氏名・住所・電話番号をキーにした集計が思った以上に難航したのです。それは,A君の話にもあったように,情報が微妙な表記の差異を含んだまま登録されているケースが多数存在することが原因でした。氏名・住所・電話番号を,必ず同じ表記で登録していれば何の問題もなかったと思います。こうした理由により,ペイオフ対応は不完全との指摘を受けたのでした。それでは,ペイオフ対応が難航した原因をもう少し詳しく見てみましょう。
使えないデータはなぜ発生するのか
金融機関のペイオフへの対応が非常に難しくなっているのは,もとからある口座のデータが同一顧客を特定することを考慮していないためです。ただ顧客の要求に従って口座を作って管理すれば良く,口座数の多さが獲得顧客数という営業成績に関連するため,口座開設の時点でのチェックも行われないという背景もあったと思われます。
つまり,同一顧客を特定するようなニーズはなかったのです。例えば,次のような口座データを持っていれば十分です。
店番号:999 口座番号:99999999 お客様氏名:斎藤 太郎 お客様住所:東京都文京区xxx 9丁目9-9 アーバンコーポ201号室 お客様電話番号:03-9999-9999
ここで,店番号・口座番号でユニークな値としておけばデータの重複はなく,あとは本人の連絡先がわかれば十分です。さらに,同じ顧客が次のような口座を新しく作ったとします。
店番号:777 口座番号:7777777 お客様氏名:斉藤 太郎 お客様住所:文京区xxx 9-9-9-201 お客様電話番号:070-777-7777
ここでも,店番号・口座番号でユニークな値としておけばデータの重複はないし,本人の連絡先もわかるので十分管理でき,特に問題ありません。しかし,ここで銀行のペイオフ対応のような,二つの口座が同一人物であるかどうかを判断しなければならない状況となったとき,問題は発生します。
人間の目で見れば,上記の二つの口座が同一人物のものらしいことはおおよそ想像できます。氏名の姓の部分が「斉藤」と「斎藤」というふうに漢字が異なっていますが,おそらく旧漢字ではなく,一般的な新漢字を使ったのでしょう。前者の住所では「東京都」や「丁目」が抜けていますが,省略して書くことはよくあります。電話番号も異なりますが,前者は家の電話で,後者は携帯電話の番号だと考えられます。このようなことを総合的に判断して,ほぼ同一人物であると判断できます。
しかし,多量のデータに対して,単純な検索機能を使ってこのようなデータをすべて割り出していくのはとても大変な作業であり,状況や件数によっては不可能な場合もあります。もし今から,口座の管理システムを作成するのであれば,ペイオフに対応できるようなデータ構造にするでしょう。新漢字,旧漢字の入力方法をあらかじめ定義したり,住所の入力書式を統一したりして,同一人物の特定がしやすいようにするでしょう。しかし,現在あるデータは,同一人物かどうかを特定するケースを想定していないために,対応できないことがあるのです。
このように“システムを作成するときには考慮されていなかった観点でデータを使おうとしたとき”に「使えないデータたち」は発生します。しかし,使えないデータだからと言って捨ててしまうことはできないでしょう。なぜなら,そのデータは今まで使っていたデータであり,これからも使うデータだからです。
マスター統合で「使えないデータたち」が浮き彫りに
企業はシステム改善を適宜行っているので,上記のような「使えないデータたち」はその都度発生することになります。例えば,企業合併などで異なるシステムを連携させるために,マスター・データを統合する場合を考えてみましょう。ここで言うマスター・データとは,企業内で業務を行う上でキーとなるデータのことで,企業が持つ資産を特定するデータのことです。製造現場では部品コード,販売現場では商品情報,マーケット部門では顧客情報などがマスター・データと言えるでしょう。
企業には様々なシステムが存在します。そして各システムが個別に最適化を図って別々なマスター・データを作り上げています。個別に最適化を行っていくと,その先では各システムを連携したいという要求が出てきます。しかし,複数システムにマスター・データが散在するため,その連携は非常に難しいのが現状です。
マスター・データが散在するために,企業はどのマスターが“本当に正しい”データなのかを判断するのに非常な労力を使う,というのもよくある話です。“本当に正しい”というのは,システム部門ごとに異なることがあり,この違いが企業活動を阻害する要因となっているのです。だからこそ,マスター・データを統合する必要が出てきます。
しかし,各マスター・データはそれぞれのシステムに最適化されているので,単純に統合するといっても,データ構造の見直しが必要であり,それは骨の折れる作業です。さらに,ここで思い出して欲しいのが「使えないデータたち」の発生過程です。
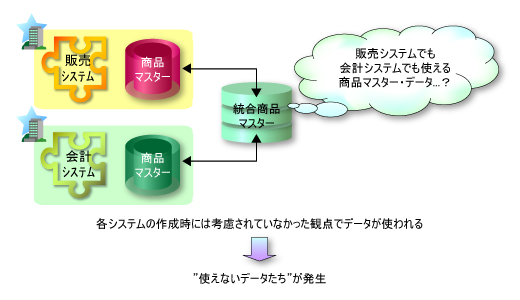
統合することですべてのシステムから参照されるマスター・データになるわけですが,既存の各マスター・データから考えると,それはまさにシステム作成時には考慮されていなかった観点でデータが使われようとしているわけです(図1)。つまり,既存のマスター・データを移行して使おうとすれば,必ずそこには「使えないデータたち」が発生してしまいます。これがマスター・データの統合を難しくしている原因の一つとなっています。
|
|
| 図1●マスター統合のイメージ。既存のマスター・データを移行して使おうとすると,「使えないデータたち」が発生する可能性がある |
では,使えないデータを使えるデータにするにはどうすれば良いのでしょうか。その作業は「データ・クレンジング(Data Cleansing)」と呼ばれます。つまり,データを“ごしごし”こすってきれいなデータにする行為です。具体的に説明しましょう。
例えば,氏名のデータとして苗字と名前が入っているとします。苗字と名前が続けて入力されているものもあれば,半角スペースがはいっているもの,全角スペースがはいっているものもあります。この場合のデータ・クレンジングとしては,半角/全角スペースを取り除く,という行為になります。
「03(9999)9999」「0399999999」といった電話番号のデータを「03-9999-9999」の形式に補正することもデータ・クレンジングです。また,成人コードという欄に「1:成人」「2:未成年」「3:年齢不詳」という定義がされている場合に,“4”というデータがあったとします。このような未定義のデータを,成人とも未成年とも判断がつかないため不正データとして“3”に修正することもデータ・クレンジングになります。
さらに高度なデータ・クレンジングとしては,次のような例があります。顧客コードと性別コードがセットであったとします。ここで,顧客には法人と個人の2種類があります。個人であれば,男性/女性コードが入力されているとします。ところが,法人なのに“男性”というデータが入力されていたらどうでしょうか?
これは「法人」という入力が間違っているので「個人」とするか,「男性」という入力が間違っているので削除するか,のどちらかを判断しなくてはなりません。これもデータ・クレンジングです(ただしこの場合,どちらが間違っているかはわからないので,この情報だけではデータ・クレンジングはできません)。
まとめると,データ・クレンジングとは,システムが想定している正しいデータに修正することです。
名寄せの手順
ところで,データ・クレンジングに似た言葉として「名寄せ」というものがあります。名寄せはデータ・クレンジングをした結果,データ間の関連性を導き出す行為です。金融機関のペイオフ対応の例で言うと,同一顧客を導き出す行為が名寄せとなります。
重複データを特定するという観点では,名寄せもデータ・クレンジングの一環です。しかし,データ・クレンジングなしに名寄せは実現できません。ちょっとややこしい関係ですね。今後,名寄せを行う手段を説明するなかで,もう少しわかりやすく説明したいと思います。
まずは,名寄せは同一データを特定するための作業だと考えてください。名寄せの作業は,「調査」→「標準化」→「類似データの絞り込み」→「同一データの決定」といった手順で構成されます(図2)。
|
|
| 図2●名寄せ技術は,一連の手順で構成される |
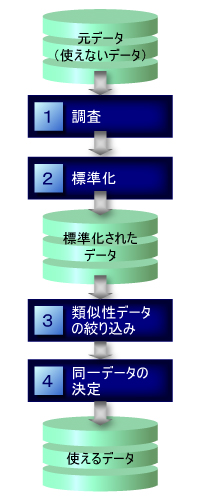
調査では,各データの何をキーに名寄せを行うかを決定します。標準化では,元データを相互比較しやすい形式に再フォーマットします。類似データの絞り込みでは,再フォーマットされたデータを互いに比較し,どれくらいの確度で同一データであるかを数値化したりパターン化したりすることで絞り込みます。同一データの決定では,絞り込まれた類似データに対して,どのデータを同一データであると決定するかどうかを考えます。
次回以降,個人データの名寄せを例に具体的に説明していきます。




















































