|
前回,前々回と,複数のプロセス,複数のスレッドがどのような仕組みで同時に実行できるかについて説明をしてきた。その中でも少し触れたが,複数の処理が並行して実行される場合には,ある重要な問題を考慮しなければならない。「同期」である。
単独で動作するシングル・スレッドのアプリケーションしか書いたことがない人にはなじみのない言葉だろう。しかし同期は,Windowsだけでなく,並列処理が可能なシステムでは,必ず考慮しなければならない事項である。これは,プログラム言語としてマルチスレッドをサポートしているJava言語に,同期を実現するためのキーワードが定義されていることからも,うかがい知ることができるだろう。
マルチプロセスとマルチスレッドについて説明してきた以上,同期の話をしないと区切りが付かない。というわけで,今回はWindowsに用意されている同期の仕組みの数々をご紹介したい。
同期とはなにか
一般的に考えても「同期」という日本語は,少しわかりにくい言葉かもしれない。「同期入社」のように,単に同時に処理が開始されれば同期というわけではないし,ただ並列に処理することそのものを同期というわけでもない。
マルチタスクで「同期」という場合には,複数のタスクがお互いの間で取り決めたやり方でタイミングを合わせつつ,処理を進めることを意味する。例えば,全く関係がない独立した処理であれば,それぞれ勝手に進行してしまっても問題はない。実際,日頃Windowsで使用しているアプリケーションのほとんどは,特にほかのアプリケーションを意識せずに動作しているのだ。
しかし,マルチスレッドや,複数のプロセスから構成されているシステムでは,そういうわけにいかない。第1回で紹介したような,別に起動したプロセスの終了コードの値によって,次の処理の内容を決めるケースが一つの典型例だ。このように,別のタスクとの間で,処理結果を渡したり渡されたりするために待ち合わせるのが,同期の一つの側面なのである。
また,同期のもう一つの側面として,共用するリソースの使用権の制御がある。リソースとは,プログラムから利用できる何らかの「もの」のことである。これには,ウィンドウやファイル,メモリーといったWindowsのオブジェクトのほかに,ディスプレイやプリンタ,ハードディスクなどの物理デバイスも含まれる。
リソースの中には,複数のプロセスやスレッドから共用できるものがあるが,無秩序に同時アクセスすると問題が起きる場合がある。例えば,二つのタスクが同じファイルの読み書きを同時に行うケースを考えてみよう。一方が読み込んでいる間に,もう一方がそれを書き換えてしまうと,途中から突然データが変化して,全体としてつじつまの合わないものになってしまう可能性がある。
このように,リソースの共用を正しく行うためには,アクセスを調停する仕組みが必要になる。実際,物理デバイスの場合には,デバイス・ドライバとOSがその役を担っているし,ファイル・システムの場合は排他制御のオプションを指定できるようになっている。
しかし,そういった仕組みで保護されていないリソースもある。その代表格がメモリーだ。もっと簡単に言えば,プログラムで使用する変数である。複数のタスク間でデータを受け渡す必要がある場合,メモリーを共用するのが簡単だ。マルチスレッドであれば,メモリー空間が共通なので,なんら特別な準備もなく,複数のスレッドから同じ変数を読み書きすることができる。
マルチプロセスでも同様だ。プロセス間でメモリーを共有する方法についてはまだ説明していないが,いったん共有してしまえばあとは同じである。共有された変数にそれぞれのプロセスから読み書きするだけで,簡単にデータのやり取りが可能になる。半面,それぞれのプロセスが勝手なタイミングでアクセスが可能なため,問題が起こることがあるのだ。
アトミックな処理で競合を防ぐ
例えば,HTTPサーバーがクライアントからの要求を処理するために,それぞれスレッドを割り当てるケースを考えて欲しい(図1)。ここで,サーバー起動時点からの累計処理数をカウントするために,グローバルな変数を用意する。各スレッドは処理の開始時にその値を読み込んで,完了時に一つ増やした値を書き込むものとする。果たしてこのカウンタは正しい値を示すだろうか。
|
|
| 図1●サーバーがクライアントのリクエストごとにスレッドを生成して処理するイメージ |
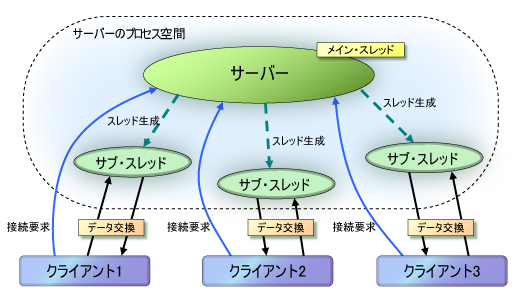
実は,このカウンタは正しい値にならない可能性が高い。「可能性が高い」というあいまいな言い方になっているところがミソだ。クライアントからのアクセスが来る頻度とタイミング,処理にかかる時間によって,問題が起きたり起きなかったりするのである。たまたま複数の処理が重ならないタイミングでしか要求が来なければ,問題は起こらない。しかし,少しでも重なれば,即座におかしくなる。
図2を見れば一目瞭然だろう。スレッド1の処理中にスレッド2が開始された場合,どちらのスレッドも変数countから読み込む値は同じ値(仮にxとする)になる。スレッド1は先に終了して,このときcountに「x+1」の値を書き込む。ここまではよい。しかし,スレッド2が終了するとき,countに書き込まれるのは「x+2」ではなく,「x+1」なのである。二つの処理が完了したにもかかわらず,カウンタが一つしか増えないのだ。
|
|
| 図2●二つのスレッドが同じ変数にアクセスすると,タイミングによっては正しい結果を得られないことがある |
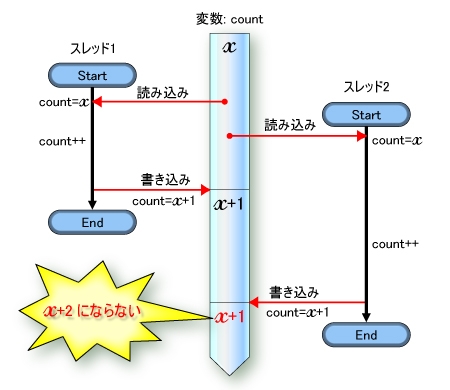
そもそもカウンタの読み込みと書き込みの間に,時間差がありすぎることが問題だと思うかもしれない。では,読み込んだ直後に,1増やした値をcountに書き込めばよいのだろうか。ことはそう簡単ではない。countを読み込む操作と1増やす操作,書き込む操作という三つの操作が独立していることに変わりはないからだ。
x86系のCPUであれば,アセンブラ・レベルで少なくとも三つの命令になるだろう。そうすると,命令と命令の狭間で,タスク・スイッチが起こる可能性がある。どんなに命令と命令の間隔を短くしても,命令が一つにならない以上,命令と命令の間でタスク・スイッチは起こり得るのだ。それでは結局図2と同じことになる。
このように,タスク・スイッチが起きる環境では,タスク・スイッチで分断されることなく一気に実行できるかどうかが一つのキーになる。これを「それ以上分割できない単位の処理」という意味で「アトミックな処理」という。これは,それ以上分割できない物質の最小構成単位「原子(atom)」に由来する用語である。
Windowsの場合,頻繁に行われるような特定のケースについては,APIとしてアトミックな処理方法が提供されている(表1)。前述の“変数の値を1増やす”という例も,このAPIを使えばアトミックに処理できる。
表1●アトミックな処理を可能にするAPI| 機能 | 関数のプロトタイプ |
| 引数(Addend)が指す変数の値を1増やす。戻り値は増やした後の値 |
LONG InterlockedIncrement( LONG volatile* Addend) LONGLONG InterlockedIncrement64( LONGLONG volatile* Addend) |
| 引数(Addend)が指す変数の値を1減らす。戻り値は減らした後の値 |
LONG InterlockedDecrement( LONG volatile* Addend) LONGLONG InterlockedDecrement64( LONGLONG volatile* Addend) |
| 引数(Target)が指す変数に,指定値(Value)をセットする。戻り値は,セットする前の値 |
LONG InterlockedExchange( LONG volatile* Target, LONG Value) LONGLONG InterlockedExchange( LONGLONG volatile* Target, LONGLONG Value) PVOID InterlockedExchange( PVOID volatile* Target, PVOID Value) |
| 引数(Destination)が指す変数の値が,比較値(Comperand)に等しい場合,その変数に指定値(Exchange)をセットする。戻り値は,セットする前の値 |
LONG InterlockedCompareExchange( LONG volatile* Destination, LONG Exchange, LONG Comperand) LONGLONG InterlockedCompareExchange64( LONGLONG volatile* Destination, LONGLONG Exchange, LONGLONG Comperand) PVOID InterlockedComparePointer( PVOID volatile* Destination, PVOID Exchange, PVOID Comperand) |
しかし,アトミックな処理が用意されているのは,あくまでも特殊なケースである。そもそも,アトミックな処理は,タスク・スイッチを妨げることになるため,マルチタスクの処理効率に影響を与える可能性もある。したがって,あまり時間がかかるような処理を,アトミックに処理すべきではない。何か別の仕組みが必要になる。



















































