見落とされがちだが深刻なメモリー・アラインメント問題
|
今回は,既存のCソースコード資産をW-ZERO3(Windows Mobile)に持ち込む場合に発生するメモリー・アラインメント問題について説明する。
具体的にどのような問題であるか,それは歴史的にどこから来たのか,対処方法としてどのような方法があるか,そしてワンべぇでは実際にどのように対処方法を決定したのかを書いていこう。
どのような問題であるか
要するに,リスト1のコードはx86アーキテクチャのデスクトップPCでは問題なく実行できるが,W-ZERO3では実行できないということである。今回の内容は,その理由と解決方法を説明するものである。
|
| リスト1●W-ZERO3では実行できないコード例 |
この問題を適切に説明するためには,基礎的なハードウエアについての知識が必要である。もし「CPUの性能が上がったので,ハードの知識など持たなくてもプログラムは書ける。いや,むしろ変なテクニックを駆使して保守性の悪いプログラムを書く危険があるから,ハードの知識など持たないほうが良い!」という妄想的な信念を誰かに押し付けられているなら,即座にそれを捨てて続きを読んでいただきたい。
最低限のハードウエアに関する基礎知識を持たずに,プログラムが書けるほど甘いものではない。まして,リソースに制限のある携帯デバイスではハードを意識せずに優れたプログラムは書けないだろう。
さて,本題に入る。メモリー・アラインメント問題とは,純粋にCPUのアーキテクチャ,つまりハードウエアの設計によって発生する問題である。これは,CPUがメモリーを読み書きする際に,すべてのアドレスに対して読み書きを実行できるわけではない──という問題である。
いや,そんなことは当たり前だろうと思った読者も多いと思う。しかし,メモリーが実装されていない領域に書き込むことはできないし…と思ったのなら間違いである。メモリーが確かにあり,それに正常に読み書きができるにもかかわらず,そのメモリーに対する読み書きができないケースが存在するのである。
そんなバカな!と思う読者も決して少なくはないと思う。それはもっともなことである。多くの読者が使用しているx86アーキテクチャのCPUには,そのような制約は存在しないからだ。それゆえに,x86アーキテクチャのCPUを使う限り,それがIntel製だろうとAMD製だろうと関係なく,使用するOSがWindowsであろうとLinuxであろうと関係なく,そのような制約に遭遇することは無い。
ところが,世の中に存在するCPUを並べてみると,実は制約のあるCPUのほうが多数派であることがわかる。初代MacintoshのCPUとして採用された68000とその後継CPUを始め,世の中を見回すと制約のあるCPUだらけである。
必然的に,x86アーキテクチャ以外のCPUを扱おうとすると,このような制約に遭遇する確率は高い。それは,XScaleアーキテクチャのCPU(PXA270)を搭載するW-ZERO3であっても例外ではない。
つまり,Pentiumシリーズなどのx86アーキテクチャのCPUを搭載したデスクトップPCで可能だったプログラミング・テクニックが,W-ZERO3では通用しない可能性がある。
技術面から見た問題の詳細
まず,CPUとメモリーとアドレスの関係をおさらいしてみよう。よくある32ビット・アーキテクチャのCPUの例を図1に描いてみた。これはあくまで説明の便宜上のもので,実際のCPUやシステムはこれと食い違っていることが多いことをお断りしておく。
|
|
| 図1●メモリーのアーキテクチャ |
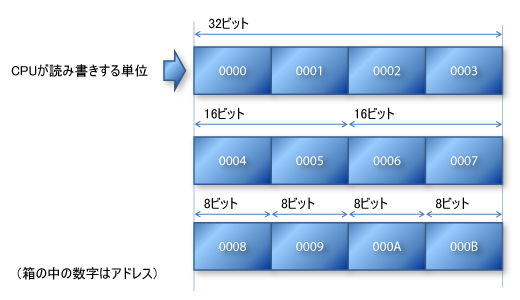
この例では,CPUが読み書きする単位は32ビットである。つまり,CPUとメモリーは32ビットのバスと呼ばれる情報経路で結ばれているわけである。できるだけ効率よく実行しようと思うなら,この32ビットのバスを余すところ無く使うために,32ビット単位でデータを処理すると良いことがわかる。
しかし,データにアクセスするために使用するアドレス(データの所在地)は,8ビット単位で与えられていることに注意が必要である。その結果,32ビットのデータをメモリーから取得した後,次の32ビット・データをメモリーから取り出すためには,アドレスの値を+1するのではなく,+4しなければならない。
こうした動作は,通常コンパイラが自動的に処理してくれるので,プログラマが意識する必要はない。例えば,よくある32ビット用のC言語処理系で,32ビット整数を扱うポインタに1を足すと,コンパイラは実際には4を足すコードを生成してくれる。
このような構造なので,32ビットのデータを4分割して,8ビット単位で扱うことも容易である。アドレスに4を足さずに1を足せば,次の8ビット・データを指し示すことができるわけである。もちろん,32ビットと8ビットの中間サイズの16ビットで扱うこともできる。この場合,アドレスは2ずつ足していけば良いのである。
このようなアーキテクチャのおかげで,32ビットでは無駄の多いデータを8ビットあるいは16ビット単位で扱うことができ,効率がアップしている。
(余談だが,すべてのCPUがこのような構造を持っているわけではないことに注意が必要である。実際には,CPUが読み書きする単位とアドレスが常に一致しているアーキテクチャもある。こういったアーキテクチャは昔のミニコンや8ビットCPUによく見られる。ちなみに,8ビットCPUが持つ16ビット単位でメモリーを読み書きする命令を使った場合,実際にメモリーに対して行われるのは16ビット単位の読み書きではなく,8ビット単位の読み書き2回であることに注意が必要である)
さて,ここからが問題である。
アドレス0を指定して32ビット・データを読み書きできるのは問題ない。まさにCPUとメモリーがデータを交換する単位と一致しているからだ。しかし,もしもアドレス1を指定して32ビット・データを読み書きしたいと思ったら,どうなるだろうか? また,16ビット・データであっても,切りの良い偶数アドレスではなく,奇数アドレスを指定したらどうなるだろうか?
|
|
| 図2●半端なアドレスを指定したら? |
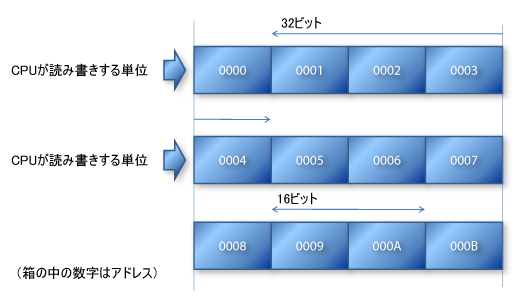
このようなアクセスを許すCPUと許さないCPUが世の中には存在する。許すのがx86アーキテクチャであり,許さないのがW-ZERO3のXScaleアーキテクチャ(などの多数派)である。
なぜ許されないのか?
なぜこのようなアクセスを許さないのだろうか。許せばプログラマの自由度が上がり,好きなようにプログラムを作成でき,効率が良いように思える。
だが,ハードウエアの設計者の立場になったつもりで考えてみると,必ずしもそうとばかりは言い切れないことがわかる。
まず,半端なアドレスの32ビット・アクセスについて考えてみよう。このようなメモリーの読み書きを行うためには,メモリーに対する読み書きを2回行わねばならないことがわかると思う。「CPUが読み書きする単位」をまたいだ形でデータが存在するからだ。
一つのデータの読み書きで2回のメモリーのアクセスを発生させるというのは,より複雑な回路をCPUに搭載しなければならないことを意味する。回路の複雑化は,一つのチップ上に乗せられる他の機能を圧迫したり,消費電力や発熱量を増やしたり,あまり嬉しくはない副作用を連れてくる。
では,そのような副作用を我慢してまで採用する価値のある機能かといえば,そうとも言えない。なぜなら,このような半端なアドレスでのアクセスが必要とされる機会は滅多に存在しないためである。滅多にない状況に対応するために消費電力や発熱量を増やす価値はあまり無い。むしろ,割り切って「できない」ことにしたほうが,利用者にとってはハッピーだろう。
次に,奇数アドレスの16ビット・アドレスの例はどうだろうか。このあたりの説明は,私も専門ではないので不正確かもしれないので,眉に唾を付けて読んでいただきたい(ほかの説明もそうだが)。この例は,読み書きの単位の境界をまたいでいないので,2回のアクセスを要求されることはない。しかし,実はこれも回路の複雑化を招くのである。なぜなら,半端なアドレスから読み込んだデータも,CPU内部で一度桁の位置をそろえねばならないからだ。
|
|
| 図3●半端なアドレスから読み込んだデータも,CPU内部で桁の位置をそろえる必要がある |
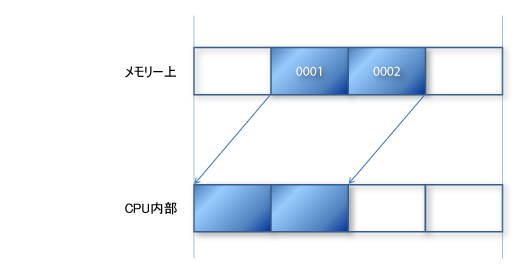
Cプログラマなら,これを見て「シフト演算子でできる」と思うかもしれない。その考えは正しい。このような処理そのものは,全く難しくはない。
だが,CPUの実行をスローダウンさせないように素早く実行させるのは楽ではない。すべてのビットが,一瞬であるべきビットに移動しなければならないのだ。それゆえに,これも回路の複雑化を招き,同じ理由で好ましい結果を生まない。
また,このようなアクセスが滅多に発生しないのも同じである。効率を重視するなら,このようなアクセスは許さないという仕様にするのが合理的というものである。
しかし,そうは言っても,x86アーキテクチャは合理的ではない構造になっている。それはなぜだろうか? 少し歴史を遡ってみよう。



















































