最近,並列計算(parallel computing)や分散計算(distributed computing)の話題をよく見かけるようになってきました。Peer to Peer(P2P)のアプリケーションとして広く知られるSETI@home,Mac OS XのXgridなどのグリッド・コンピューティング(grid computing),複数のプロセサを持つマルチプロセサ(multi-processor)や複数のプロセサ・コアを持つマルチコア(multi-core)のコンピュータ,様々な並列/分散処理を直接サポートしたプログラミング環境――こうした技術がパソコンや家庭用ゲーム機といった身近な環境で使われるようになっています。注目を集めているプログラミング言語Erlangや米Googleの分散処理システムであるMapReduceのような「並列/分散プログラミングでの煩雑さを解消するための技術」に興味がある人も増えているのではないでしょうか?
そこで今回から数回にわたって,GHC 6.6.xのSMP(Symmetric Multiple Processor,対称型マルチプロセサ)サポートによって加わった並列化機能とそれらを使った並列プログラミングについて見ていきたいと思います。なお,本文中で提示した機能を試す場合には,2007年4月26日にリリースされたGHC 6.6.1以降のバージョンを使ってください。GHC 6.6の並列化機能にはいろいろなバグがあるためです(6.6.1でもすべての問題が解決されているわけではありません。第8回のコラムで説明したpseq関数が定義されているモジュールのように,互換性等の問題からGHC 6.6.xの間はあえて修正しないことが決定している問題点もあります)。
並行/並列/分散プログラミングの定義
まず混乱を避けるため,並行性(concurrency),並列性(parallelism),分散性(distribution)のそれぞれの定義を提示しておきましょう。
- 並行計算(concurrent computing)は,論理的に計算の単位を分けるものです。計算はプロセサごとに割り振られても,そうでなくてもかまいません。例えば,複数プロセサ環境で,OSのネイティブ・スレッド(native thread)を使って並列計算を行うなら,計算はOSによって適切にプロセサに割り振られるでしょう。もしプロセサが1個だったり,プログラミング言語等のユーザー・レベル・スレッド(user-level thread)で計算を行うなら,計算は単一プロセサによって行われます。あるいはネットワークを介した分散システムの上で計算が行われるかもしれません。計算がどのように行われるかは環境や実装に依存します。並行計算は,一般に,計算の高速化よりも複数タスク(multi-task,マルチタスク)での相互作用(interaction)を重視します(参考リンク)。
- 並列計算(parallel computing)は,ある一つの計算を,複数プロセサで行うことで,処理速度を向上させるものです(参考リンク)。
- 分散計算(distributed computing)は,ネットワークを介して互いに離れたところにある複数の計算資源を使い,ある一つの計算を行うものです。並列計算と目的が同じため,広義の並列計算に含まれることもあります。分散計算という用語を特に並列計算と区別するのは,ネットワークを介しているかどうかが問題になる場合です(参考リンク)。
このうち分散計算は,現在のGHCはサポートしていません。GHCの並列化機能の一部は,GPH(Glasgow Parallel Haskell)の実装が基になっています。GPHでは,PVM(Parallel Virtual Machine)やMPI(Message Passing Interface)を利用した分散計算が可能です。しかし,GHCとGPHは開発主体が違うため,GHCはデフォルトでは分散計算をサポートしないという方針を採っています(参考リンク1,参考リンク2)。今のところ,分散プログラミングを行うには,GPHまたはGHCを拡張した他の処理系などを使用する必要があります。
並行/並列/分散計算は,完全に別個のものとして切り分けられているとは限りません。実際のプログラミングでは,これらが混在した形で行われることが多いでしょう。とはいえ,処理が「どのような側面を重視して行われているのか」を示すには,これらの区別は有用です。例えば,ある処理が「並行プログラミング」と呼ばれていれば,分割された計算同士の相互作用が主な問題であることがわかります。「並列プログラミング」なら,どのようなプログラミング・スタイルを採用しているかにかかわらず,並列計算が目的であることがわかるでしょう。
並列Haskell
GHCには,並列プログラミングを行うための方法が三つ存在します。
一つは,OSのネイティブ・スレッドを直接利用する並行プログラミングによって並列計算を行う方法です。この方法は,並列化のための機能を特に持たない一般的な言語でもよく使われています。ただ,すべての操作を制御できる一方で,プログラムの動作に非決定性が持ち込まれてしまうため,プログラムが複雑になりデバッグしにくいという欠点があります。I/Oアクションなど本質的に競合が起こる可能性のある計算以外では,この方法は使わないほうがよいでしょう。
もう一つは,ある式の部分式(sub-expression)の評価の並列性を明示的に制御するという方法です。これを「コントロール並列(control parallel)」と呼びます。仕事単位で分割して並列化することから「タスク並列(task parallel)」と呼ぶこともあります。GHCやGPHには,正格評価を行うための関数seqにちょうど対応する形で,並列に評価を行うための関数parがControl.Parallelモジュール(またはGHC.Concモジュール)に存在します。par関数やそれを補助するモジュールを提供する拡張機能を「並列Haskell(Parallel Haskell)」と呼びます(参考リンク)。
Prelude Control.Parallel> :t par par :: a -> b -> b
ただ,GHC 6.6.xのControl.Parallelモジュールには問題があります。第8回のコラムや今回の冒頭で説明したように,pseq関数はGHC.Concモジュールにしか定義されていません。Control.Parallelモジュールで利用できるのはGHCの開発版やGHC 6.8以降です。そこで,互換性の問題を解決するために,これらの違いを覆い隠すラッパー・モジュール(wrapper module)を用意しましょう。Parallel.hsファイルにParallelというモジュールを定義し,これを利用します。
module Parallel (par, pseq) where #if __GLASGOW_HASKELL__ < 607 import GHC.Conc (par, pseq) #else import Control.Parallel #endif
最初の行がParallelモジュールの宣言です。( )の中に記述されているparとpseqだけがエクスポートされます(参考リンク)。同様に,GHC.Concモジュールのインポート宣言でも,parとpseqだけをインポートするよう明示的に宣言しています(参考リンク)。
先頭に#が付いた行は何でしょうか? 実はCプリプロセサの宣言です。標準HaskellやGHCには,「処理系のバージョンによって違う内容を扱う」ための指示文(pragma)や関数は特に存在しません。Cのプリプロセサで前処理(preprocessing)を行うことで,モジュールの内容を制御しています。こうしたやり方は,Haskellではよく使われています。GHCでは-cppオプションを使うことでCプリプロセサを利用できます(参考リンク)。HugsでCプリプロセサを利用するには,-Fオプションにコマンドを与えます(参考リンク)。
Parallelモジュールを使用できることを以下のようにして確認します。
Prelude> :l Parallel Parallel.hs:1:1: lexical error at character 'i' Failed, modules loaded: none. Prelude> :set -cpp Prelude> :l Parallel [1 of 1] Compiling Parallel ( Parallel.hs, interpreted ) Ok, modules loaded: Parallel. *Parallel> :t pseq pseq :: a -> b -> b *Parallel> :t par par :: a -> b -> b
では,実際に並列プログラミングを行ってみましょう。クイックソートの並列化版です。まず,このような定義を考えてみます。
quicksort :: (Ord a) => [a] -> [a]
quicksort [] = []
quicksort [x] = [x]
quicksort (x:xs) = losort `par`
hisort `par`
losort ++ (x:hisort)
where
losort = quicksort [y|y <- xs, y < x]
hisort = quicksort [y|y <- xs, y >= x]quciksort関数の型定義に文脈として付けているOrdクラスは,ある型の大小を比較できるように順序付け(ordering)するものです。このクラスのインスタンスにすることで,<や>=といった比較演算子を使用できるようになります(参考リンク)。
quicksortの関数定義部分では,par関数によってlosort,hisort,losort ++ (x:hisort)の3式の評価を再帰的に並列化しています。しかし,これは決して良い定義ではありません。par関数を使った評価ももちろん遅延評価なので,第8回で説明した弱頭部正規形(WHNF:Weak Head Normal Form)までしか簡約してくれません。この結果,losortとhisortはごくわずかの仕事しか行わず,効率化はあまり期待できません。
この問題を解決するには,losortとhisortの部分では先行評価し,完全にソート済みのリストを返すように定義を書き直す必要があります(参考リンク1,参考リンク2)。
quicksort' [] = []
quicksort' [x] = [x]
quicksort' (x:xs) = (forceList losort) `par`
(forceList hisort) `par`
losort ++ (x:hisort)
where
losort = quicksort' [y|y <- xs, y < x]
hisort = quicksort' [y|y <- xs, y >= x]
forceList :: [a] -> ()
forceList [] = ()
forceList (x:xs) = x `pseq` forceList xs並列化したプログラムの実行方法
それでは並列化版クイックソートを試してみましょう。quicksort'関数に以下の定義を加え,ParallelTest.hsという名前でParallel.hsと同じディレクトリに保存します。
import Parallel main = print $ quicksort' [0..10000]
次に,Parallel.hsやParallelTest.hsと同じディレクトリに移動し,マルチスレッド(multi-thread)版の実行時システム(ランタイム・システム)をリンクするよう,--makeオプションと-threadedオプションを付けてコンパイルします。threadedオプションを付けなければparはOSのネイティブ・スレッドで動作しないため,処理が並列化されない点に注意してください(参考リンク)。
また,必要に応じて最適化オプションを付けてください。複数の最適化フラグをパッケージ化している-O*オプションを使うのが便利でしょう。-O*の*は最適化のレベルです。*を付けないと-O1と同じ,-O0だと最適化を何も行わないという意味になります(参考リンク)。このあたりはgccなどのコンパイラと同じですね。ただ,最適化オプションを付けると,それだけコンパイルに時間がかかるので気をつけてください。現在のGHC 6.6.xでは,-O*オプションを付けると自動的に-fvia-Cという「一度Cのコードを生成し,gccを使ってそれをコンパイルする」というオプションも有効にしてしまうため,コンパイルに要する時間が倍増してしまいます(参考リンク1,参考リンク2)。なお,GHCの開発版ではすでに-Oオプションと-fvia-Cオプションは分けられています(参考リンク)。
なので,まずは最適化オプションを付けずに正しく動くかどうかを確かめて,次に最適化オプションを付けてプログラムを最適化するとよいでしょう(参考リンク)。なお,並列プログラミングでは,実行時のプログラムの性能(performance,パフォーマンス)の分析が欠かせないので,本文中のプログラムはすべて-Oオプションを付けてコンパイルしています。
$ ghc -threaded --make ParallelTest.hs -cpp -O [1 of 2] Compiling Parallel ( Parallel.hs, Parallel.o ) [2 of 2] Compiling Main ( ParallelTest.hs, ParallelTest.o ) Linking ParallelTest.exe ...
それでは実行してみましょう。-threadedオプションを付けてコンパイルしていれば,実行時システムに-N<x>というオプションが組み込まれているはずです。-N<x>オプションは,プログラムを実行する際にxで指定したのと同じ数のスレッドを同時に動作させます。特に理由がなければ,<x>にはプロセサと同じ数を指定してください。例えば,デュアルコア(dual-core)のコンピュータを使う場合には-N2です(参考リンク)。
$ ParallelTest +RTS -N2 [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29 ~ 略 ~ ,9998,9999,10000]
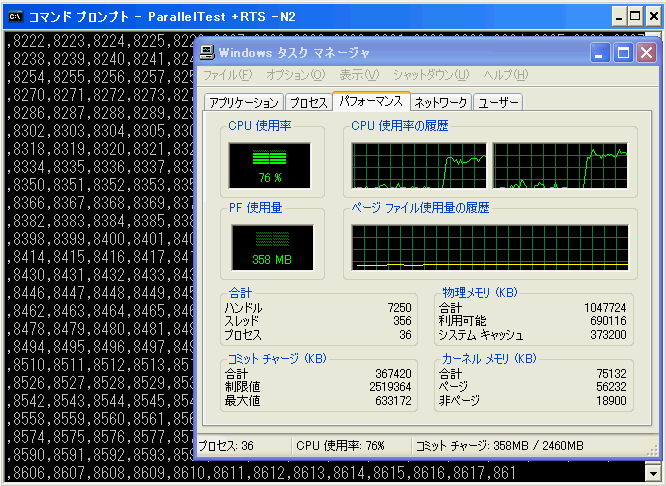
Windowsのタスクマネージャでは,ParallelTestが並列に実行されていることを確認できます。
また,-s<file>オプションを使って,実行に関する統計的な情報を出力することもできます。このオプションは,基本的にはガーベジ・コレクション(GC)の様子を知るためのものですが,複数スレッド対応版の実行時システムを使っている場合には,プログラムがどのように仕事を片付けていっているかを知ることができます(GHCのGCはまだ並列化されていないためです。参考リンク)。このオプションにより,プログラムがどのように実行されているかを把握するための統計的な情報が得られます。
-s<file>の<file>の部分には,情報を出力するファイル名を指定します。ファイル名を省略した場合には,<実行コマンド名>.statsというファイルが生成されます。また,stderrを指定することで,ファイルではなく標準エラーに情報を出力することもできます(参考リンク)。
$ ParallelTest +RTS -N2 -sstderr
ParallelTest +RTS -N2 -sstderr
[0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29
~ 略 ~
,9998,9999,10000]
6,510,557,176 bytes allocated in the heap
2,095,847,184 bytes copied during GC (scavenged)
93,168,176 bytes copied during GC (not scavenged)
934,244 bytes maximum residency (842 sample(s))
6268 collections in generation 0 ( 3.89s)
842 collections in generation 1 ( 1.55s)
4 Mb total memory in use
Task 0 (worker) : MUT time: 0.00s ( 0.00s elapsed)
GC time: 0.00s ( 0.00s elapsed)
Task 1 (worker) : MUT time: 2.58s ( 4.67s elapsed)
GC time: 0.66s ( 0.66s elapsed)
Task 2 (worker) : MUT time: 4.75s ( 4.78s elapsed)
GC time: 4.20s ( 4.22s elapsed)
Task 3 (worker) : MUT time: 2.02s ( 4.78s elapsed)
GC time: 0.58s ( 0.58s elapsed)
Task 4 (worker) : MUT time: 0.00s ( 4.78s elapsed)
GC time: 0.00s ( 0.00s elapsed)
INIT time 0.02s ( 0.00s elapsed)
MUT time 9.45s ( 4.78s elapsed)
GC time 5.44s ( 5.45s elapsed)
EXIT time 0.00s ( 0.00s elapsed)
Total time 14.91s ( 10.23s elapsed)
%GC time 36.5% (53.3% elapsed)
Alloc rate 687,583,596 bytes per MUT second
Productivity 63.4% of total user, 92.4% of total elapsedなお,実行時の状況によって,表示されるTask数に多少の増減が出るようです。



















































