各種サーバーに格納されている情報を整理し,情報を引き出せるようにするエンタープライズ・サーチ製品。文書の量やユーザー数によってシステムの設計方法は変わってくる。ポイントになるのは,サーチ・エンジンを構成する三つの基本機能の配置の仕方だ。
エンタープライズ・サーチのシステムは,インターネットで使われている検索エンジンと構造的には同じである。具体的には,(1)ネットワークを介して検索対象のシステムから文書を収集する「クローラ」,(2)収集した文書からテキストを抽出して索引を作成する「インデクサ」,(3)ユーザーからの問い合わせに従って索引を調べ,検索結果を返す「サーチャー」という三つのプログラム・モジュールが連携して動作する(図3)。エンタープライズ・サーチ製品は,これに簡易なポータル・サーバーの機能や,アクセス制御を実現するためのディレクトリ・サービス連携機能を持たせてある。
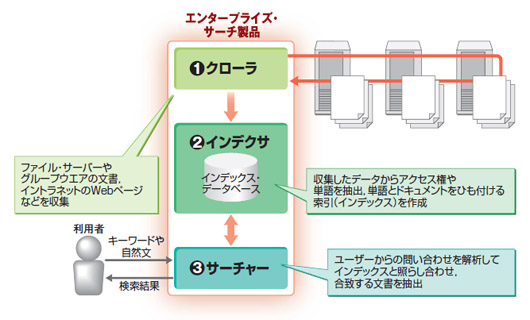 |
| 図3●エンタープライズ・サーチ製品の基本構造 クローラが文書を収集,インデクサが文書の索引を作成する。サーチャーはユーザーのアクセス権限に応じた検索結果を返す。 |
検索システムの動作はこうだ。クローラは,あらかじめユーザー企業のシステム管理者が設定したスケジュールに基づいて各サーバーにアクセス。この際,サーバーには管理者権限でアクセスするため,サーバー上のすべての文書を収集できるようになっている。
対象がイントラネットのWebサーバーならHTTPでアクセスしてページを取得。グループウエアなら専用のAPIを介すか,Webブラウザ向けのページにアクセスしてデータを取得する。WordやExcel,Acrobatといったオフィス・ソフトのファイルのほか,各種グループウエア,Webページなど,よく使われているファイル形式の文書はたいてい収集可能で,製品間で大きな違いはない。
インデクサは,こうして収集した文書ファイルの内容を解析し,索引を付ける。文章を単語に切り分ける技術を使って文書に含まれている単語を抽出。これを索引として文書ファイルと対応付ける。
サーチャーは,いわばエンタープライズ・サーチの「顔」に当たる部分である。エンドユーザーに検索窓のあるWebページを提供し,検索の要求を受け付ける。この「顔」のWebページは,エンタープライズ・サーチ製品が標準で備えているが,社内ポータルやグループウエアのページに組み込むこともできる。
検索窓にキーワードが入力されると,サーチャーはこれをインデクサに送信。インデクサが索引を検索した結果を返すと,サーチャーがエンドユーザー向けの検索結果ページを生成する。この際,結果の掲載順序(ランキング)は,あらかじめ設定したルールに基づいてサーチャーが自動判定する。
検索エンジンはどこに置く?
実際に導入する際には,製品によらず次の三つの点に注意しなければならない。ユーザーのログイン処理,多様なファイル形式への対応,そして検索エンジンの配置という基本設計である。
エンタープライズ・サーチでは,アクセス制御のためにエンドユーザーを検索エンジンにログインさせる必要がある。ただ,検索時にいちいちログインするのではユーザーには面倒。そこで,シングル・サインオン機能を使って検索エンジンへのログイン処理を隠ぺいする。どのエンタープライズ・サーチ製品もシングル・サインオンに対応している。導入に当たっては,検索対象システムとのシングル・サインオン設定が欠かせない。
ファイル形式については,WordやExcelといった一般的なファイル形式の文書は,エンタープライズ・サーチの標準機能だけで検索できる。ただし,グループウエアや文書管理製品を検索対象とする場合には,専用のゲートウエイ・ソフト(アダプタ)をオプションとして別途購入しなければならない製品が多い。また,ベンダーの独自形式などオプションにないファイル形式に対応させたい場合は,個別に作り込むことになる。費用の観点から「どうしても検索対象にしたい文書を選んで対応させる」(ネットマークス ストレージネットワーキング事業部グーグル・ビジネス・プロジェクトの久田直彦プロジェクトチーフ)のが得策だ。
数十万超の文書は分散処理で対処
システム設計についてはどうか。考慮すべきポイントは検索対象とする文書の数と応答性能,そしてアクセス制御である。
検索エンジンは基本的に,イントラネットのどこにあっても構わない。専用の検索サーバーを構築してもいいし,検索対象のサーバー上で稼働させてもいい。製品によっては三つのモジュールを分散させることができ,例えば社内ポータル・サーバーにサーチャーだけを組み込んで,ほかのマシンで稼働するインデクサに検索要求を送るようにすることも可能だ。
一番シンプルな構成は,クローラ,インデクサ,サーチャーを1台のサーバーで稼働させるもの。ただ耐障害性を考慮すると,冗長化を図り,負荷分散させるのが望ましい。
検索対象の文書の数が増えてくると,インデクサによるインデックスの作成時間が延び,運用面で問題になる。通常,インデックスの更新は夜間などにバッチ処理する。文書の数が増えればインデックス作成作業が始業時間になっても終わらなくなる可能性が出てくる。そこで考えたいのが3モジュールを別のサーバーで稼働させる方法である。アプライアンス製品を除くほとんどのエンタープライズ・サーチ製品は,役割ごとにサーバーを分けられる構造になっている(図4)。
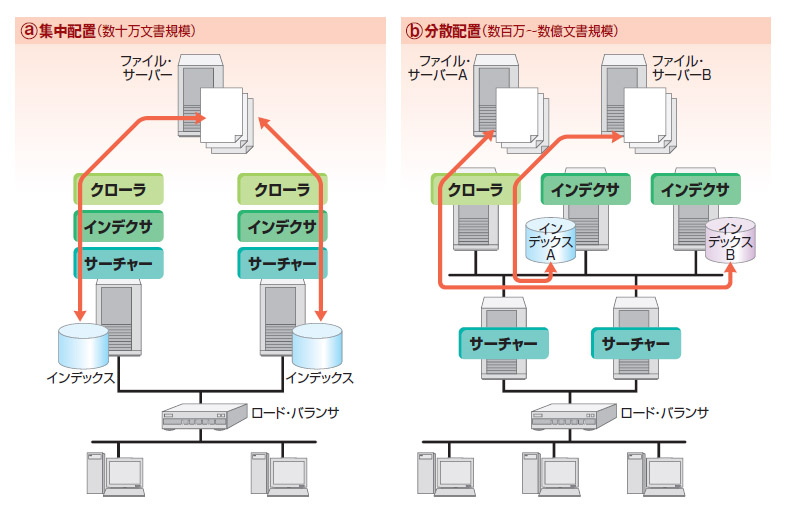 |
| 図4●エンタープライズ・サーチ導入時のシステム構成例 ボトルネックになるモジュールを分散配置することで,ドキュメント数の増量や検索速度の向上を図る。 [画像のクリックで拡大表示] |
具体的には,クローラ,インデクサ,サーチャーを別々のサーバーに分散させ,さらにインデックスは複数のサーバーに分割する。検索時にはサーチャーが複数のインデクサに問い合わせた結果をマージしてユーザーに返す。こうしておけば文書数が増えた場合でも,インデックスを追加していくことで理論上無制限に拡張できる。例えば自社製品を社内導入している日本IBMの場合,「2000万文書を4台のサーバーで運用している」という。
同時に検索要求を出すユーザー数が増えてきた場合は,検索の応答処理にかかる負荷が高まる。この場合は,全く同じインデックスを持つインデクサを複数設置して,負荷分散させる。



















































