これまでの記事をお読みいただいたことで,まったく経験がなかった人でも,アセンブラのプログラムを読んだり書いたりする自信が持てたことと思います。最終回は,代表的なアルゴリズムとデータ構造の記述方法を紹介しましょう。
矢沢 久雄/グレープシティ
なんでキャット(以下,キャット):プログラムを作るには,アルゴリズムやデータ構造を考える必要があることを知ってるかニャ?
Tデスク:もちろんです。
キャット:それじゃあ,どんなアルゴリズムを知ってるかニャ?
Tデスク:有名なのは,ソートとサーチのアルゴリズムですね。ソートには,バブルソートやクイックソートなどがあり,サーチには,線形探索や二分探索などがあります。
キャット:じゃあ,データ構造は?
Tデスク:配列,スタック,リスト,キュー,ツリーといったところですね。
キャット:素晴らしい。それだけ知っていれば十分だニャ!
Tデスク:ところで,キャットさん。C言語とJavaでは,言語の種類が違っても同じアルゴリズムを記述できますよね。アセンブラでも同じですか?
キャット:確かに,アルゴリズムとプログラミング言語の種類は,基本的には無関係。でも高水準言語とアセンブラでは,アルゴリズムやデータ構造の表現方法に違いがあるんだニャ。
Tデスク:これまで,いろいろと教わってきたことですね。
キャット:そうそう。アルゴリズムの流れを表すとき,高水準言語ではfor文やif文などを使うけど,それらはアセンブラにはない。アセンブラでは,比較命令とジャンプ命令を使うニャ。
Tデスク:はい,はい。
キャット:データ構造の表現方法も違う。例えば,リスト,キュー,ツリーといったデータ構造は高水準言語では容易に記述できるが,それらをアセンブラで記述するのは困難なんだニャ。
Tデスク:様々なアルゴリズムやデータ構造を記述するのは,アセンブラより高水準言語の方が簡単なのですね(図1)。
 |
| 図1●高水準言語とアセンブラで異なるデータ構造やアルゴリズムの表現 |
キャット:その通り。だから,ふだんは高水準言語を使ってプログラムをバリバリ書いてほしい。アセンブラは,コンピュータの仕組みを知る手段として勉強するのでいいニャ。
Tデスク:キャ,キャットさん,これまでのご指導ありがとうございました(涙ぐんでカツオブシを差し出す)。
キャット:嬉しいニャ~。でも,このごろ食べ過ぎでちょっと太ったニャ!
for文やif文を使わない
高水準言語であるC言語とアセンブラで,アルゴリズムの記述方法を比べてみよう。ソートの代表として,「バブルソート」のアルゴリズムを取り上げる。ここでは,要素数5個の配列「a」に格納された値を昇順(小さい順)にソートする。バブルソートでは,配列の後ろから前に向かって隣り合った2つのデータを比較し,前にあるデータの方が大きい場合に,それらの2つのデータを交換する。先頭のデータが確定したら,末尾に戻って以下同様に繰り返せば,すべてのデータがソートされる。
 |
| 図2●C言語で記述したバブルソートのプログラム |
図2は,C言語でバブルソートのアルゴリズムを記述したものだ。繰り返しを表すfor文の中に別のfor文がある多重ループを使っている。外側のfor文のループカウンタ「n」(ループカウンタとは,繰り返し回数をカウントする変数のこと)は,前から何番目の位置を決定するかを意味している。内側のfor文のループカウンタ「p」は,どの位置で比較を行うかを意味している。
5行目以下のif文では,現在位置のデータa[p]より1つ前にあるデータa[p - 1]の方が大きい場合に,それらの値を交換している。変数「temp」には,メモリ上の2つのデータを交換するために,a[p]の値を一時的に逃がしている。
アセンブラでバブルソートのアルゴリズムを記述すると,図3のようになる。C言語のfor文とif文の機能が,アセンブラではCPAやJMI,JUMPといった比較命令およびジャンプ命令で実現されている点に注目してほしい。また,C言語のn,p,tempという変数の代わりに,アセンブラではGR0,GR1,GR4というレジスタを使っている。アセンブラでは変数を使うことも可能だが,値の更新を行うためには必ずレジスタを使うのだから,個数が足りるならば最初からレジスタを使った方がよいのだ。
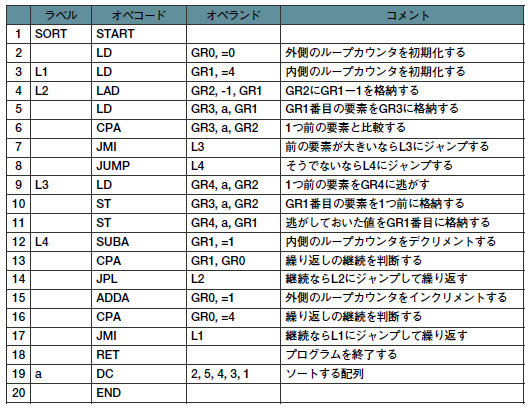 |
| 図3●アセンブラで記述したバブルソートのプログラム |



















































