領域効率を改善する方法
さて,遅延評価の領域効率を改善するにはどうすればよいでしょうか? 答えの一つは,sumのように関数が正格である場合には,式の評価を正格に切り替えてやることです。必要なところを適宜,正格評価にすれば,無駄な所要領域の要求を減らした実行速度の速いコードが手に入ります。実際,現在のGHCは,正格のプログラムを書いた場合でも,Cでループを使ったプログラムと比べてそん色のない実行速度を持つコードを生成できます(参考リンク)。
幸いData.Listモジュールにはfoldl'というfoldlの正格評価版が定義されています。これを使ってsumの正格評価版を定義し,上のプログラムを書き換えることにしましょう(参考リンク)。
-- | A strict version of 'foldl'. foldl' :: (a -> b -> a) -> a -> [b] -> a foldl' f a [] = a foldl' f a (x:xs) = let a' = f a x in a' `seq` foldl' f a' xs
import Data.List main = print $ sum' [0..1000000] sum' :: (Num a) => [a] -> a sum' = foldl' (+) 0
sum'では,式は以下のように簡約されることになります。
sum' [0..1000000] => foldl' (+) 0 [1..1000000] => foldl' (+) (0+1) [2..1000000] => foldl' (+) (1) [2..1000000] => foldl' (+) (1+2) [3..1000000] => foldl' (+) (3) [3..1000000] . . . => foldl' (+) 500000500000 [] => 500000500000
sumではO(n)だった領域計算量が,sum'ではO(1)にまで削減されているのがわかりますね。このため,この式は対話環境上でも問題なく評価できます。
*Main> sum' [0..1000000] 500000500000
手元の環境(Intel Core2 Duo 6600@2.40GHz)では,評価がすぐに終わってしまうため,表を作ってもあまり意味のあるものにはなりませんでした。縦軸に書いてあるバイト数から,評価に使われているメモリー量がとても少ないことが読み取れる程度です。
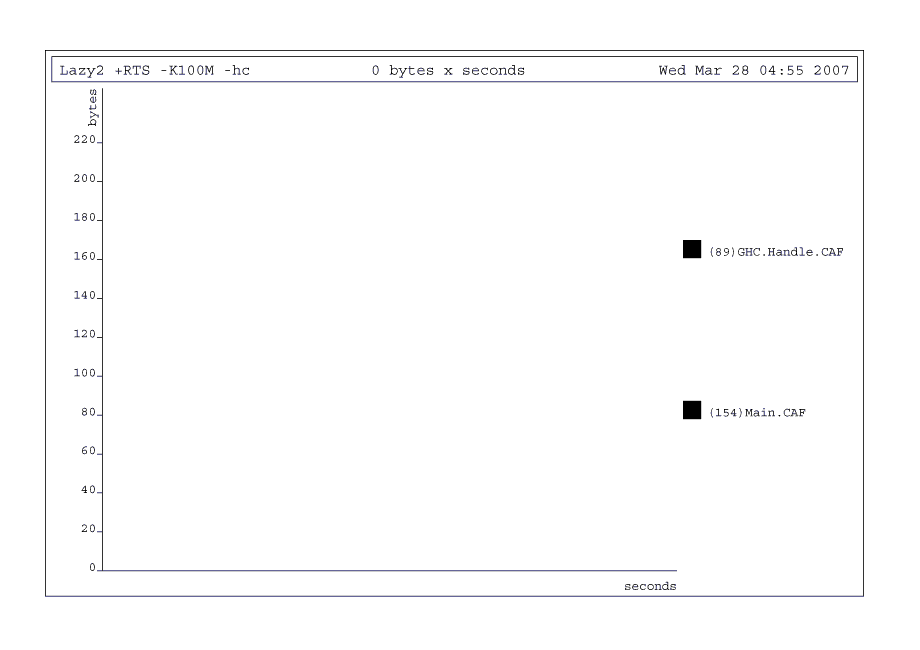
リストの終端の数を1桁増やしてmain = print $ sum' [0..10000000]にしても,対話環境で実行できる程度のメモリーしか消費しません。この場合は,次のような表が出力されます。

sumとは違って山型にはなっていないことから,メモリーの消費量が一定であることがわかります。mainが消費しているメモリー量自体も100バイト弱とわずかで済んでいます。
sumのケースでは,処理をfoldlに委譲していたため,簡単に正格評価版を定義できました。が,foldl'の定義を見ればわかる通り,関数の正格評価版を定義するには,普通は評価単位ごとに$!演算子やseq関数を適宜挟みこまなければなりません。$!演算子は1引数の関数しか扱えず,seqには二つの引数を評価して2番目の引数を返すという制約があります。これらの制約から,$!やseqを多用したコードは,重複が多いとても読みにくいコードになりがちだと想像できます(参考リンク)。どうすれば,この問題を解決できるでしょうか?
一つの解決方法は,使いやすい新たなインタフェースを導入することです。GHCは「バン!パターン(bang patterns,強制正格評価パターン)」という糖衣構文をサポートしています。次期標準であるHaskell'に入る可能性が高い拡張機能です。この機能を使うことで「あるパターンに対応する値を先に評価する」よう指示できます(参考リンク1,参考リンク2,参考リンク3)。
例えば,foldl'は,let式での変数a'の束縛にバン!パターンを使うことで,こう書き直せます。
foldl' f a [] = a foldl' f a (x:xs) = let !a' = f a x in foldl' f a' xs
ただ,バン!パターンを使うと,f !x = Trueのように「パターンを使っているのか,!演算子の定義のような別の役割を求めているのか」がわからないケースが出てきます。このようなあいまい性があることから,今のところ,この拡張機能は,-fbang-patternsオプションを付けなければ利用できないようになっています。
もう一つの方法は,評価する値をWHNFから先行評価される普通の正規形に変えてしまうことです。これは前回説明したように,DeepSeqやNFDataのような「使用するデータ型を再帰的に正規形にする型クラス」を定義してそのメソッドを使う,というやり方で実現できます。
また,関数ではなくデータ型に対して正格版を定義することもできます。関数に対して$!という正格適用演算子があるように,データ型にも「!」という記号で表される「正格性フラグ(strictness flag,あるいはstrictness annotation,正格性注釈)」と呼ばれる機能があります。データ構成子が取る型の前にこれを置くことで,データを構成する際にその引数が評価されるよう強制できます(参考リンク)。
正格性フラグを使ったデータ型の例としてLazyとStrictという型を定義してみましょう。処理系で結果が表示されるよう,Showクラスのインスタンスとしてshow関数を定義することにします。
data Lazy a = Lazy a
instance Show (Lazy a) where
show (Lazy _) = "Lazy"
data Strict a = Strict !a
instance Show (Strict a) where
show (Strict _) = "Strict"
f (Strict a) = aこれを使って評価を行った結果は以下の通りです。
*Main> Lazy undefined Lazy *Main> Strict undefined *** Exception: Prelude.undefined *Main> Strict [undefined] Strict *Main> f (Strict [undefined]) [*** Exception: Prelude.undefined *Main> take 10 $ f (Strict [1..]) [1,2,3,4,5,6,7,8,9,10]
Lazy型を使ったLazy undefinedでは引数の評価が遅延されるため,この段階では⊥は生じません。それに対しStrict型では引数の値が評価されてからデータ型が構成されるため,Strict undefinedを評価した時点で⊥になっていることがわかると思います。
また,前回説明したように,この評価はWHNFまでしか行われないため,Strict [undefined]やtake 10 $ f (Strict [1..])が⊥になることはありません。
再帰型の完全な正格評価版が欲しければ,foldl'と同様に再帰的に正格評価されるようデータ型を定義する必要があります。
data StrictList a = Nil | Cons !a !(StrictList a)
*Main> Strict (Cons undefined Nil) *** Exception: Prelude.undefined *Main> Strict (Cons 1 (Cons undefined Nil)) *** Exception: Prelude.undefined *Main> Strict (Cons 1 (Cons 12 undefined)) *** Exception: Prelude.undefined
最近,標準Haskellで定義されているデータ型に対して,正格評価版を定義したstrictというライブラリが公開されました。リストなどの再帰型の正格評価版はまだ定義されていないようですが,今後用意されるデータ型が増えていくなら興味深いライブラリになるでしょう。(参考リンク)。
ここまでは関数やデータ型の正格評価版を使うことで空間効率を改善する方法を見てきました。ただ,別のやり方のほうがよい場合もあります。関数の定義そのものを見直して計算量を変えてしまうことです。というのも,遅延評価の能力をうまく生かせていない場所が見つかったら,遅延評価を生かせるようその部分を書き換える必要があるからです。
例えば,sumに対しては正格以外の定義はありえませんが,関数によっては,本質的には正格でないのに正格になる場合があります。定義中で不用意にlengthなどの正格な関数を使用した場合などです(参考リンク)。また,正格でなくてもメモ化をうまく生かしていないために無駄な計算を行っているかもしれません。こうした場合,余計な計算が領域効率を損なってしまいます。
領域漏れの問題
遅延評価による所要領域の増大は,いつもsum [0..1000000]のようなわかりやすい形で起きるわけではありません。
- 使用しなくてもよい(使用を未然に防げる)はずのメモリーが使われている
- GCされるはずのメモリーがまだ保持されている
といった,一見しただけではわからない形で起こっていることもあります。このような隠れた領域非効率のことを「領域漏れ(space leak,スペース・リーク)」と呼びます。領域漏れが起こるかどうかは,そのプログラムが使われている文脈や処理系の実装に依存します(参考リンク)。領域漏れを確認するにはヒープ・プロファイラ(heap profiling tool)を使った測定が欠かせません。
幸いGHCでは,今回説明したようにランタイム・システムにプロファイラを組み込むことができます。プログラムの実行速度の低下に領域漏れがかかわっていると疑われる場合には,今回の記事やGHCのマニュアルのProfilingの部分などを参考に,メモリーの使用状況を測定してみてください。
|
正格性解析 遅延評価による非効率性への対処は,処理系の実装側ですでにある程度,行われています。例えば,GHCで使われているライブラリのいくつかの関数では,標準Haskellでの定義とは異なり,潜在的な領域漏れを防ぐ実装が採用されています。またGHCには,あるプログラムが正格であるかどうか分析するための「正格性解析(strictness analysis,正格性検査)」という機能が実装されています。GHCは,正格性解析の結果に基づいて,正格なプログラムを正格にコンパイルしようとします(参考リンク)。 GHCの正格性解析が完全なら,これまで述べてきたような問題に苦労することなく遅延評価の恩恵だけ受けることができるはずです。が,残念ながら他のデータフロー解析(data flow analysis)と同様,GHCの正格性解析も不完全です。抽象実行(abstract interpretation,抽象解釈)などを使った,あくまで近似的な(approximate)ものでしかありません。それでも,正格性解析がない場合に比べれば,プログラマによる最適化の手間を省いてくれるでしょう。 |
|
著者紹介 shelarcy 最近,GHCの開発版に,System.FilePathモジュールを定義したfilepathパッケージが加わるという変化がありました。すでにGHC 6.6のリポジトリ(repository)にも反映されているため,GHC6.6.1に収録されることになると思います(参考リンク)。 System.FilePathモジュールは,FilePath型に対する操作を行う関数を定義しているものです。 これまで何度か見てきたように,FilePathはSystem.IOモジュールなどパス名を必要とする様々な関数で利用される型ですが,今までパス名に対する操作を行う関数は表向き提供されていませんでした(Cabalのために,Cabalパッケージでは一応定義されてはいますが…。参考リンク)。そのため,パス名に対する操作を行う関数を自分で定義するか,公開されていない関数を使う必要があり,このことが長らくHaskellユーザーの不満になっていました。この状況がようやく解決されるようです。 System.FilePathモジュールはFilePath型の操作を行うためのものであって,既存のライブラリを修正するものではありません。このため,System.IOやディレクトリに対する操作を行うためのSystem.Directoryモジュール等でUnicode文字を含んだFilePathが扱えないといった課題はまだ残ります。それでもこの変化は大きな前進であるといえるでしょう(参考リンク1,参考リンク2) |















































