2006年6月19日,ピーク性能で1ペタFLOPS(1秒あたり1000兆回の浮動小数点演算)に達するコンピュータが登場したというニュースが世の中を駆け巡った。独立行政法人理化学研究所が開発した分子動力学シミュレーション専用コンピュータ「MDGRAPE-3」である(写真1)。1ペタFLOPSとは,密行列の並列処理性能を競うベンチマーク「Linpack」における高得点ランキング「TOP500」で第1位のIBM BlueGene/Lが持つ360テラFLOPSの3倍に相当する。
 |
| 写真1 MDGRAPE-3 |
 |
| 写真2 独立行政法人理化学研究所ゲノム科学総合研究センターシステム情報生物学研究グループ高速分子シミュレーション研究チームチームリーダーの泰地真弘人氏 |
MDGRAPE-3は,文部科学省の「タンパク3000プロジェクト」の一環として,製薬分野における分子動力学用途で開発された。狙いは,薬の物質とタンパク質との結合のしやすさをシミュレーションによって見積もり,新薬の開発期間の短縮に役立てること。理化学研究所横浜研究所ですでに稼働を始めており,2006年6月24日には一般公開に漕ぎ付けた。MDGRAPE-3の開発者は,同研究所のゲノム科学総合研究センター,システム情報生物学研究グループ,高速分子シミュレーション研究チームでチームリーダーを務める泰地真弘人氏である(写真2)。
汎用PCに専用アクセラレータを付ける
MDGRAPE-3は,米Intelのx86系CPU(Xeon)を搭載した101台のPCサーバーと,個々のPCサーバーの分子動力学計算能力を向上させる加速装置(アクセラレータ)とを組み合わせたシステムである。PCサーバー上ではLinuxと分子動力学専用のアプリケーションを動作させ,101台のPCサーバーを並列動作させる。アクセラレータ部分に専用LSI「MDGRAPE-3チップ」を搭載しており,同チップこそが1ペタFLOPSの数字的根拠となっている。
 |
| 写真3 1ボード上に12個のMDGRAPE-3チップを数珠つなぎに接続している |
101台のPCサーバーのうち64台は,インテルがMDGRAPE-3のために貸してくれたサーバー機であり,2コアのXeon 5100(Woodcrest)を2プロセッサ搭載する。残りの37台は理化学研究所が従来から持っていたサーバー機で,1コアのXeon(3.2GHz)を2プロセッサ搭載する。PCサーバーごとに2台ずつ,MDGRAPE-3チップを用いたアクセラレータを接続する。1台のアクセラレータには2枚のLSIボードが載る。1枚のLSIボードが備えるLSI(MDGRAPE-3チップ)は12個である。12個のMDGRAPE-3チップを数珠つなぎで接続している(写真3)。
MDGRAPE-3チップのLSIパッケージの主要要素は,20本のパイプラインと,6Mビットのメモリーである。個々のパイプラインは,原子と原子との間にかかる力を計算する。1対の力は,浮動小数点演算36回に相当する。1個のMDGRAPE-3チップには20本のパイプラインがあるので,MDGRAPE-3チップが1回に演算できる数は36×20で720となる。6Mビットのメモリーは,ちょうど3万個の原子のデータを持てる分量である。12個のMDGRAPE 3チップから成るLSIボード1枚で,36万個の原子のデータを持てる。
MDGRAPE-3チップの動作周波数は定格で250MHz。理化学研究所では,少しでも性能を稼ぐためにOC(オーバー・クロック)しているが,300MHzで動作したチップが3861個に対して,250MHzでないと動作しなかったチップは147個あった。このため,16個のMDGRAPE-3チップを故意に殺している。1個のMDGRAPE-3チップだけが250MHzでしか動作しない場合は,12個全部を250MHzの定格で動作させるよりも,1個のMDGRAPE-3チップを殺して残りの11個を300MHzで動作させた方が,ボード当たりの性能が良くなるからだ。なお,300MHzで動作させても,MDGRAPE-3チップ1個あたりの消費電力は17Wで済む。演算当たりの電力は極めて効率が良い。
分子動力学の並列処理に特化
浮動小数点演算用のコプロセッサがCPUと独立していた時代は,何サイクルもかけて1回の浮動小数点演算を行っていた。1980年代後半には浮動小数点演算ユニットがCPUパッケージに内包されるようになり,1サイクルで2回の演算が可能になった。だが,ここで浮動小数点演算性能の進化は頭打ちになった。サイクルあたりの演算数を増やすと,メモリーやレジスタの制約が出てしまう。こうした理由で,CPUは動作周波数を増やす方向で進化してきた。
現在のマルチコア化されたCPUでは多少改善されているものの,「性能を高めるために効果的なのはメモリーからの読み出し回数を減らすこと」と指摘するのは,MDGRAPE-3チップを開発した泰地真弘人氏である。CPUコアとメモリー間の通信やCPUコア同士の通信を減らすことで,並列処理の効率を高めることができる。これはちょうど,メモリー性能の化け物である現在のベクトル型スーパー・コンとは反対の考え方である。
MDGRAPE-3チップの特徴は,決まった式しか計算しない/できない専用LSIであるという点である。決まった式だけを計算するよう,パイプラインの構造をハードウエアで決め打ちしている(図1)。他の計算は一切できない。パイプラインには並列処理に特化したデータしか流さないため,メモリーのバンド幅をほとんど必要としない。MDGRAPE-3チップ内部のメモリーから20本のパイプラインへは,20本のパイプラインに与える共通のデータを1回だけ流せばよいという設計思想である。泰地氏は,これをブロードキャスト・メモリーと呼んでいる。
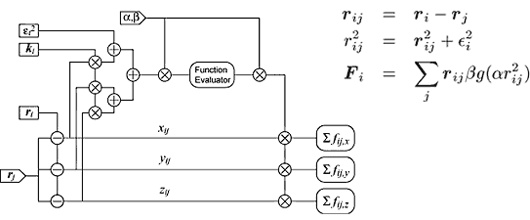 |
| 図1 原子同士の間にかかる力を計算するための専用のパイプライン |
分子動力学は,ブロードキャスト・メモリーに向く用途である(写真4,写真5)。原子間に働く力を計算する際には,力を及ぼす原子を1個決めて,その原子から力を及ぼされる原子を複数設定する。この時,力を及ぼされる原子の計算を個々のパイプラインで実施し,力を及ぼす原子のデータを全パイプライン共通のデータとして全パイプラインにブロードキャストする。パイプラインごとに異なるデータをメモリーから読む必要がなくなるため,メモリーのバンド幅は必要なくなる。
 |
| 写真4,5 薬がタンパク質に及ぼす力をシミュレーションする |
泰地氏はブロードキャスト・メモリーを分かりやすく説明するため,学校の授業の例を挙げた。「生徒にはあらかじめ異なる数値を渡しておきます。そこで先生は全生徒の前で言います。「手元にある数値に5をかけてください」と。これで,全生徒は全生徒ごとに異なる答えを計算します」。MDGRAPE-3チップは,SIMD(Single Instruction/Multiple Data)の考え方をベースに,与えるデータさえも共通化したものであると泰地氏は言う。
専用計算機への思いが結実
 |
|
| 写真6 1991年当時,大学生だった泰地氏が自作した専用計算機。FPGAを用いて再構成できた | |
 |
|
| 写真7 2001年に初めてLSIを起こして作ったMDGRAPE-2 |
実は,泰地氏にとってMDGRAPE-3チップは,大学時代の趣味から続いた専用計算機作りの延長にある。氏が最初に専用計算機を作ったのは1987年。PC-9801につないで使う,アクセラレータである。物理学を専攻していた氏が,磁石のシミュレーション用途に,秋葉原で部品を買い集めて作成した。1991年には,FPGAを用いた再構成可能な専用計算機を作っている(写真6)。
1989年には,MDGRAPE-3の元となる初代GRAPEが,在籍していた大学で完成する。宇宙に点在する星同士の力を計算して軌道を求めるための専用計算機である。泰地氏は,このプロジェクトを手伝った。GRAPEとは,Gravity Pipe(重力計算用のパイプライン)の略語だった。1996年には,Molecular Dynamics(分子動力学)用のGRAPEという意味で,MDGRAPEを作った。その後,理化学研究所に移り,2001年にMDGRAPE-2(写真7),そして2006年にMDGRAPE-3を完成させた。
大学のGRAPEプロジェクトでは,2008年末の完成を目標に,GRAPE-DRと呼ぶ新型機を完成させる。MDGRAPE-3の2倍に相当する2ペタFLOPSの性能を出す予定である。「準汎用を目指し,Linpackも動作させられるようにする」(泰地氏)。このため,GRAPE-DRが完成した暁には,スーパー・コンの高性能ランキング「TOP500」に名を連ねる可能性が高い。
MDGRAPE-3では動作させられないLinpackだが,Linpackが扱う密行列の計算は,分子動力学同様にメモリー・バンド幅を必要としない用途である。巨大な行列を分割して計算する,並列処理に向くベンチマークというわけだ。行列を大きくすればするほど,純粋にCPU処理能力が影響を及ぼすようになる。「計算量は1次元方向の伸びの3乗に比例するのに対して,メモリーとの転送量やCPU同士の通信量は,1次元方向の伸びの2乗に比例する。2乗と3乗の違いがあるため,行列が大きいほどプロセッサの能力をダイレクトに反映させられるようになる」(泰地氏)。メモリーのバンド幅が大きいベクトル型スーパー・コンは,Linpackではその優位性が出ないため不利であるという。



















































