|
|
見わたせば,世の中はアルゴリズムだらけです。私のようなプログラマは,日常生活でも「締め切り順に仕事をソートしてごらん」「仕事のスタックがたまっているからてんてこまい」など,いま置かれている状態をアルゴリズムやデータ構造になぞらえて会話することがよくあります。前回紹介した再帰処理と言えば,落語の演目の一つ,「頭山」です。自分の頭に生えた桜の木を引っこ抜いて,その跡にできた池に自分自身が身を投げる,という不思議な話ですが,これこそ再帰処理をよく言い表していると思います。
このように世の中には,ハッシュだってスタックだってソートだって,みんな身近にあるものです。でも,解決したい問題と,よく知られているアルゴリズムやデータ構造を結びつけて考えることはなかなか難しいようです。そこで,今回は問題にあったアルゴリズムの探し方をご紹介しましょう。例としてHTML データを解析する処理にアルゴリズムを適用する方法を考えてみます。
HTMLデータのタグは階層構造になっている
まずは問題に挙げたHTMLデータ(図1)の構造をよく見てみましょう。このとき,「このデータから答えを得るためのデータの流れ」「今までプログラムを作ったときに使った処理の流れ」を頭のどこかに置きながら見てください。ほとんどの場合で,この作業からアルゴリズムのヒントが見つけられます。
 |
| 図1●問題のHTMLデータ |
HTMLデータでは,文(テキスト)を「タグ」と呼ばれるもので囲んでいます。タグにはいくつか種類があり,タグを変えることで「特定の文を大きくする/太くする」といった効果や意味を与えられます。
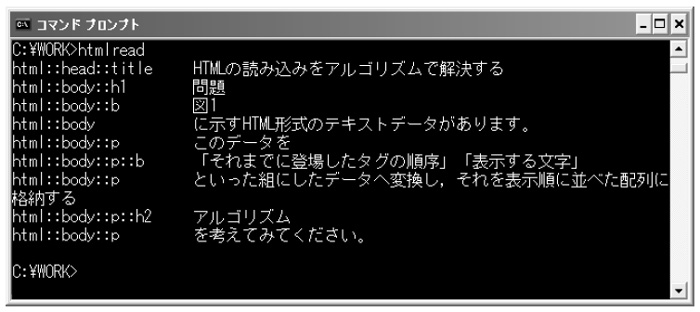 |
| 図2●問題に従ってタグと文字を表示したところ [画像のクリックで拡大表示] |
タグは「<」と「>」の間にタグ名を書くことで宣言します*1。このあとに文を書くことで,タグの効果が文字に加えられて表示されます。効果を終わらせるには「</タグ名>」と記述してタグを閉じます*2。例えば,
<b>アルゴリズム</b>
と書くと,「アルゴリズム」という文が太字(bold)で表示されます。タグには効果を制御するためのパラメータを属性として設定できますが,ここではとりあえず考えないことにしましょう。
HTMLデータではタグで囲んでいる文の中にまたタグを置くことができます。すなわち,タグを入れ子構造で定義できます。例えば「<p><b>foo </b></p>」となっていたら,「foo」にpタグで段落を付けて,bタグで太字表示することになります。「<p><b>foo</b>bar </p>」なら,barに対してbタグは有効にならずpタグだけが有効になります。HTMLデータにインデントを付けると,タグと文が階層状態になっているのがよくわかります。
階層構造のデータを処理するときには,ある階層の処理を終えたら一つ外側の階層へと処理を戻さなければなりません。HTMLデータであれば,タグが閉じられたときのために,それまで登場したタグをどこかに保存しておかなくてはいけません。アルゴリズムを考えるときは,ここがポイントになります。
HTMLデータを1文字ずつ読み込んで処理する
有名なアルゴリズムには,大体「よく使う場面」があります。ソートと言えばデータの並べ替えですが,ただそれだけではなく「別のアルゴリズムを使う前にデータを扱いやすくするために並べ替える」といった目的でもよく利用します。ハッシュなら,おおざっぱにデータを分類することで,検索処理を高速化できます。
そもそもアルゴリズムを考えるときは,「特定のアルゴリズムが得意としている部分がその問題の中にあるか」「よくある場面と同じように使えないか」と自問しながら問題を眺めてみるのが定石です。それでは,HTMLデータのような階層構造を持つデータを扱う場合には…?そうですね。スタックが利用できそうです。スタックは,多数のデータを管理するためのデータ構造で,データを次々に追加した後でデータを取り出すと,後に追加したものから順に取り出されるという特徴を持ちます。今回は,HTMLデータを読み込む処理を,スタックでどのように扱えばよいかを考えてみましょう。
最初に「HTMLデータを入力」~「配列として出力」という処理の流れをイメージしてみます。配列に出力するのは「タグ名」と「文」なので,これをHTMLデータから読み取ることが処理の中心になりそうです。
HTMLデータは基本的にテキスト・データですから,ポインタか配列で先頭から1文字ずつ読み込むというのが一般的な処理方法でしょう。例えば,データを指すポインタを一つずつずらしながら1文字ずつ取り出して調べていきます。タグを示す文字「<」「>」にぶつかったらタグ名として取り出します。
タグ名を取り出す処理をプログラムにするときは,以下の2種類の方法が考えられます。
・1文字ずつ取り出して「<」が来たら,以降の文字をバッファに入れておき,「>」が来たらそこで読み取りを止める。バッファにはタグ名が入るので,それを利用する
・「<」の位置+1をポインタ変数に保存し,タグ文字の長さを計るカウンタを開始する。1文字ずつ読み込んで「>」が出たら,そこまでの「文字列長」を得る。タグ名は「ポインタ」+「文字列長」で得られる
このように1文字ずつ照合していく以外に,C言語の文字列操作関数を利用して文字列単位で取り出す方法もあります。仕組みとしてはこんな感じです。 strchr関数に文字列と文字を渡すと,その文字列の中から指定した文字が最初に現れた位置(ポインタ)を返してくれます。そこでまず'<'を渡してその文字がある位置を得ます。次に,この位置を+1したところから'>'が現れる位置を探します。この間がタグ名となるので,あとは先に述べた方法と同じように処理します。同じような目的にstrtok関数も使えます。
タグを判別できたら,その間にあるデータが文になるはずです。文とタグをデータとして用意して,それを配列に出力すれば,今回の問題は解けたことになります。
では,文を出力するタイミングは,いつがいいのでしょうか。ある文に有効なタグが確定する場面として,まず「開始タグ+文+終了タグ」というパターンが見つかったときが挙げられます。今回は,HTMLデータのタグが完全に入れ子構造になっていて,各タグ名は入れ替わったり,途中のものが消えたりはしないとします*3。とすると,「開始タグ+文+開始タグ」「終了タグ+文+開始タグ」「終了タグ+文+終了タグ」といったパターンが見つかったときにも,文に対して有効なタグ名が決定することになります。すなわち,開始タグか終了タグかに関係なく,タグに出会ったときに,その直前までの文と,その文に有効なタグ名を配列へ書き出すようにすればよいわけです。文を配列へ書き出すときは,有効なタグ名を登場した順番に沿ってまとめる作業が必要です。
ここまでの考え方をスタックを利用して実現するには
(1)タグ名が現れるたびにスタックに積む
(2)タグの直前に文があるときは,その文をスタックから取り除いて配列に出力する
(3)その際,スタックの中にあるタグ名を全部連結したものも一緒に配列に出力する
(4)現れたタグが終了タグの場合は,スタックの一番上にあるタグが対応する開始タグになるので,それを取り除く
といった手順になります。
区切り文字も一緒にスタックに格納する
もっとも,このままでは少し面倒な点がいくつかあります。例えば,スタックの要素にタグなのか文なのかを区別するための目印を入れておかなくてはなりません。できればもう少しスマートに扱いたいものですね。
そこで,注目する場所を少し変えてみます。先ほどの方法では,「<」「>」「/」を目印にしてタグを取り出していました。それならいっそのこと,これらの文字も一つの要素としてスタックへ積んでみたらどうでしょうか?
例えば,「<p>アルゴリズム</p>」をスタックに積むなら図3のようにします。1文字ずつ読み出して,「<」「>」「/」という区切り文字,タグ名,文をスタックに積んでいきます*4。こうすると,スタックの特定の位置を調べるだけで,いろいろな事柄を判断できます。
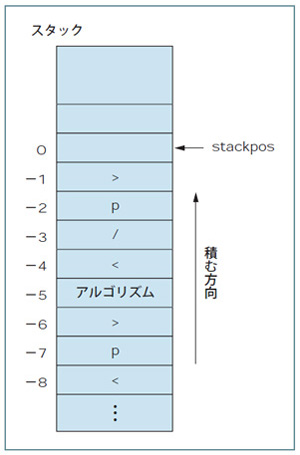 |
| 図3●「<p>アルゴリズム</p>」というHTMLをスタックに格納したところ |
例えば「>」まで読み取ったとき,それが開始タグの一部ならスタックの中身は図4(1)のようになっているはずです。そうでなければ開始タグではありません。また,終了タグなら図4 (2)のようになっています。開始タグの直前に文があるかどうかを調べるときは,図4(3)のように「>」の三つ下に「>」が入っていなければ,文が存在することを確認できます。こうした確認作業は区切り文字が出るときに実行すればいいでしょう。
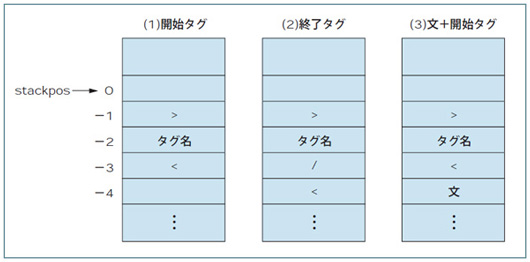 |
| 図4●タグの種類とスタックの様子。スタックの特定の位置の要素を調べることでタグの種類などを判別できる |



















































