これまで,Windows Vistaの文字の扱いに関する事柄を何度か取り上げてきた。同じキャラクタ・コードで,Windows XPのときと文字の形が変わったり,Unicodeでしか扱えない文字があったりするという話題だ。今回は,エンコーディングについて考えてみたい。
これまでの記事でも書いてきたが,文字処理とエンコーディングに関する問題は,何もWindows Vistaに始まったわけではない。Windows XPやWindows 2000など,既存のWindowsでも同様だ。例えば,「鴎」の旧字である「シナカモメ」は,Unicodeでしか扱えない文字だが,Windows XP以前のMS-IMEでも入力できる。石鹸の「鹸」の旧字もそうである。これらの文字を扱うには,アプリケーション・ソフトが,文字列をUnicodeで処理しなればならない。シフトJISに変換した瞬間に,文字情報が無くなってしまう。
このようなUnicode文字を正しく扱う方法は,アプリケーション・ソフトがUnicodeで文字を処理する以外にない。Windowsは既に,文字をUnicodeで処理しているし,.NET環境もUnicodeが基本だ。Visual C++ 2005のMFCプロジェクトでは,Unicodeビルトがデフォルトになった。アプリケーションを開発するに当たっては,今やUnicodeを選択すべきだろう。
ただ,アプリケーション内部ではUnicodeで処理するにしても,ファイルに保存したり,通信したりと,ほかのアプリケーション/システムとの間でデータをやり取りするときには,何らかのエンコーディングによってエンコードする必要がある。単にUnicodeといっても,そのエンコーディングにはいくつかの種類がある。一般には,「Unicodeは1文字当たり2バイトで表現する文字コード体系」と理解されているようだが,実際は少々違う。Unicodeでも1文字を1バイトで表したり,3バイト以上必要だったりする場合がある。
Unicodeは文字セットを定義しており,それらの文字には1文字当たり最大20ビットの番号が振られている。この番号を,決められたバイト列に変換する処理方法がエンコーディングだ。例えば「UTF-8」では,いわゆる半角英数字は1バイト,日本語の全角文字は3バイトで表現する。より正確には,Unicodeの文字番号が7ビットまでの文字は1バイト,8ビット以上11ビットまでは2バイト,12ビット以上16ビットまでは3バイト,17ビット以上21ビットまでは4バイトで表現する(図1)。
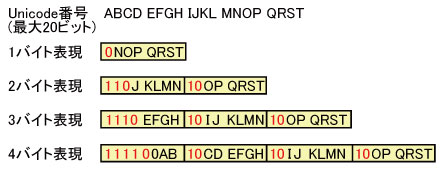 |
| 図1●UTF-8のエンコーディング方法。A~Tは20ビットの文字番号での各桁を意味する |
UTF-8は,通信を考慮して設計されたので,フレームが途切れてバイト列が途中からになった場合でも正しく情報を伝達できる。また,バイト列の後ろからでも,正しく文字を区切れる。あるバイトを見たときに,その上位2ビットが「10」でなければ,それはある1文字を表すバイト列の先頭だと分かるからだ。そしてその文字を構成するバイト数は,先頭のバイトの上位から「1」が連続するビット数で分かる(最上位ビットが 「0」だったら1バイト文字である)。
このような面を見ると,UTF-8を使えばすべてうまくいくような気がする。だがUTF-8では,冗長表現が可能だという欠点がある。図1のA~Mの各桁のビットが「0」の場合,文字番号は7ビットとなるので,1バイトで表現できる。だが,J,K,L,Mの各ビットが「0」の11ビットの文字番号として扱えば,2バイトでも表現できてしまうのである。例えば「A」という文字(Unicode番号は41H=01000001b)は,UTF-8では1バイトの「0100 0001(41H)」となるが,「1100 0001 1000 0001(C1H 81H)」と,2バイトでも表現可能だ。
同様に3バイトや4バイトでも同じ文字を表現できる。このように1つの文字に対して複数のキャラクタ・コードが割り当て可能だという点が,セキュリティ上のぜい弱性になる恐れがあると指摘されている(そのため,システムによっては冗長表現を許していないものもある)。
また,文字数とデータ長が比例していなければ,データベースのフィールドなど固定長でバッファを確保する場合,文字数では指定しにくい。日本語を表現する場合はデータ長が長くなりがちという点も,欠点になるかもしれない。
これに対して「UTF-16」では,番号が16ビットまでのUnicode文字はそのまま16ビット(2バイト)で,17ビット以上の文字をサロゲート・ペアを使って32ビット(4バイト)で表す。「UTF-32」では,すべての文字を1文字当たり32ビット(4バイト)で表現する。UTF-8と異なりUTF-16やUTF-32では,バイト列が途切れてしまったら,文字区切りがどこになるのかは分からなくなってしまう(UTF-16のサロゲート・ペアのみ識別可能)。また固定長バッファに関しては,UTF-16ではサロゲート・ペアの存在が問題になるかもしれない。UTF-32にすればデータ長は文字数に比例するが,1文字当たり,ほかのエンコーディングより多くのデータ領域が必要になる。
では,今までのデファクトだったシフトJISはどうだろうか。シフトJISを使うと,(英文混じりの)日本語を表現する場合,そのデータ長はUTF-8/16/32に比べて短くなる。コンピュータを取り巻く通信環境は高速になり,ストレージは大容量化してきたとはいえ,データ長は短いに越したことはない。シフトJISでもデータ長は文字数に比例しないが,必ず英数字は1バイト,日本語文字は2バイトになる。Unicodeエンコーディングよりも良さそうだが,シフトJISの問題は表現できない文字が存在することだ。裏を返せば,「シフトJISで表現できない文字を使わない」ようにすれば良いのだが,それでは進歩がない。日本語文字列を扱うのに,何か良いエンコーディングはないだろうか。



















































