Unicodeでは,複数の文字から1つの文字を合成する仕組みがある。例えば,ヨーロッパの言語で使われているアクセント付きのアルファベットを表現するのに使われる。日本語の濁点/半濁点付きのカタカナ/ひらがなにも,この仕組みがある。例えば,「ぱ」という文字は,「ぱ」(キャラクタ・コードはUTF16で3071)という2バイトの文字と,「は」(同306F)と文字合成用半濁点「゜」(同309A)を組み合わせた4バイト文字の,2種類が存在する。そのため,濁点/半濁点付きの文字を検索する場合,2バイトの単独文字と4バイトの合成文字の両方を検索する必要が出てくるなど,文字列処理が多少面倒になる可能性がある。今回はこの合成文字について,.NETでの処理を調べた。
最初に断っておくが,キーボードからは文字合成用の「゜」(キャラクタ・コードは309A)は入力できない。入力できるのは,キャラクタ・コードが309Cの「゜」である。そのため,以下で言及している問題は,通常は発生しないだろう。だが,.NETでの処理(仕様)が所々不自然に思える部分があるので,この話題を取り上げることにした。
本当に文字が合成されて表示されるのか?
まずは,文字合成用の半濁点を使った場合,それが本当に1文字として表示されるのかどうかを,メモ帳を使って確かめた。ちなみにメモ帳は,ご存じの方も多いと思うが,Windowsの標準コントロールであるエディット・コントロール(テキスト・ボックス)そのものである。メモ帳での振る舞いが,Windowsが標準で用意している振る舞いと考えてよいだろう。なお,秀丸エディタのように独自に文字列表示を実装しているアプリケーション・ソフトの場合は,それぞれの実装に依存するので,ここでは言及しない。
Windows Vistaのメモ帳では,キャラクタ・コード(エンコーディングはUTF16)が3071 309Cの文字列が「ぱ」という1文字として表示された(図1)。そして文字選択時に「は」と「゜」の間にカレットを移動することはできなかった。つまり,単独の「ぱ」と全く同じように表示された。画面では単独の「ぱ」と見分けが付かない。従って,独自のアプリケーション・ソフトでも,文字列表示にWindowsの標準コントロールを使っている限り,Windows Vistaでは合成文字を正しく表示できるはずだ。
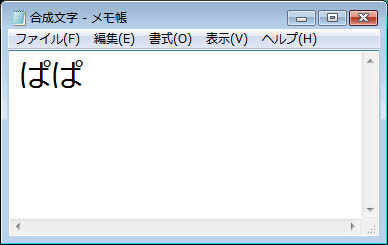 |
| 図1●Windows Vistaのメモ帳で単独文字の「ぱ」と合成文字の「ぱ」を表示した。どちらも同じ文字として表示される |
それに対してWindows XPのメモ帳では,合成文字は「は゜」のように2文字として表示される(図2)。そして「は」と「゜」の間にカレットを移動できるし,別々に文字を選択できる。フォントの問題かもしれないと考え,ライセンス上は許されていないが,Windows Vistaの「メイリオ」フォントをWindows XPにインストールして試したところ,同様に2文字として表示された。フォントではなく,Windows XPの文字列処理の問題のようだ。ちなみにWindows Vistaでは,「メイリオ」フォントだけでなく,MSゴシックなどほかのOpenTypeフォントでも合成文字が正しく表示できた(文字合成が可能なのはOpenTypeフォントだけである。TrueTypeフォントでは2文字で表示される)。
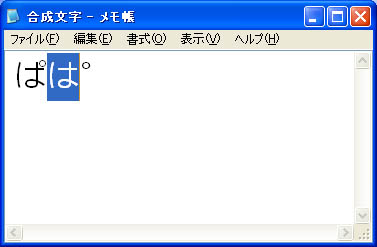 |
| 図2●Windows XPのメモ帳で単独文字の「ぱ」を合成文字の「ぱ」を表示した。合成文字の方は「は」と「゜」が別々の文字として表示され,別々に選択可能。フォントはメイリオ(ライセンス上,Windows XPでメイリオを利用するのは許されていない) |
これらのことから,Windows VistaのUniscribe(Unicode Script Processor)には濁点/半濁点の文字合成機能が実装されているが,Windows XPには実装されていないことが分かる。実際,Windows VistaのUniscribeは,Windows XPから仕様が変更されている(関連記事)。
検索でヒットするのか?
次に,濁点/半濁点付きの単独文字を検索して合成文字にヒットするのか,逆に合成文字を検索して単独文字にヒットするのかを,.NET対応のサンプル・プログラムを作って調べた。結論から言うと,どちらもヒットする。.NETのメソッドは単独文字と合成文字を同一視するよう実装されているようだ。
サンプル・プログラムでは,String.IndexOfメソッドを用いて,合成文字の「ぱ」と単独文字の「ぱ」を含む文字列から,合成文字あるいは単独文字の「ぱ」を検索した。合成文字の「ぱ」を検索したときは,合成文字の「ぱ」だけでなく単独文字の「ぱ」にもヒットする。また,単独文字の「ぱ」を検索したときも,単独文字の「ぱ」と合成文字の「ぱ」の両方にヒットする。
だが,サンプル・プログラムではヒットした文字列の反転処理も実装したのだが,その振る舞いに疑問が生じた。単独文字の「ぱ」を合成文字の「ぱ」に対して検索したときは,1文字反転した(図3)。それに対して合成文字の「ぱ」を単独文字の「ぱ」に対して検索したときは,2文字反転した(図4)。この現象について,もう少し調べてみた。
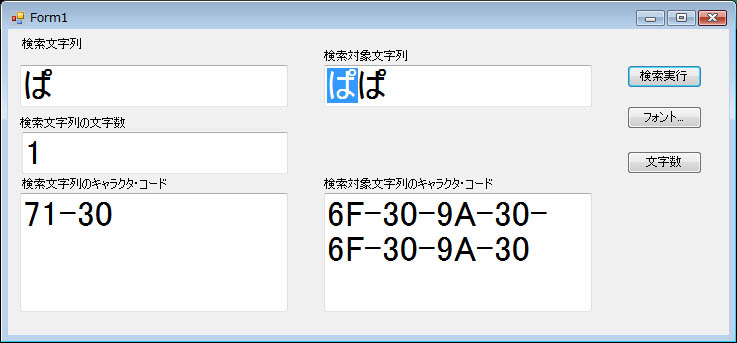 |
| 図3●単独文字の「ぱ」を合成文字の「ぱ」に対して検索したときは,1文字反転した。フォントはMS UIゴシック。キャラクタ・コードはUTF16のもの。リトル・エンディアンなので上位と下位が反転している |
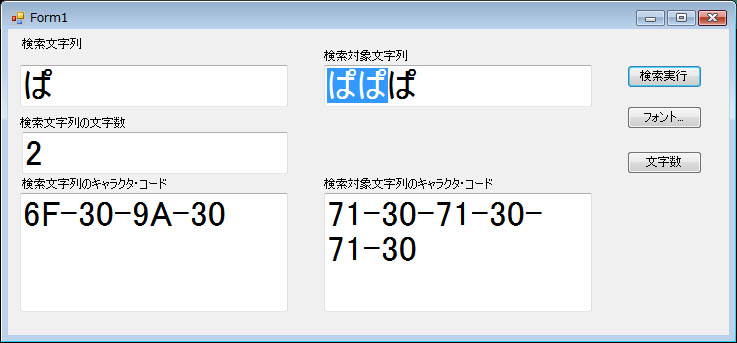 |
| 図4●合成文字の「ぱ」を単独文字の「ぱ」に対して検索したときは,2文字反転した。フォントはMS UIゴシック。キャラクタ・コードはUTF16のもの。リトル・エンディアンなので上位と下位が反転している |
「ぱ」の文字数は何文字か?
これらの振る舞いの原因は,文字数の扱いにあった。サンプル・プログラムの反転処理は,TextBox内の文字列について,見つかったインデックス(IndexOfメソッドの戻り値)から検索文字列の文字数(Lengthプロパティの値)分反転するというものだ。具体的には,TextBox.SelectionStartプロパティにIndexOfメソッドの戻り値を,TextBox.SelectionLengthプロパティに検索文字列のLengthプロパティの値を代入した。.NETのStringクラスは,単独文字の「ぱ」に対してはLengthプロパティに1,合成文字の「ぱ」に対しては2を返す。そのため,上記のような振る舞いになるわけだ。
.NETの文字列(Stringオブジェクト)の単位は,MSDNドキュメントによると,文字数である。つまり,いわゆる半角文字でも全角文字でも,1文字として扱う。だが合成文字は,画面上は1文字として表示されても,Lengthプロパティの値は2になる。さらに,1文字を4バイトで表現するときに使う拡張コード「サロゲート・ペア」を用いる文字(UTF16で4バイト)も,Lengthプロパティの値は2になる。
ここで,MSDNドキュメントをもう一度調べてみた。String.Lengthプロパティからは,確かに「このインスタンスの文字数を取得」できるとある。だが,解説欄には,「このインスタンス内のCharオブジェクトの数を返します。Unicode文字の数ではありません。これは,1つのUnicode文字が複数のCharで表されることがあるためです」とある。つまり,String.Lengthプロパティからは,文字数が得られるのではなく,UTF16エンコーディング時のワード数が得られるのだった。
実はこの仕様を決めるときに,マイクロソフト内でも長い間議論があったそうだ。.NETに閉じた世界に限定すれば,完全な文字単位で管理できそうだが,いろいろな場面を想定し,サロゲート・ペアの存在を意識していないアプリケーション・プログラムがクラッシュする可能性を最低にするために,現在の仕様のように合成文字やサロゲート・ペアについて「何もしない」ことが最善であると結論付けられたそうだ。ただ,Unicodeの合成文字やサロゲート・ペアは,今までは入力される機会がほとんど無かったから,意識しなくても問題が起こらなかっただけかもしれない。今後は意識してコーディングする必要がありそうだ。



















































