この記事は,日経ソフトウエア 1999年10月号に掲載したものです。それ以降の情報が盛り込まれていませんので,現在とは異なる場合があります。
文字コード規格の基礎を手早く理解したい場合などにお役立てください。
文字コードは間違いなく情報を交換するための「決まりごと」なので,正確を期すため厳密な仕様が規定されている。だが,その仕様そのものを実装するプログラムを作る場合を除けば,プログラマが仕様の詳細を隅々まで理解している必要はない。六法全書を読んでいなくても問題なく普段の生活ができるようなものだ。
ここでは,通常のプログラミングをするうえで必要と思われる範囲のことを,なるべく簡潔に説明したい。「半角カナ」のような呼び名は正確さを欠くものだが,多くの人に伝わりやすいので説明の中でも使っていく。説明を簡略化するため「正確な仕様を知りたいときは規格書そのものを必ず参照してほしい」と書きたいところだが,そのようなケースはめったにない。規格書を読み解くために時間を費やすよりは,だれかに聞いたり実際に試したりして疑問を解決する方が早い場合が多いだろう。
そろそろ具体的な説明に入ろう。最初にはっきりさせておく必要があるのは次の点だ。一般に「文字コード」と言う場合,
(1)文字の集合
(2)エンコード方法
という要素がある。この二つを区別して考えることが重要だ。もちろん大きな関連はあるのだが,ごちゃごちゃのままでは「わからなく」なる大きな要因となる。
代表的な文字集合の規格
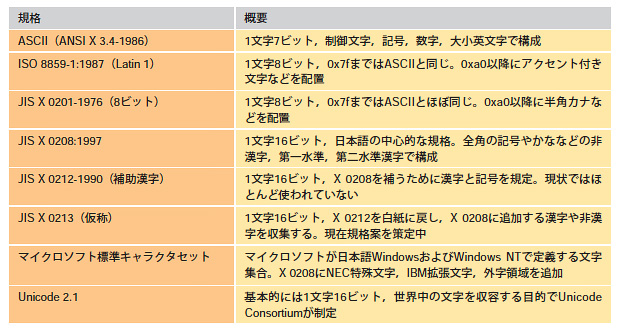
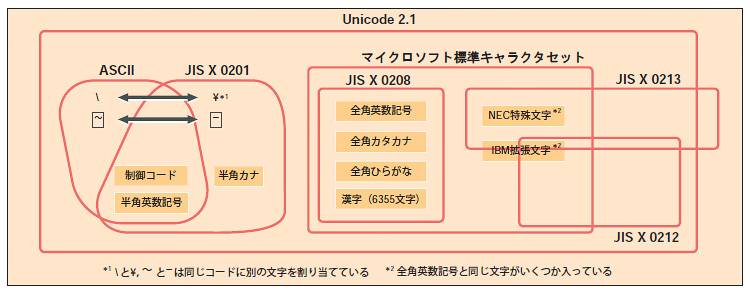
「文字の集合」とは,ある規格がどのような文字を規定しているかということだ。文字の集合を決めている主な規格を表1に示す。それぞれの規格が決めている文字集合には重なる部分がある。それを示したのが図1である。
|
|
| 表1●日本語システムで使う文字集合を定めている主な規格 [画像のクリックで拡大表示] |
|
|
| 図1●それぞれの規格が定めている文字集合の包含関係 [画像のクリックで拡大表示] |
ASCII
ASCII(アスキー)*1は,現状のコンピュータの世界で最も基本となる文字の集合(およびエンコード方法)である*2。数字,大小英文字,記号などを7ビットで表現する(1バイトのデータでは最上位ビットが0)。0x00-0x1f*3までには,CR(キャリッジ・リターン),LF(ライン・フィード),BS(バックスペース),HT(水平タブ)などの制御コードが入っている。
JIS X 0201
JIS X 0201は,ASCIIをベースにした国内の規格だ。0x5c(ASCIIがバックスラッシュ,JISが円記号)と0x7e(ASCIIがチルダ,JISがオーバーライン)に割り当てた文字が違う*4。これが日本語処理を行ううえで問題を引き起こす基になっている。また最上位ビットを1にした0xa0-0xdfにカタカナ(いわゆる半角カナ)を割り当てる方法を規定している。ただ,ASCIIが使っていない0x80-0xff(最上位ビットが1)の領域に文字を割り当てた規格はほかにもある。主にヨーロッパで使うアクセント付き文字や著作権マーク(丸シー)を配置したISO 8859-1(通称Latin 1)も欧米ではよく使われており,X 0201とは競合してしまう。
ASCIIおよびX 0201の文字は基本的に1バイトで表現できる。固定ピッチの日本語フォントでは,1バイト文字が漢字の半分の幅で表示されるので,「半角文字」と呼ぶことも多い。
JIS X 0208,X 0212,X 0213
JIS X 0208は,コンピュータが扱う日本語の中で最も基本となる文字集合である。英数字,記号,カタカナ,ひらがな,漢字(6355文字),いわゆる「全角文字」を定めている。現状のほとんどすべての日本語システムは,使っている文字コードにかかわらずX 0208で規定した文字を扱うことができる。
1990年には,X 0208に収容されていない漢字を使いたいという要求に基づき,非漢字266文字,漢字5801文字を規定したX 0212(補助漢字)が制定された。ところがシフトJISにはこれだけの文字数を収容する余地がなかったので,パソコンでは補助漢字が採用されず,結果的に現状ではパソコン以外でもほとんど利用されていない。
この問題点をふまえて,現在X 0212に代わる新しい規格の策定が進んでいる(仮称JIS X 0213)*5。99年内に制定される予定。シフトJISでのエンコーディングを考慮したものであるが,同時に収容する文字の選定も一からやり直している。したがって,X 0212とX 0213で共通している文字もあるが,片方だけにしか入っていない文字も多い。
マイクロソフト標準キャラクタセット
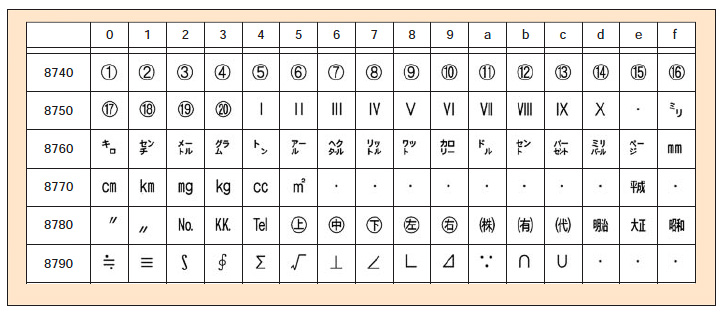
このような標準規格だけでなく,実際にコンピュータのフォントがどういう文字を収容しているか,ということも実際のシステムに大きな影響を与える。Windowsが備える文字集合を規定しているのが,「マイクロソフト標準キャラクタセット」である。基本的にはX 0208がベースだが,パソコンの歴史的経緯などからNEC特殊文字,IBM拡張文字という二つの文字集合を追加している(このほか外字領域も定義されている)*6。NEC特殊文字はもともとPC-98が備えていた記号類で,![]()
![]() といった丸数字や,I IIといったローマ数字などがある(図2)。IBM拡張文字(0xfa40-0xfc4b)は,もともとIBMメインフレームが備えていた漢字などである*7。Windows環境とそれ以外の環境で文字列を受け渡す場合,うまく変換できない可能性が高いのが,これらの文字だ。
といった丸数字や,I IIといったローマ数字などがある(図2)。IBM拡張文字(0xfa40-0xfc4b)は,もともとIBMメインフレームが備えていた漢字などである*7。Windows環境とそれ以外の環境で文字列を受け渡す場合,うまく変換できない可能性が高いのが,これらの文字だ。
|
|
| 図2●NEC特殊文字。シフトJISで0x8740-0x879cの位置に定義されている [画像のクリックで拡大表示] |
X 0212は一部のIBM拡張文字を含んでいるが全部ではない。一方X 0213はWindowsの実装を配慮して,NEC特殊文字をほぼそのまま収容している。IBM拡張文字も収容する方向にあるが,X 0208およびX 0213の漢字採用基準*8に当てはまらないものもあるため,すべてをX 0213が含んでいるわけではない。
なお,Windows 98に含まれるフォントのうち,MS明朝とMSゴシックはX 0212の書体データも(完全な形ではないようだが)備えている。IME 98を使ってUnicodeのコードを指定すると表示される。ただし既存のアプリケーションがその文字を受け取れるとは限らない。
Unicode
Unicode(ユニコード)は,世界各国の文字をすべて16ビット固定で表現する,という概念で作られた規格だ。ただ,各国が要望する文字を収容できないことがはっきりしたため,現在のバージョン2.1には32ビットで1文字を表現する仕組みが取り入れられており,「16ビット固定」という当初の概念は崩れつつある。ただ,現時点でそこに割り当てられた文字はまだない。
Unicodeには中国,日本,韓国(CJK)の漢字をまとめて収容する領域があり,そこにX 0208およびX 0212のすべての文字が含まれている。ただし漢字の並び順はJISと全く異なるし,日本にない漢字もあるのでコードが連続していない。また,NEC特殊文字とIBM拡張文字,1バイト文字のASCIIおよびX 0201も,半角カナを含めてすべて入っている。したがって,文字の集合としては上述の既存規格を包含している。
ただし現在策定中のX 0213には,Unicodeにはない漢字や記号も含まれる予定だ。将来その文字がUnicodeに追加される可能性はあるが,その場合でも時間差がある。また,フォント・データが作られるまでの時間差もある。したがって,今後Unicodeに含まれないX 0213の文字を使うような場合があったら要注意だ。



















































