コンピュータを使っていると,画面上でさまざまな文字を目にすると思うが,これはすべて文字コードという考え方に基づいて表示している。ただ,コンピュータの内部と通信用で違う種類の文字コードを使い分けるケースも多く,なにかと複雑。これが原因で文字化けもしょっちゅう起こる。そこで,文字コードの世界を探ってみることにしよう。なお,この記事は日経NETWORK 2002年2月号に掲載したものです。それ以降の情報が盛り込まれていませんので,現在とは異なる場合があります。文字コード規格の基礎を手早く理解したい場合などにお役立てください。
インターネット上でやりとりされるデータは,すべて0か1のビットの列で表す。画像だろうと音楽だろうと,ビット列であることに変わりはない。文字だって同じである。
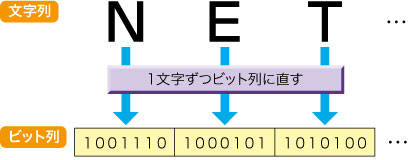
このため,ある文字をどのようなビット列に置き換えるのかということを,あらかじめ決めておく必要がある(図1)。具体的には,こうした対応関係を表にまとめておく。この対応表こそ,今回紹介する文字コードである。
|
|
| 図1●文字列をビット列に直す規則を定めたのが文字コード パソコンや通信はデータをディジタルで扱うので,文字は0か1のビットで表さなくてはならない。そこで,いくつかのビットを使って,どのビット列をどの文字に対応させるかを決めてある。 |
1文字を何ビットで表すか──。文字コードを作るには,最初にこれが問題となる。もし5ビットで表すなら,2の5乗で32通りの組み合わせのビット列が作れる。アルファベットのAからZまでの26字を収めるには,十分なビット数である。アルファベットに加え,0から9の数字と小文字のaからzも加えた62字となると,6ビット,つまり2の6乗の64に増やせばぎりぎり収まる。ひらがなやカタカナ,漢字を表そうとすると文字の数が大幅に増えるので,もっとビットの数を増やさないととても足りない。
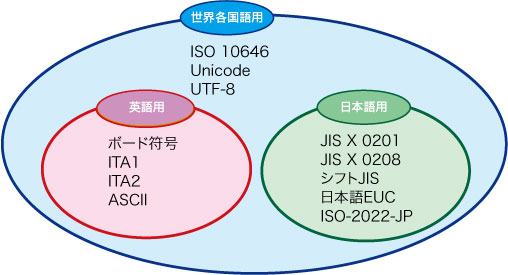
主な文字コードを,扱う文字の種類で分類すると,図2のようになる。どれか一つに統一すれば扱いやすい気もするが,とにかく文字コードにはたくさんの種類が乱立しているのが現状である。以下では,文字コードがなぜこれほどまでに複雑になっているのか,歴史をさかのぼりながら見ていくことにする。
|
|
| 図2●文字コードは言語ごとに作られる 英語用や日本語用に作られたもののほかに,世界各国のいろいろな複数の言語に対応した文字コードもある。 |