次に,プロジェクトの状況を可視化するアナライザの出力例をいくつか紹介しよう。
図3は,ある実プロジェクトで計測した,ソースコード規模(構成管理データの1つ)の推移である。4カ月弱の小規模なプロジェクトだが,お盆休みや国際会議参加で開発が停滞し,逆にアーキテクチャ変更や仕様追加で開発量が急増している様子が見て取れる。
|
|
| 図3●実際のプロジェクトで計測したソースコードの規模推移例 お盆や国際会議,テストなどの期間はソースコードの規模が増えておらず,開発作業が停滞していることが分かる。逆にアーキテクチャを変更したり新たに機能を追加したりすると,ソースコードの量が急増している |
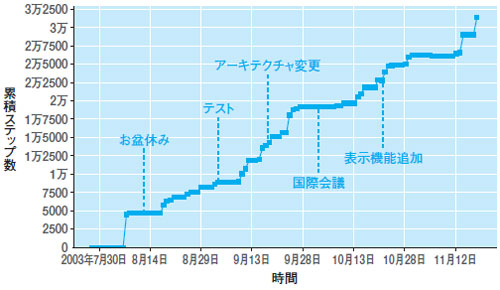
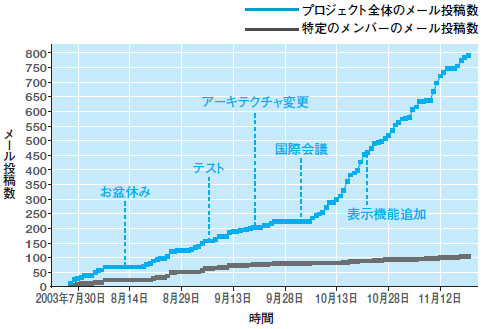
図4は,同じプロジェクトのメール投稿数の推移。青線がプロジェクト全体,黒線は特定の個人に着目したものだ。システム開発プロジェクトでは,プロジェクト終了後の反省会で,しばしばチームのコミュニケーション上の問題が指摘されることがある。メール投稿数は,こうしたコミュニケーション上のトラブルを推し量るバロメータの1つになる。
|
|
| 図4●図3と同じプロジェクトで計測したメール投稿数の推移例 2003年10月を境にメールの投稿数が急増しており,開発作業が佳境に入ったことが分かる |
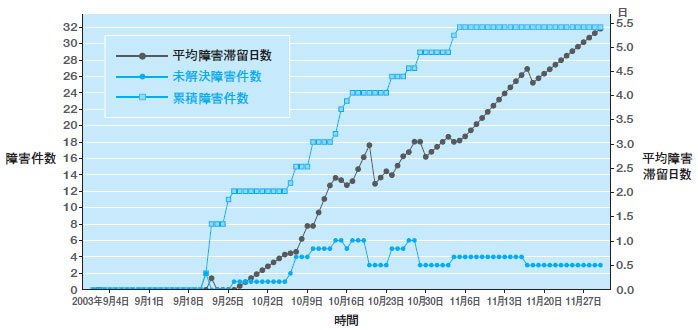
障害の発生件数,残存数,平均滞留時間を表示したのが図5だ。こうした障害データはどんなプロジェクトでも集計しているが,EPMを用いれば,人為的な介入の余地無く,生の正確なデータを収集・集計できる。
|
|
| 図5●バグの累積発生件数と未解決の累積バグ件数,解決されるまでの平均時間(平均滞留時間)の計測例 同様なデータはどのプロジェクトでも計測するが,EPMを利用することで,人手を介さず自動的に計測できる [画像のクリックで拡大表示] |
現状では,計測したデータをどう解釈するのかは,EPMを利用するプロジェクト・マネジャーやリーダーの経験に依存している。しかし今後は,「どんなトラブルが予想されるのか」といった,データの解釈方法まで提示していきたいと考えている。
計測内容や分析方法を拡充
ただし,現在のEPMはまだ初期版である。進行中のプロジェクトの開発プロセスと成果物に関するデータの自動収集とその分析・表示の有効性を実証したり,日本では難しい産学での実証データの共有を実現したりするための,基本的な機能を装備しているに過ぎない。
収集対象としている各種のデータも,非常に基本的なものである。例えば,現在のEPMではプログラムの規模としてソースコードしか計測できないが,Javaや.NETといったオブジェクト指向言語で開発する場合,ソースコード行数だけで規模を測るのは難しい。EPMの機能向上に関する要望は,プロジェクトの参加企業からも挙がっている。
そこで今後は,EPMをより有効なツールにするために,計測するデータの種類を増やしたり,新しいデータ分析の手法を実装したりしていく。
一例を挙げれば,2005年度中にも,奈良先端科学技術大学院大学の門田暁人助教授が提唱する「コードクローン計測技術」に基づいてソースコードに含まれるコードクローンの割合(コードクローン含有率=CRate)を計測するツールをプラグインとして開発する計画だ(図6)。コードクローンとは,プログラムのソースコード中に存在する類似コードのこと。コードのコピー&ペーストや,定型処理,意図的な繰り返しなどで発生する。
|
|
| 図6●ソースコード行数(SLOC)とコードクローン含有率(CRate)に着目した分析例 あるオープンソース・ソフト開発プロジェクトで,バージョンごとのSLOCとCRateを計測した例。ソースコードの行数だけを測っていては,進ちょくを正確に把握できない。CRateを計測することで,より正確な分析が期待できる。EASEプロジェクトでは,今後CRateの計測ツールも開発・提供する予定である |
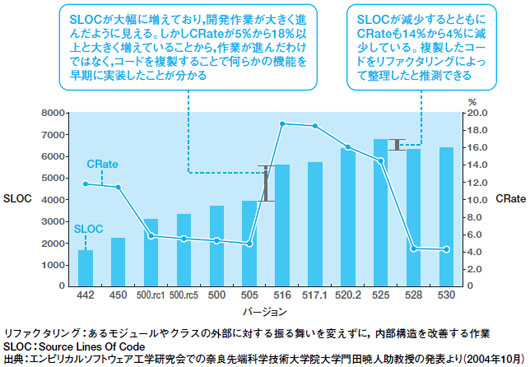
コードクローンに着目する理由は,ソースコード行数(SLOC)だけを追っていては気づきにくい問題を発見する,手掛かりになるためだ。例えば,障害原因になるコードがいたるところにコピーされていると,品質や保守性が極めて低いプログラムになる。ソースコード行数だけではなくCRateまで計測することで,こうした問題を発見する手掛かりが得られる。
このほかにも,UML(Unified Modeling Language)などで記述したドキュメントの構成管理データやユースケース・ポイントなど,要求定義や設計工程を支援するための指標を計測できるよう改良を進めていく予定である。プロジェクトの参加企業からは,「自動収集可能なデータだけでは不十分。工数や作業時間,コスト,見積もりデータなど,人手で入力するデータと組み合わせるべき」といった指摘も受けている。
もっとも,こうしたデータに関しては先に述べたSECが収集・分析している。このため,今後はEASEプロジェクトとSECが密接に連携していく予定だ。将来的には,EASEプロジェクトとSECが協力しながら,データ収集の範囲をケイパー・ジョーンズが示した9分野すべてに広げていく計画である。
以上,EASEプロジェクトの狙いと活動内容を紹介してきた。本記事がプロジェクト定量化への意識を高めるきっかけになれば幸いだ。
|



















































