Web検索エンジンの仕組み
「Yahoo! JAPAN」(ヤフー)など
インターネットを利用している人ならWebサイトの検索サービスは日常的に利用していることでしょう。最近の検索サービスは,企業や有名人の名前ならほとんどキーワード一発でほしい結果が上位に出ます。広告目的でキーワードを大量に埋め込んだようなページが上位に表示されることはほとんどありません。
このような,かゆいところに手が届くサービスをどうやって実現しているのか,Yahoo! JAPAN(図1)に尋ねてみました。Yahoo! JAPANの検索サービスは,2005年の半ばまでGoogleの検索結果と合わせて提供していましたが,現在は「Yahoo! Search Technology(YST)」という独自の検索技術のみで運用しています。
|
|
| 図1●Yahoo! JAPANのWeb検索サイト。たいていの企業名,商品名,有名人名は,単に検索するだけで公式サイトがトップにくる |
Webの全体像を効率よく取り込み,分類する
「YSTのシステムは大まかに三つの機能に分かれます(図2)。最初は世界中のWebページをYSTのシステムに取り込む『クローリング(crawling)』という機能です」(Yahoo! JAPAN,リスティング事業部 検索企画室の宮崎光世氏,以下同)。
|
|
| 図2●Yahoo! Search Technologyの処理の流れ |
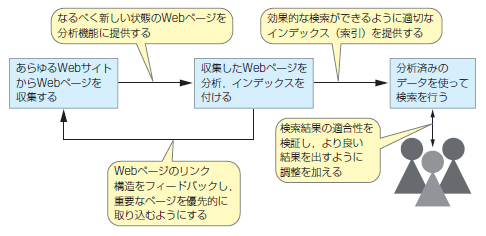
取り込むと簡単に言っても,Webページの数は膨大なうえ,更新の頻度や情報の質などがまちまちです。すべてのページに同じようにアクセスしていると非効率なことこの上ありません。そこで,限られた時間で質の良い検索ができるようにするための工夫をしています。例えば,クローリングを繰り返すうちに頻繁に更新されることがわかったページは短いサイクルでチェックし,ほとんど更新のないページはチェックの頻度を落とす,といったことをしているそうです。
ただ,更新の頻度が単に高いだけではダメです。重要性が高いと考えられるWebサイト,そういった重要なサイトからのリンクが多いサイト,検索結果として表示したときにユーザーがよくアクセスしてくれるサイトなどのほうがクローリングの際の優先度を高くします。
クローリングをしてデータを集めたら,今度はそれを分析してインデックス(索引)を付けます。クローリングによって集めるのはWebサイトに公開されているままの情報なので,それを検索しやすいように分類するわけです。「一番わかりやすい例は,そのWebページに使われている言語のインデックスでしょう。日本のユーザーは通常は日本語の情報を求めています。使用言語を調べてインデックスを付けておけば,ほかの言語のページを検索する必要がなくなり,検索の効率も向上します」。
もちろん,そのようにWebページの外形的なデータのインデックスだけではなく“日本に関する情報”のようにWebページの内容に即した「内容インデックス」も作ります。アダルト・サイトや,スパムを含むWebページのように通常の検索ではヒットさせたくないページもここで見つけ出します。
また,このときに,Webページ間のリンク構造も併せて分析します。分析結果はクローリングの処理にフィードバックされて,外部からのリンクが多いWebページなどの優先度を上げる仕組みになっています。
高精度の検索は人間の知識と経験があってこそ
クローリングしたデータを分析してインデックスを付け,リンク構造をフィードバックするというサイクルを絶えず繰り返すことで検索エンジンのコンテンツが作られていきます。そして,インデックスを付けたデータがいよいよ検索サービスに提供されることになります。
しかし,単純にキーワードを探すだけでは,ユーザーの意図するような検索結果を出せません。企業の情報システムと違って,Web検索は『このフィールドでこのデータを探す』というような論理的な探し方ができないからです。「リクエストを解析して,キーワードに重みを付けるなどの細かな調整が必要」になります。
この調整がまた大変な作業を伴います。「実際にユーザーが送ってきた検索リクエストと検索結果がどれくらいユーザーの意図に適合していたかを評価する作業を何度も繰り返しています。これは何らかのアルゴリズムで定式化できるようなものではないので,スタッフの手作業です。幸い,Yahoo! JAPANにはディレクトリの保守などで日本語サイトの情報に精通した経験豊かなスタッフが多くいるため,サイトの重要度などを高い精度で判断できていると思います」。
具体的には,この評価に基づいて,より適切な結果が表示されるように調整を加えていきます。そのシステムは「全体を把握している人は,YSTのスタッフの中でもおそらく一部の技術者だけ」というほど複雑で,検索技術のエキスパートが試行錯誤を繰り返しながらよりよいものに近づけているそうです。情報量の勝負に見えるWeb検索サービスも,一番重要な部分は人の知識と経験抜きには成り立たないのです。



















































