皆さん,こんにちは。この連載「よくわかるC言語」は,今回が2回目です。前回はC言語のソース・プログラムをアセンブラのコードとして出力して,Cのソースコード1行が複数のアセンブラのコードに対応していることを確認しました。なるほどC言語は“高級”な言語なのだと,感じていただけたのではないでしょうか。
さて,皆さんがプログラミングをしていて,“こう書くとこうなるけど,その理由はわからない”という方はいらっしゃいませんか。でもあまり心配する必要はありません。なぜそうなるのかの理由がわからないのは,たぶんプログラミングがわからないのではなくて,コンピュータの動作原理などの基礎知識が不足しているだけです。今回のテーマは「変数」ですが,この“コンピュータの仕組み”に重点を置いて説明していきます。ぜひ最後まで読んでみてください。ぼんやりしていた部分がはっきりすることでしょう。
変数はメモリーの一部に名前を付けたもの
では早速始めます。変数そのものを解説する前に,プログラムが扱う様々なデータを,コンピュータがどのように“記憶”するかを確認するところからお話ししましょう。
コンピュータがデータを記憶するには,メモリーかハードディスクを利用します。メモリーは,CPUが直接アクセスできる記憶装置です。半導体素子を利用して,データを電気的に記録します。動作は高速ですが,電源を切ると内容が失われてしまいます。情報処理の用語では「主記憶装置」と呼ばれています。
電源が切れたら消えてしまうと困るようなデータを記憶させるときには,皆さんご存じのハードディスクを利用します。フロッピ・ディスクやCD-Rなどを利用することもありますね。これらは「補助記憶装置」と呼ばれています。
ちょっと当たり前すぎて簡単に感じられたかもしれません。ここからが大事なところです。補助記憶装置に記憶されたデータをコンピュータが利用するときには,必要なものだけを主記憶装置(メモリー)に読み込んで利用します。やみくもに読み込むだけでは,何がどのデータだかわかりにくくなってしまいます。なのでプログラミング言語からは,メモリーの一部を,自分が付けた名前で扱えるようになっています。これが変数です。
char型の範囲が-128~127って?
となると,変数について正しく理解しないと,目的に合った正しいプログラムを作るのは難しいですよね。変数とはどのようなものかをもう少し詳しく見ていきましょう。
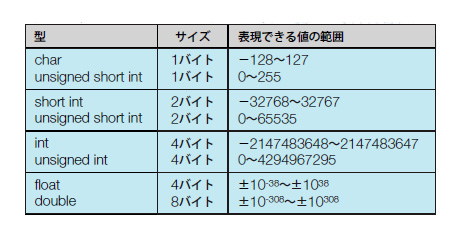
変数には「型」というものがあります。型は,その変数が(1)どのような形でデータを格納するかと,(2)一つの変数がメモリーをどれくらい必要とするかの二つを定めたものと考えてください。C言語の代表的な型と表現できる値の範囲は,表1のようになります。10年いや20年ぐらい前のことですが,筆者が初めてこのような表を目にしたとき,char型は文字を表すのに,どうして-128~127って書いてあるの? と思いました。誰でも最初は素人なのです。
| |
|
表1●C言語の主な変数の型と,表現できる値の範囲 |
前回,説明しましたように,コンピュータではプログラムもデータも,すべてオンとオフの2値の情報として,2進数のイメージで情報を扱います。メモリーの中に0と1がびっしり埋まっている様子を想像してください。2進数はご存じですよね。2で桁上がりする数のことです。例えば日頃使っている10進数の0,1,2,3,4を2進数で表すと0,1,10,11,100となります。この0と1の並びをどんどん,ながーく伸ばしていけば大きな値も扱えることに疑問の余地はありません*1。
コンピュータは,数値に限らず,文字も,音声も,画像も,2進数の0と1の並びで情報を扱います。コンピュータが生まれた国のアルファベットはもちろん,ひらがなも,漢字も,あらゆる文字も0と1の組み合わせで表現します。
複数のコンピュータで互いに情報をやりとりするためには,どの文字を,どの0と1の組み合わせで表現するかをあらかじめ決めておかなければいけません。この決まりを「文字コード」といいます。
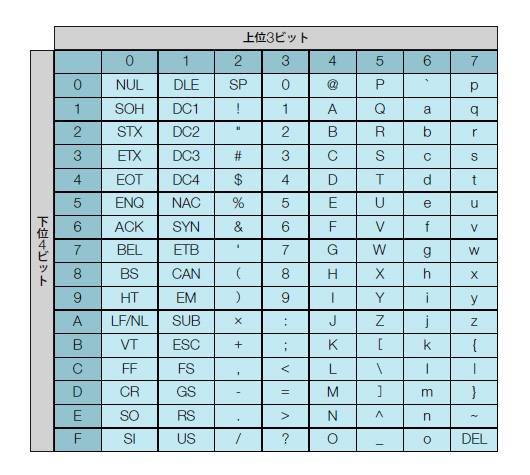
もっとも代表的な文字コードは,ANSI(米国規格協会)が1962年に制定したASCII(アスキー)コードです*2。ASCIIコードでは,例えば1000001という7ビットの並び(16進数では41*3)がAを表し,1100001(16進数では61)はaを意味します。「1」という“文字”は0110001(16進数では31)です。表2のように,A,Bなどの可読文字だけではなく,NULやSOHなどの制御文字*4を含め128のコードが制定されています。
| |
|
表2●ASCIIコード表。例えば「A」は上位3ビットが4,下位4ビットが1なので,コードは16進数で41とわかる |
128種のコードなら7ビット,つまり1バイトで1ビットの余裕を持って表現できますよね。なので,C言語では文字は1バイトのchar型で表します。でも,漢字を含む日本語の文字は種類が多いので1バイトでは表現できません。WindowsではシフトJISコード,UNIX系OSではEUCコードなどの2バイトのコードを使って漢字やかなを表現します。また,近年では,1バイトで表現可能な文字も,漢字と同様に2バイトを使って表すUnicode(ユニコード)も広く使用されています。
説明ばかりで少し退屈してきましたね。プログラムを作って,C言語で文字を変数に代入したとき,どのように扱われているかを見てみましょう。リスト1は,変数に文字や値を代入し,様々な形で標準出力(ディスプレイ)に出力してみるプログラムです。
| |
|
リスト1●変数に文字や値を代入し,様々な形で標準出力(ディスプレイ)に出力してみる |

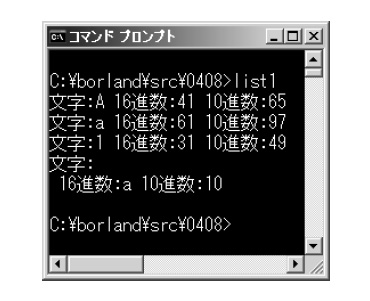
実行結果は図1です。この実行結果とリスト1のコードを照らし合わせて,char型変数の中身をイメージしていきましょう。まず,リスト1の(1)でchar型の変数を四つ宣言しています。c1,c2,c3,c4という名前(識別子)で指し示すことができる1バイトの箱を,メモリーに四つ作成したと考えてください。なお,c1,c2という変数名には特に意味はありません。C言語では英字・数字・アンダースコア(_)の組み合わせを識別子として使用できます。変数に名前を付けるときは,「数字で始めることはできない」「大文字・小文字は区別される」「C言語の予約語(例えば,intやreturn)を使うことはできない」――などの規則があることを覚えておいてください。
| |
|
図1●リスト1の実行結果 |
リスト1の(2)でc1に「A」という文字を代入しています。C言語では文字はシングルクォーテーション(')で区切ります。このc1の値を画面に表示するコードは,すぐ下にある(3)のprintf関数です。printf関数は書式付きで文字列を出力します。同じ値を文字として出力したり,10進数,16進数で表示することができます。
printf関数の第1引数には文字列を指定します。文字列は,複数の文字の並びのことで,文字とは違い,ダブルクォーテーション(")で区切ります。文字列中の%c,%x,%dなどを変換仕様といい,第2,3,4引数がこの変換仕様の部分に展開されていきます。文字として出力するには%cを,16進数として出力したい場合は%xを,10進数の整数として出力する場合は%dを指定します。第2,3,4引数はどれもc1です。図1の実行結果を見ると,
文字:A 16進数:41 10進数:65
と表示されていますね。文字としては「A」なのですが,メモリー内部では16進数で41,つまり2進数で01000001というビットの並びで表現されていることがわかります。
さて,printf文の第1引数で指定した文字列の中に,画面に表示されていない文字があります。「\n」です。\nは改行を意味する「エスケープ・シーケンス」です。エスケープ・シーケンスは,画面に表示できる文字だけで,制御文字を入力するための仕組みです。\nのように,「\」と「n」を続けて入力すると改行の制御文字を表すことができます。なのでリスト1の(3)の実行を終えたところで,1行改行しているわけです。なお,「\」という文字そのものを表したい場合は,「\\」と\を二つ続けて入力します。
(4)の\x61も,2桁の16進数で61を表すエスケープ・シーケンスです。(5)で文字として表示させると,aと表示されます。(6)と(7)は文字としての「1」の表示です。文字の1は,16進数で31,2進数で00110001というビットの並びです。
(8)と(9)は変数c4に代入した\nを文字として出力しています。図1を見ると,「\n」と表示される代わりに,行が変わっていますね。改行を意味する制御文字を表示しようとすると,画面では改行として扱われます。\nは16進数ではa,10進数では10と表示されています。2進数では00001010です。



















































