プログラミング言語にはRuby(Windows版)を使用します。Rubyデビューにもってこいの小さなサンプルです。最近ほどよく枯れてきたRubyの雰囲気をお楽しみください。なお,Windows用のRuby処理系はいくつかあります。例えば,ActiveScriptRubyなどをダウンロードしてセットアップしてください。以降はRubyがインストール済みという前提で話を進めていきます。
文字コードを変換してファイルに保存
サンプルは,元となるテキスト・ファイルからシフトJIS(以下SJIS),EUC,JIS,UTF-8に文字コードをコンバートしたテキスト・ファイルを生成するプログラムです。
実際,ソフト開発をしていると文字コードを制御する場面に結構遭遇しますよね。HTMLを作成する場合はもちろんのこと,RSSを作成する場合(UTF-8),LinuxなどとマルチOS環境で開発を行う場合(UTF-8ないしEUC),データベース・プログラミングでDB内データをCSV化したり反対にDBインポート用CSVを作成する場合(データベースの設定による)…など,多くの場面で文字コードの変換作業が発生します。皆さんはそういった場合,どうされていますか?
ほとんどのテキスト・エディタにはファイルの保存時に文字コード/改行コードを変換する機能が付いています(図1)。
| |
|
図1●秀丸エディタで,ファイル保存のときに文字コードを指定するところ [画像のクリックで拡大表示] |
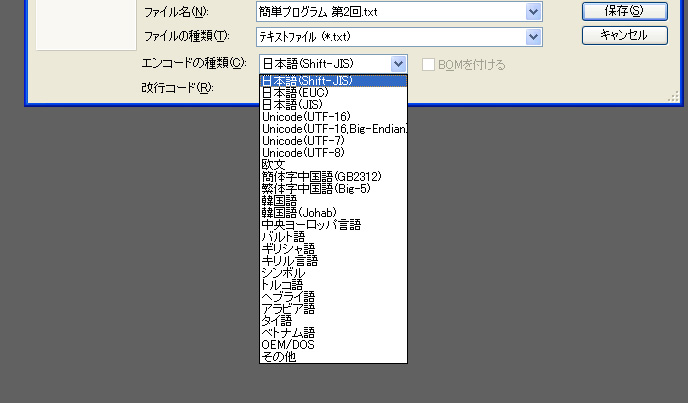
Windowsでテキスト・ファイルを新規作成すると,基本的にSJISのテキストになります。EUCで保存したい場合などは,こうしたエディタのコンバート機能を使用するのが一般的でしょう。EUCのテキストを読み込んでSJIS化する場合も同様の作業になります。
こういった作業は,ちょっとしたものなら手間になりませんが,データベースから引き出した5万行のEUC形式CSVデータを,Excelで読み込むためにエディタでSJIS変換する,これが全部で300ファイルある,といった状況に陥れば,やはりスクリプト言語でさくっと変換をしたくなるというものです。そんな私のところで現実にあった話から,今回のサンプルは生まれました。
小見出し Rubyを使う理由
Rubyはスクリプト言語としてはPerlやPythonと比べても後発ながら,最近ではLinux各ディストリビュータもパッケージにRubyを含むようになっていて,世界的にも広くその有用性が認められています。
普及度からみて,完成度や安定度に疑いがないのは当然として,私たちにとって,とても大切なポイントがあります。ご存知のようにRubyは日本人である,まつもとゆきひろ氏が開発しています。つまり最初から「日本語にはSJIS/JIS/EUC/UTF-8などの複数文字コードがある」という現状が把握されているというわけです。ともすれば「マルチバイトはUnicodeサポートしておけば大丈夫だろう」と考えてしまうかもしれないASCII文化圏製言語とは,スタートから違います。ASCII圏の開発者は日本語版OSで動作検証そのものができません。
日本語とコンピュータの関係は,すなわち文字コードとの戦いです。例えばPerlは日本語文字コードを操作する場合,jcode.plという外部モジュールを使用する方法が一般的でした。jcode.plは,その後jcode.pmに引き継がれ,Perl 5.80からはEncodeモジュールとしてPerl本体に標準添付となりました。しかし現在稼働中の多くのCGIプログラムでは,旧バージョンのPerlでも動作するメリットと,それまでの安定稼動実績からjcode.pl(jcode.pmでもない!)を使用し続けている例も少なくありません。
PHPでは早くからマルチバイト対応が考慮されていて,mb_stringモジュールを使えば日本語の文字コード変換なども実行できます。しかしmb_stringモジュールは標準的なPHP導入環境ではそのまま使用することはできず,設定ファイルの変更を必要とします。またWebプログラムとして使用し,さらにMySQLなどのデータベースと組み合わせると,ApacheやMySQLの設定ファイルも含めて相応の設定変更が必要になります。設定のバランスが崩れるとブラウザ表示で文字化けが発生し原因究明に時間を浪費することも多々あります。
どのスクリプト言語でもそれなりのマルチバイト文字対応を果たしているわけですが,Rubyには,(1)マルチバイト操作モジュールが標準添付,(2)同モジュールの使用に設定変更を必要としない,(3)足を引っぱるレガシーな資産がない,というアドバンテージがあるわけです。
元ファイルの文字コードに応じて出力ファイルを変える
では,サンプル・プログラムを解説していきましょう。サンプル(リスト1)はconvert.rbの名前で任意のディレクトリに保存してください。
リスト1●文字コード変換プログラム(convert.rb) 本稿では,サンプルをC:\fooに保存したものとして説明していきます。コマンドラインで
c:\ruby\bin\ruby c:\foo\convert.rb 処理したいファイルのフルパス
で実行します(例:c:\ruby\bin\ruby c:\foo\convert.rb c:\bar\hoge.txt)。
処理対象ファイルの入力は,コマンドプロンプトでc:\ruby\bin\ruby c:\foo\convert.rb[スペース]としておいて,エクスプローラから処理したいファイルをプロンプトにドロップすると簡単です。
Enterを押すと処理が始まります。サンプルはまずコマンドライン引数(ARGV[0])から処理すべきファイル名を取得します。対象ファイルの指定がなければ「変換元ファイルを指定してください」と表示し処理を中断します。
ファイルの指定がある場合は,該当ファイルを開いて内容を取り込みます。取り込み後にファイル内容についてチェックが入ります。次のいずれかのパターンであるときは処理は中断します。
・バイナリ・ファイル
・ASCIIファイル(半角英数のみ)
・エンコードが判別できない
「エンコード判別ができない」「バイナリ・ファイル」については,Rubyの解釈であり,普通のSJISテキスト・ファイルなのに変換されないといったことがあるかもしれません。ですが,これは言語側仕様なので回避できません。
エンコードが判別できた場合――ただし対象はSJIS/JIS/EUC/UTF-8の4種で,アラビア語や韓国語の判定は保証できません――現在のエンコードではないものを生成します。もし元のファイルがSJISであれば,SJISファイルを作っても同じものになってしまうので,SJIS分の処理はスキップするというわけです。元がSJISの場合はJIS/EUC/UTF-8の3種が生成されます(図2)。
| |
|
図2●元のファイルがSJISならば,EUC,JIS,UTF-8のファイルを生成する [画像のクリックで拡大表示] |
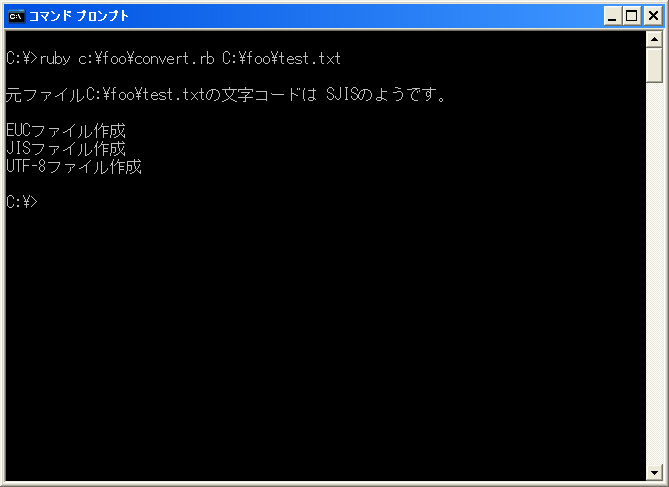
生成されたファイルは,元のファイルと同じディレクトリに保存されます。このときにファイル名には
元のファイル名_エンコード種別.元の拡張子
という命名規則で名前が付けられます(図3)。
| |
|
図3●生成されたファイルにはオリジナルのファイル名にエンコード種別が追記されている [画像のクリックで拡大表示] |
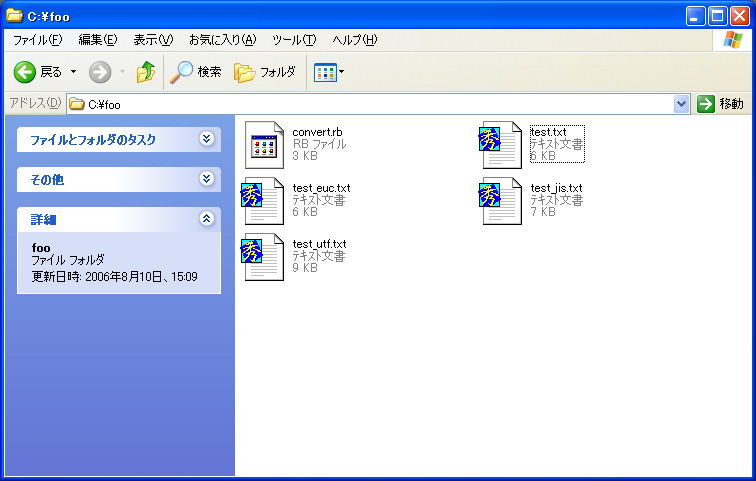
元になったファイルがtest.txtであれば,生成されたEUCファイルはtest_euc.txtになります。ファイル名変更は元のファイルのフルパスから,まずFile.basename(パス名)というRubyの関数ファイル名を取り出します。取り出したファイル名を「.(ピリオド)」で分割して,ピリオドの前をファイル名,ピリオドの後を拡張子と判定します。
ファイル名の部分に「 _エンコード名 」を付けて,最後に拡張子とマージするという手法を使っているので,ファイル名にピリオドを二つ以上含むような場合は,二つ目以降のピリオド以後の部分が取得されず誤動作します。
保存先をドロップされたファイル(処理対象ファイル)と同じにするために,File.dirname(パス名)というRuby関数で,指定されたファイルのあるパスを取得し,Dir.chdir(パス名)で作業ディレクトリを移動します。
これを怠ると,コマンドプロンプトのカレント・ディレクトリ(多くの場合,C:\Document and Settings\ユーザー名)が作業ディレクトリになって,そこにファイルが保存されます。保存先が固定ではっきりしていれば問題はありませんが,CDコマンドなどでディレクトリを移動していると,どこに保存されるのかも変わっていってしまうので保存先を元ソースと同じにあわせておくという処理は必要でしょう。
エンコード変換にはRubyのモジュールを利用
エンコード変換とエンコード判定にはkconvモジュールとnkfモジュールを使用します。同様の処理をするものにiconvがあります。少し対応エンコードが狭いところでuconvというのもあります。いずれもRuby本体に標準添付のライブラリで動作内容も似ています。他言語からRuby学習に入ると,なぜ似たようなモジュールが三つも四つもあるんだろうと感じます。
実はこれらのモジュールはLinux系OSにあるエンコード処理コマンドのkconv/nkf/iconvの操作感をRubyからも使えるようにという意図で実装されているものです。コード記述などが各コマンドに似せてあるわけで,肌になじむものを使ってくださいということなんでしょう。機能に若干の差はありますが,やれることはほぼ同等です。RubyはUNIX系OSベースで開発されているスクリプト環境であるということが,こういった部分から感じられます。もし自分の肌に合うものが別のモジュールであれば,変換と判定の部分は書き換えていただいてかまいません。
あとはコンバートしたエンコードでファイルを作成して保存すれば処理は完了です。
使い方と拡張のポイント
Windowsで使用する場合,デスクトップに
C:\ruby\bin\ruby c:\foo\convert.rb
というショートカットを作っておくと,このショートカットにファイルをドロップするだけで,変換ファイルが元ファイルと同じディレクトリに作成されます。この際,コマンドプロンプトはちらっと一瞬出るだけで,画面表示は確認できなくなりますが,動作が安定してきたら,こういった使い方のほうが便利です。
サンプルは,最初のトラップでコマンドライン引数を見て,ファイルの有無を判断します。本来は引数があった場合に,それがファイル名として妥当か,妥当であったとして実際に存在するファイルなのかといったルーチンを追加しておくべでしょう。
実際には何かのフォーマットから,特定のフォーマットで一つエンコードできれば用を果たせることがほとんどなので,サンプルのように4種類ものファイルを作る必要性はありません。常にEUCを吐き出せばいいような場合には,「-euc」のような引数を与えてやると,EUCしか吐き出さないといった拡張を実装するか,最初からEUCしか吐き出さないように簡略化してしまうのも手だと思います。
HTMLやRSS,XMLなど専用にする際には,文字コードをしている次のような箇所を確認し,文字コード指定部も置換して保存するなどの処理が入っていると便利です。
[元 EUC]
<meta http-equiv="Content-Type" content="text/html; charset=EUC-JP">
↓
[変換後 SJIS]
<meta http-equiv="Content-Type" content="text/html; charset=SHIFT_JIS">
XMLやHTMLでの文字コード表記は大文字小文字の混在はあっても単語としては固定なので,正規表現などでの置換は比較的楽な部類です。
データベース関係の仕事で使用する場合には,比較的長く使われている基幹システムに残りがちな半角カナの扱いなども考慮が必要かもしれません。日本語を取り巻く環境は全体的にUnicodeにシフトしはじめていますが,企業においてはPCは10年モノもたくさん残っているので,SJISの資産はこの先最低10年は残っていくと予想されます。機種依存文字や外字の問題も当分はクリアされないかもしれません。文字コードのコンバート系スクリプトは必要な人にとっては長く使える重宝なものになります。皆さんなりのお手元ツールに育ててあげてください。
|



















































