記念すべき第1回目にご紹介するサンプルは,クリップボードにあるテキスト・データからURLとメールアドレスを抽出するというHTML Applications (HTA)です。プログラミング言語にはVBScriptを使います。
| |
|
図1●サンプルの実行画面 [画像のクリックで拡大表示] |
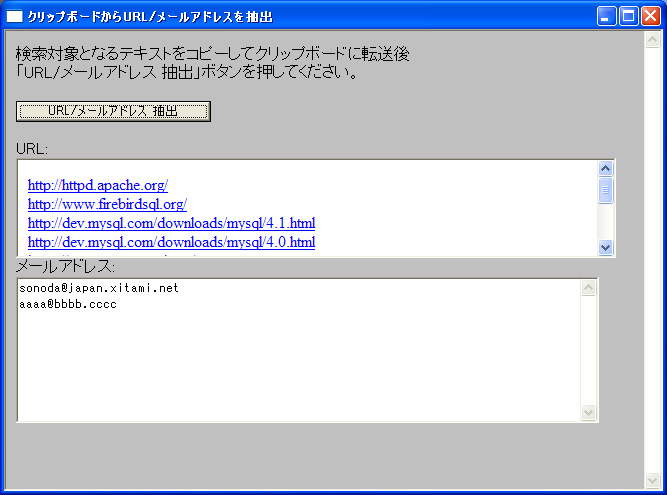
例えばメールの本文を全選択してCtrl+Cキーなどでクリップボードに送ります。データがクリップボードに入っている状態で,このHTAの「URL/メールアドレス抽出」ボタンを押すと,クリップボード内のテキスト・データからURLとメールアドレスを検索/抽出してリストアップします。
実はMicrosoft Excelでもセルを選択(もちろん範囲指定でも全選択でも)してコピーしたデータは,クリップボード内にテキスト・データとして入ります。2万行くらいのExcelデータからURLやメールアドレスだけ抽出するということもできるわけです。ExcelだけでなくAdobe Acrobatドキュメント(PDFファイルと言ったほうがわかりやすいですね)も全選択からコピーを行えばクリップボードに本文が入ります。
クリップボードを使えば
プログラムがシンプルになる
指定ファイルを開いて内容を読み込み,必要な単語にヒットさせて抽出するということもできますが,この場合には次のような問題があります。
・ファイル名を指定するインタフェースを作らなくてはならない
・バイナリ・ファイルだと,正しく読み込めない場合がある
さらに,コマンドラインからファイル名を直接指定するのは面倒なので,Windows APIなどを通してWindowsの「ファイルを開く」ダイアログを使おうとすると,コーディングが複雑になります。
そこで,こうした手間と面倒を,クリップボード経由でばさっと切り落としてしまえ,という考えが今回のユーザー・インタフェースにした理由です。
クリップボードのテキスト領域に取り込まれたデータは,たとえ元がExcelファイルであってもPDFファイルであっても,テキスト情報を持っています。もちろんクリップボード内のテキスト・データをエディタにペーストしてから保存してテキスト・ファイルを作成し,それを抽出アプリケーションに読み込ませるということもできますが,操作が2工程ほど増えてしまいます。であるなら,いっそクリップボードに入った段階で,そのデータを使ってしまえというわけです。
空のドキュメント・ファイルと
プログラム・ファイルの2本で構成
リスト1(child.html)とリスト2(clip2url.hta)が,サンプル・プログラムのソースコードです。先にchild.htmlについて説明しましょう。
リスト1●空のHTMLドキュメント(child.html)これはiframe内に表示するHTMLコンテンツで,実は空のHTMLドキュメントです。iframeには抽出処理後のURLを列挙します。列挙の際に内容をプログラム側で書き出すので,書き出すまでの空欄表示にのみ使います。0バイト・ファイルでもかまいませんが,将来的に何かの拡張を考えると,ここは空であってもHTMLで作っておくほうがいいでしょう。
メインのプログラムはclip2url.htaという名前で作成します(リスト2)。HTAは基本的にHTMLなので,インタフェースの作成も簡単にできます。ボタンやテキスト入力域はHTMLのFORMパーツ(エレメントといいます)を使用できます。
リスト2●メインのプログラム(clip2url.hta)作成後はclip2url.htaをエクスプローラからダブルクリックすると実行できます。抽出対象としたいドキュメントを開いて,対象としたい部分を選択しコピーしてください。コピーが終わったらclip2url.htaの「URL/メールアドレス 抽出」ボタンを押すと図1のように抽出結果が画面に出ます。
プログラムらしき部分は下記2点のプロシジャで実装しています。
chkCB()
Ar_unique(Src_ar)
SubプロシジャchkCB()は,「URL/メールアドレス 抽出」ボタンを押したときにonClickイベントで呼び出されます。URL/メールアドレスを抽出する基本ルーチンです。FunctionプロシジャであるAr_unique( )は,配列内の重複データを削除するプロシジャです。Ar_uniqueについては後述します。
クリップボードのデータはどうやって取得する?
クリップボードからデータを取得するのは簡単です。
'クリップボードの文字列を取得。
CB = clipboardData.getData("text")
("text")の部分が,クリップボード内のテキスト・フィールドを指定しています。getDataメソッド一発で,ここではCBという変数にクリップボード内容が取り込まれます。
取り込んだテキスト・データに対して,URLとメールアドレスの抽出には正規表現を使用します。処理の準備として正規表現オブジェクトを宣言します。
'正規表現オブジェクトの生成
Set RegEx = New RegExp
'大文字/小文字を区別しない
RegEx.IgnoreCase = True
'検索対象は文字列全体
RegEx.Global = True
今回はヒットした全件を抽出したいのでRegEx.Global = Trueです。最初の一件のみ抽出したい場合はRegEx.Global = Falseになります。
正規表現を使う準備が整ったので,実際の正規表現パターンを指定し検索実行します。URL抽出部分では下記のようになっています。
'正規表現パターン
RegEx.Pattern = "((http|https)://[\w,_,\.,/,\-]+)"
'URL検索
Set HitsURL = RegEx.Execute(CB)
メールアドレス部も正規表現パターンと配列名が違うだけで同じことをしています。結果は配列(上の例ではHitsURL)に取り込まれます。
サンプルのURLとメールアドレスに対する正規表現はきわめて単純なパターンです。正確に正しいURLやメールアドレスを抽出するには,もっとしっかりとした正規表現パターンを書かなくてはなりません。今回のような用途ではこれで問題なく抽出できてますから,今の段階ではよしとしておきましょう。
抽出結果のうち,メールアドレスはtextareaコントロールへ列記します。URLは抽出したものにリンクを張りたかったのでiframeに<A>タグ付で列記しています。textareaではリンクができませんからね。なおiframeへのテキストの追加ですが,これはJavaScriptでおなじみのdocument.writeを使います。FORMパーツにハイパーリンクを使えるコントロールがあればよかったのですが,そういう都合のいいものがないため,ちょっと力技になっている部分です。
扱いづらいVBScriptの配列
サンプルでは,重複した抽出データを削除するためにAr_unique( )というFunctionを作っています。実はVBScriptという言語は,どうにも配列操作に弱く,配列内のデータをソートしたり,重複データを削除するという内部関数を持っていません。配列に対して細かい操作をしたいという場合,すべて自作になります。
Ar_unique( )は抽出結果の配列から,一度先頭の要素と同じデータのものだけを排除した新しい配列を生成します(1回目のForループ)。この段階では2番目以降のデータは重複があるかもしれません。2回目のForループで,2番目以降のデータの重複を確認します。もし同一値があれば,本当ならばその値を配列からドロップしてしまいたいところですが,ここではNullに置き換えています。VBScriptでドロップ処理ができないからという単純な理由です。
これによって配列は次のように変化します。わかりやすく1から4の数値がデータだった場合で説明します。
重複確認前 1,2,3,2,4,3
重複確認後 1,2,3,Null,4,Null
重複を削除した配列から画面表示をする段階で,Nullだったら表示処理をスキップしているというわけです。
といっても,この配列の重複削除は決してスマートな方法ではありません。ぜひ皆さんの手で,もっと洗練されたものに変更してみてください。配列内ソートなども実装すればよりスマートになります。
プログラム拡張のためのヒント
では,このサンプルを拡張するヒントを紹介しておきましょう。
まず,せっかくVBScriptを使っているのですから,FileSystemObjectを使って,抽出結果をファイルに保存するという改良が考えられます。
次に,URL欄ではそのURLに対してのリンクを張っていますが,メール欄も同様に処理して
<a href="mailto:抽出結果">抽出結果</a>
とすれば,すぐにメールを送信できる形でのリストも作れます。
今回は抽出しやすいということを考えて,URLとメールアドレスをターゲットにしましたが,抽出判定は正規表現を使用しています。正規表現であるということは,例えば生のCSVファイルから,「カンマで数えて何個目のところにあるデータ」といった指定もできるということです。
いったんExcelで開いて該当列を探して,そこをコピーして新規ファイルに貼り付けて…といった煩雑な作業も,CSVファイルをエディタなどで開いておいて,Ctrl+A(すべて選択)からCtrl+C(コピー)して今回紹介したプログラムで抽出,みたいなことができるわけです。
クリップボード+正規表現というのは,ファイルフォーマットという制限を越えられるため,想像以上に改良の可能性があります。皆さんの想像力に期待します。
|



















































