「クラスタ・システムに高い期待を寄せるユーザーは多い」(伊藤忠テクノサイエンス プラットフォーム技術部 HA&Backup技術グループ グループリーダー 東智之氏)。ただし,期待通りのことが本当に実現できるのかどうかを理解していないと,予期せぬ不具合に遭遇する。クラスタ・システムを構築する上で,「クラスタ・ソフトは何をどうしてくれるのか」「どこが限界なのか」を,あらかじめ知る必要がある。
切り替え時間は5~15分
クラスタには大きく分けて2つの種類がある。一つは,負荷分散装置を使う方法で,サーバー間でデータの整合性を考慮する必要がないWebサーバーやAPサーバーの冗長化に有効だ。もう一つは,クラスタ・ソフトを使う方法である。いずれも,1台のサーバーに障害が発生したとき,他のサーバーが処理を肩代わりする。
 表1●主なクラスタ・ソフト [画像のクリックで拡大表示] |
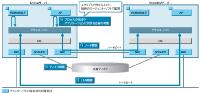 図3●クラスタ・ソフトでの障害検出 クラスタ・ソフトで障害を検出できるのは,主に(1)ノード障害,(2)ディスク障害,(3)LAN障害——である。(1)はハートビートを利用し,ハートビートが途絶えたらノード障害とみなす。(2)は結果としてアプリケーション障害になるため,サーバー切り替えの監視対象としない例もある。(4)プロセスの死活やアプリケーションに対する応答の有無を監視する場合は,ユーザーがスクリプトで作り込むか,別売の監視ソフトが必要になる [画像のクリックで拡大表示] |
クラスタ・ソフトは,複数台のサーバーに置いたデータに一貫性が必要なときに使う。主な用途はDBサーバーの冗長化である。「サーバーの切り替えに要する時間は5分~15分程度」(電通国際情報サービス プロダクトコンサルティング3部 グループマネージャー 芝田潤氏)なので,ダウンタイムを比較的短時間に抑えられる。クラスタ・ソフトは,サーバー・メーカーやデータベース・ベンダーなどから提供されている(表1[拡大表示])。以下,Active/Standby型のクラスタ・システムを前提に説明する。
基本はハードの障害対応
クラスタ・ソフトは,「基本的にハードウエア故障によるサーバー障害を検出し,サーバーを切り替えるもの」(日本HP 松野氏)である。実際,「CPUパニックの際にうまく切り替わった」(DeNA 茂岩氏),「LANカードの障害時にうまく切り替わった」(楽天トラベル 金住氏)など,ハードウエア障害に対しては期待通りに動作してくれることが多い。
クラスタ・ソフトの基本的な障害監視方法は,サーバー間をつなぐ専用のインターコネクト(イーサネットやRS-232-C)を通じて「ハートビート*3」を数十秒~数分おきに送受信し,各サーバーの死活を監視するものである(図3[拡大表示])。例えば,Active側が送信するハートビートをStandby側で受信できなくなったら,Active側に何らかの障害が起きたとみなしてStandbyが始動する。
ただし,ハートビートが途切れたからといって,Active側が本当にダウンしているとは限らない。インターコネクトのケーブルが抜けているだけかもしれないからだ。仮にインターコネクトのケーブルが抜けただけだったとしたら,クラスタを構成する2台のサーバーが相互に「相手がダウンした」と勘違いする。両方がActive状態になり,共有ディスクの内容に不整合が起こりかねない。
この手の問題が起こらないように,クラスタ・ソフトの多くは回避策を用意している。ハートビートが途切れたときに,ディスクの特定領域を先につかんだ(ロックした)サーバーだけが生き残る仕組みだ。つかめなかった方のサーバーは,「OSにパニックを起こさせて強制的にダウンさせる」(サン・マイクロシステムズ クライアント・エンゲージメント&デリバリー本部 パートナー第三技術統括部 第一技術部 エンゲージメントアーキテクト 大林克至氏)。
インターコネクト上のハートビートでサーバー本体の異常を検知できるほか,共有ディスクやLANカードへのハートビートにより,当該個所の障害も検出可能である。LANカードに障害があった場合,まずは同一サーバー内に用意した予備のLANカードに切り替える。それでもうまくいかない場合にサーバーを切り替える。Standbyに切り替える場合,手順に従ってActive側でアプリケーションを終了させ,共有ディスクやIPアドレスを解放する。その後,Standby側でIPアドレスや共有ディスクを引き継いで,RDBMSやアプリケーションを起動する。サーバー本体が故障したときと違って,Active側のサーバーを強制的に落とすことはしない。
共有ディスク周りの不具合が多い
ここまでの範囲なら,クラスタ・ソフトが障害にうまく対処してくれるはずである。ただし,ハードウエア的な障害でもうまく切り替えられないケースはある。特に,「共有ディスクに関する不具合がトラブルの原因になることが多い」と伊藤忠テクノサイエンスの東氏は指摘する。
同社が構築した,ある通信キャリアのシステムでは,Standbyサーバーと共有ディスクの通信経路に問題があり,切り替わった後にディスクを認識できないトラブルがあった。「通常時,Standbyはディスクをマウントしていないため,切り替わって初めて分かる障害だった」(同氏)。
日立情報システムズが運用する,ある損害保険会社の代理店向けシステムでは,障害が起こったActiveを復旧した後,Standbyから切り替え直す際に,ActiveとStandbyの両方が立ち上がらなくなった。「切り替え直す際に,共有ディスクのミラーリング機能に異常が発生し,そこで処理が止まっていた」(第一システム本部 第二設計部 第6グループ 主任技師 治田則男氏)。
これらは,Active/Standby型でディスクを共有する限り起こり得る問題だ。この問題を改善するには,ディスクを共有しないクラスタ・システム(後述のレプリケーション型システム)などを検討する必要がある。



















































