前回,前々回と,Yahoo! ウェブ検索Webサービスを利用するサンプルを通じて,AjaxでXMLデータを利用する方法について紹介しました。XMLを利用することで,サイト検索結果のような複合的な情報(構造化データ)を,使用するプラットフォームを意識することなく,やり取りできます。前回,XMLデータをクライアントサイドで受け取れることを確認したところで,今回はより詳らかにXMLデータ読み込みの部分を見ていくことにしましょう。
XML操作の標準API「Document Object Model」
DOM(Document Object Model)とは,その名の通り,XML文書内に登場するタグや属性,テキストといった構成要素を汎用的に操作するためのオブジェクト群のことを言います。DOMを利用することで,与えられたXML文書から必要な情報を取り出したり,データを編集/追加/削除したり,といった操作が可能になります。前回登場したDOMDocumentオブジェクト(XML文書)も,DOMが提供するオブジェクトの一つです。
DOMを利用するうえでは,まず「ノード(node)」という言葉を理解しておく必要があります。ノードとは,XML文書を構成する最小の単位だと思っておけばよいでしょう。XML文書内に登場するタグ(要素),属性,テキスト,コメント…などすべての構成要素は,ノードと見なされます。DOMでは最初にXML文書全体を読み込み,ノード間の階層構造をツリー構造としてメモリー上に展開します。例えば,前回,前々回と説明したYahoo! ウェブ検索Webサービスから返された結果XMLは,内部的には以下のようなツリー構造として展開されます(図1) 。
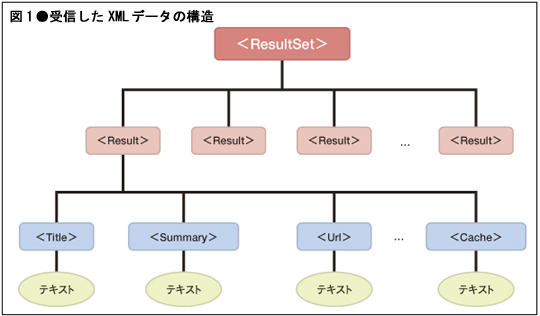
これによって,文書ツリー上の特定のノード(情報)を取り出したり,あるいは,文書ツリーの一部分(部分ツリー)を置き換え/削除したり,はたまた,文書ツリーに新たな情報を追加したり,といった柔軟な操作が可能になるわけです。DOMは実に膨大な仕様を提供しており,そのすべてを紹介することはできません。本稿ではAjaxプログラミングで頻繁に利用すると思われる参照系の機能を,前回紹介したコードに沿って見ていきます。より詳細については,拙著「10日でおぼえるXML入門教室」(翔泳社)や「基礎XML」(インプレス)などの専門書を参照してください。
ルート要素を取得する
以下に,前回のクライアントサイドのプログラムからXMLデータを処理する部分を再掲します(リスト1)。このコードでXMLの各ノード・データをどのように読み取っているのかを見ていきましょう。
リスト1●クライアントサイドでXML文書の処理をしている部分のJavaScriptのコード(yahoo.htmlの一部)
~ 略 ~
// サーバーからの応答時の処理を定義(結果をページへ反映)
xmlReq.onreadystatechange = function() {
var msg = document.getElementById("result");
if (xmlReq.readyState == 4) {
if (xmlReq.status == 200) {
var ctt="";
var xmldoc=xmlReq.responseXML.documentElement; // … (1)
var nodes=xmldoc.childNodes; // … (2)
if(nodes.length==0){ // … (3)
ctt="お探しのサイトは見つかりませんでした。";
} else {
for (i =0; i < nodes.length; i++) {
var node=nodes.item(i); // … (4)
ctt += "<li><a target='_blank' href='" // … (5)
+ getNodeValue(node, "Url") + "'>"
+ getNodeValue(node, "Title") + "</a></li>"
}
}
msg.innerHTML=ctt;
~ 略 ~
}
}
~ 略 ~
// ノードcurrent配下に含まれる要素nameのテキスト値を取得する関数
function getNodeValue(current ,name){
var nodes=current.getElementsByTagName(name);
var node=nodes.item(0);
var txtNode=node.firstChild;
return txtNode.nodeValue;
}
~ 略 ~
|
XML文書の読み取りにはいくつかのアプローチがあります。その代表的なアプローチが「ノードウォーキング」と呼ばれるものです。ノードウォーキングとは,ツリー構造になったXML文書の最上位ノードから下位ノードに向かって順に辿っていく方法のことを言います。ノードウォーキングを行う場合の操作の基点となるのが「ルート要素」です。
ルート要素とは,その名の通り,文書ツリーの根っこ??ツリーのように広がった文書階層を束ねる最上位の要素のことを言います。図1では<ResultSet>要素のことです。ルート要素を取得するには,documentElementプロパティを使用します。リスト1では(1)の部分のコードが該当します。
var xmldoc=xmlReq.responseXML.documentElement;
子ノード群を取得する
図1を見てもわかるように,ルート要素は文書内の全ノードを含んでいます。下位ノードに辿っていく次のステップとして,今度はルート要素直下の子ノード群を取得してみましょう。リスト1では,(2)の部分に当たります。
var nodes=xmldoc.childNodes;
childNodesプロパティは,現在のノード(この場合はルート要素)配下の子ノード群をDOMNodeListオブジェクトとして返します*1。DOMNodeListオブジェクトは,0個以上のDOMNodeオブジェクト(ノード)を含むリストで,図1の場合は,<ResultSet>要素配下の一連の%lt;Result>要素群を表します。リスト1の(3)では,DOMNodeList.lengthプロパティでリスト内のノード数を参照し,0である場合には結果がなかったことをメッセージ表示し,1以上であった場合にだけ個々のノードを取得する処理を行います。
if(nodes.length==0){
ctt="お探しのサイトは見つかりませんでした。";
} else {
/* 個々のノードを取得する処理 */
}
個々のノードを取得する
DOMNodeListオブジェクトから個々のノードを取得しているのは,リスト1の(4)のコードです。
for (i =0; i < nodes.length; i++) {
var node=nodes.item(i);
~ 略 ~
}
itemプロパティは引数に指定されたインデックス番号に対応するノードをDOMNodeオブジェクトとして返します。つまり,このforループでは「0 ~ ノード数?1」番目まで繰り返すことで,リストに含まれるすべてのノードを一つずつ取り出しているというわけです(リストのインデックス番号は0がスタート点であることに注意してください)。
要素ノードにダイレクトアクセスする
ここまでの操作で,ルート要素配下の個々のノード(ここでは<Result>要素)が取得できました。ここからさらに配下の<Title>,<Url>要素にアクセスします。そのための方法としてchildNodesプロパティを使用しても(もちろん)構いませんが,ここではノードウォーキングと並んでよく使われる「ダイレクトアクセス」によって,以下のノードにアクセスしてみましょう。
ノードウォーキングが上位のノードから順に下位のノードへたどっていく手法であるのに対して,ダイレクトアクセスは指定された要素名やID値などをキーとして該当するノードに直接アクセスします。手軽である半面,対象の文書ツリーが大きい場合にはパフォーマンスが悪化する原因にもなりますので,注意が必要です。
一般的には,今回の例のように,まずノードウォーキングで対象のツリーを絞り込んだうえで,個々のノードへのアクセスはダイレクトアクセスを用いるなど,両者を併用するのが好ましいでしょう。
リスト1でダイレクトアクセスを行っているのは,(5)の部分です。
ctt += "<li><a target='_blank' href='" + getNodeValue(node, "Url") + "'>"
+ getNodeValue(node, "Title") + "</a></li>";
同じようなコードを何度も記述するのは好ましくありませんので,本稿ではダイレクトアクセスの部分をgetNodeValueというユーザー定義関数として別個に定義しています。getNodeValue関数は,引数として検索対象のノード(DOMNodeオブジェクト)と取得したい要素の名前を受け取り,戻り値として指定要素配下のテキストを返します。なお,getNodeValue関数は,対象ノードの配下に同名の要素が複数あった場合には,最初の要素に含まれるテキストのみを返すものとします。
function getNodeValue(current ,name){
var nodes=current.getElementsByTagName(name);
var node=nodes.item(0);
var txtNode=node.firstChild;
return txtNode.nodeValue;
}
getElementsByTagNameメソッドは現在のノード(current)配下を指定されたタグ名(name)で検索し,合致した要素群をDOMNodeListオブジェクトとして返します。ここでは常に合致する要素が一つしかないことを前提としますので,DOMNodeListオブジェクトから0番目のノードを取得しておきます。これで,(例えば)引数に指定された<Url>,<Title>要素を取得できます。
テキスト・ノードを取得する
DOMを利用する場合,間違えやすい点の一つとして,要素配下のテキストは「要素ノードの値ではなく,要素ノード配下のテキスト・ノードの値である」という点が挙げられます。つまり,要素配下のテキストを取得するには,まず先ほど取得した要素ノードからテキスト・ノードを取り出す必要があります。getNodeValue関数の以下の部分に注目してみましょう。
var txtNode=node.firstChild; return txtNode.nodeValue;
要素配下のテキスト・ノードを取得する場合,先ほどのchildNodesプロパティを使用しても構いませんが,それではコードが無用に冗長になってしまいます。配下にノードが一つしかないことがあらかじめわかっている場合には,firstChildプロパティを利用すると便利です。
firstChildプロパティを利用すると,現在のノード配下の最初の子ノードを取得できます。ちなみに,firstChildプロパティ同様,DOMには相対的な位置関係でノードを取得するための様々なプロパティが用意されています。図2に主要なものをまとめておきます。
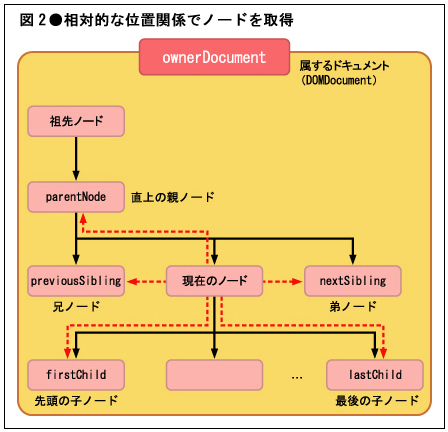
これでテキスト・ノードが取得できました。あとはnodeValueプロパティでテキスト・ノードの値を取得するだけです。ちなみに,ノードの情報を取得するプロパティにはnodeValueプロパティのほかにも,表1のようなものがあります。
| 表1●ノード情報取得のための主要なプロパティ(DOMNodeオブジェクト) | |
| プロパティ | 概要 |
|---|---|
| nodeName | ノード名 |
| nodeValue | ノード値 |
| prefix | 名前空間プレフィックス |
| namespaceURI | 名前空間URI |
| nodeName | ノード名 |
以上,DOMによるXML文書読み取りの基本的な手法について学習してきました。繰り返しですが,DOMそのものは実に膨大な仕様を提供しており,とてもこの場だけですべてを語りつくせるものではありません。本稿では紹介できなかった重要な機能もまだまだありますので,余力のある方は,前述の参考書籍なども合わせて参照することをお勧めします。
*1 ちなみに子ノードには属性は含まれません。要素に含まれる属性値にアクセスするには,以下のようなコードを記述してください。
xmldoc.getAttribute("totalResultsReturned")
これによって,現在の要素(この場合は<ResultSet>要素)配下のtotalResultsReturned属性の値を取得できます。
| 山田祥寛(やまだ よしひろ) Microsoft MVP for ASP/ASP .NET。執筆コミュニティ「WINGSプロジェクト」の代表でもある。主な近著に「XMLデータベース入門」「PEAR入門」「Smarty入門」「10日でおぼえる入門教室シリーズ(Jakarta・JSP/サーブレット・PHP・XML)」(以上,翔泳社),「今日からつかえるサンプル集シリーズ(JSP&サーブレット・PHP5・ASP・XML)」(以上,秀和システム),「書き込み式 SQLのドリル」(ソシム),「JSP/PHP/ASPサーバーサイドプログラミング徹底比較」(技術評論社)など。最近では,IT関連技術の取材,講演,監修まで広く手がける毎日。 |



















































